本文主要是介绍商品销售数据爬取分析可视化系统 爬虫+机器学习 淘宝销售数据 预测算法模型 大屏 大数据毕业设计(附源码)✅,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
python语言、Django框架、Vue前端框架、机器学习预测算法(线性回归模型预测商品的销量)
MySQL数据库、selenium爬虫技术、Echarts可视化、淘宝商品数据
商品销售数据爬取分析可视化系统 大数据 毕业设计 爬虫+机器学习 淘宝销售数据 预测算法模型 大屏
商品销售数据爬取分析可视化预测系统是一个基于Python语言和Django框架开发的应用程序。它通过使用selenium爬虫技术从淘宝网上获取商品的销售数据,并使用MySQL数据库存储这些数据。
2、项目界面
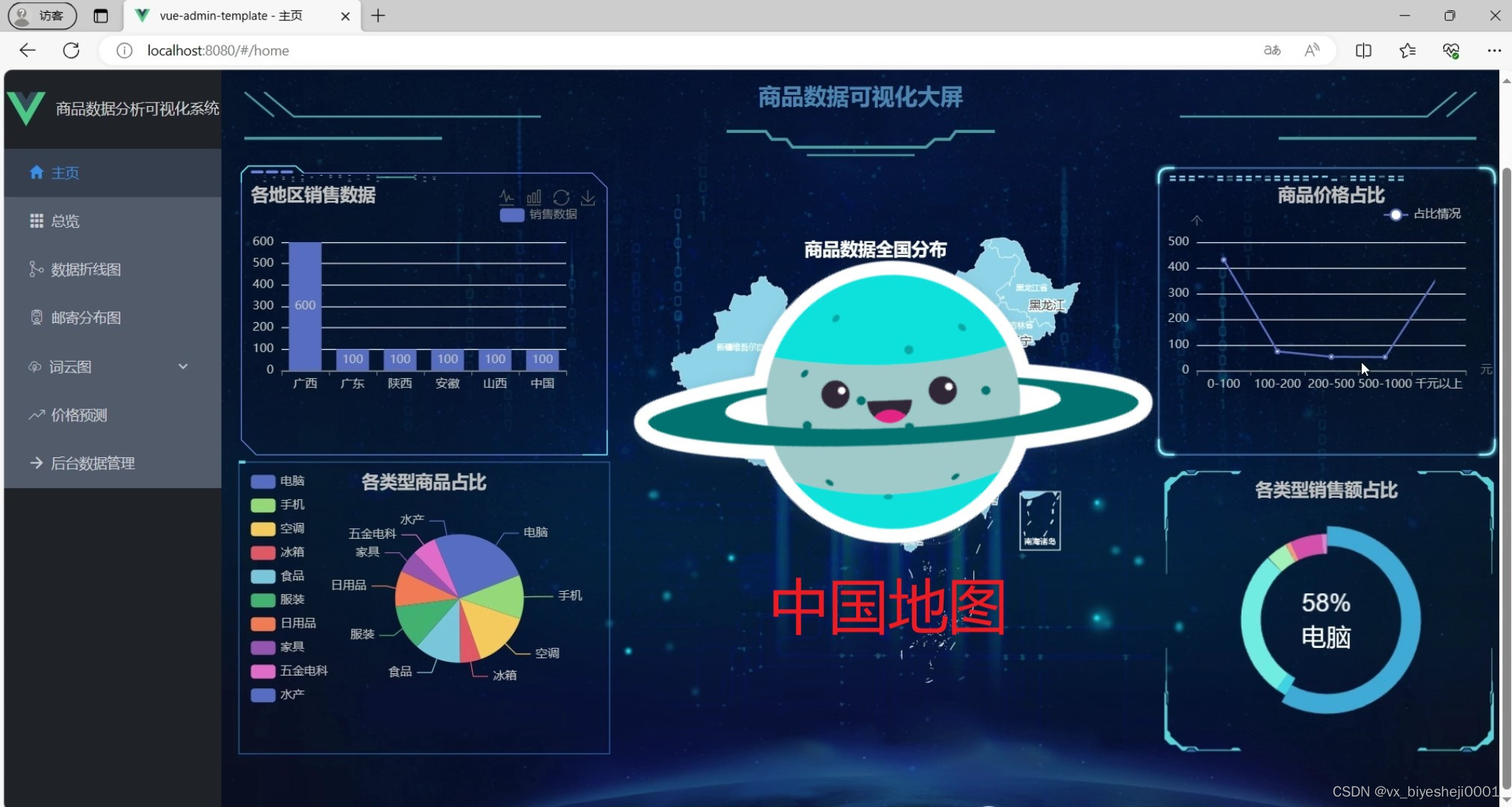
(1)商品数据可视化大屏
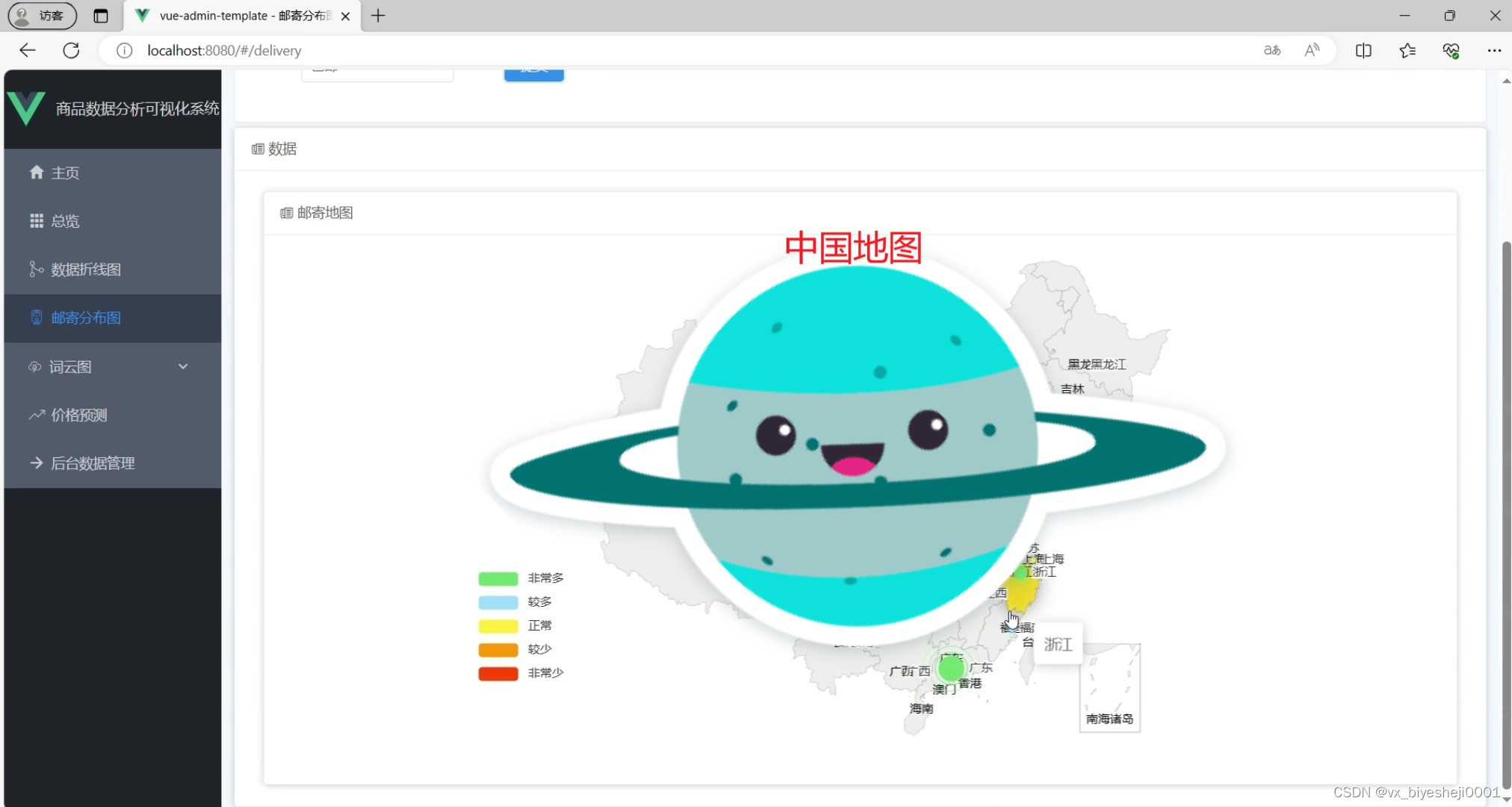
(2)邮寄中国分布图
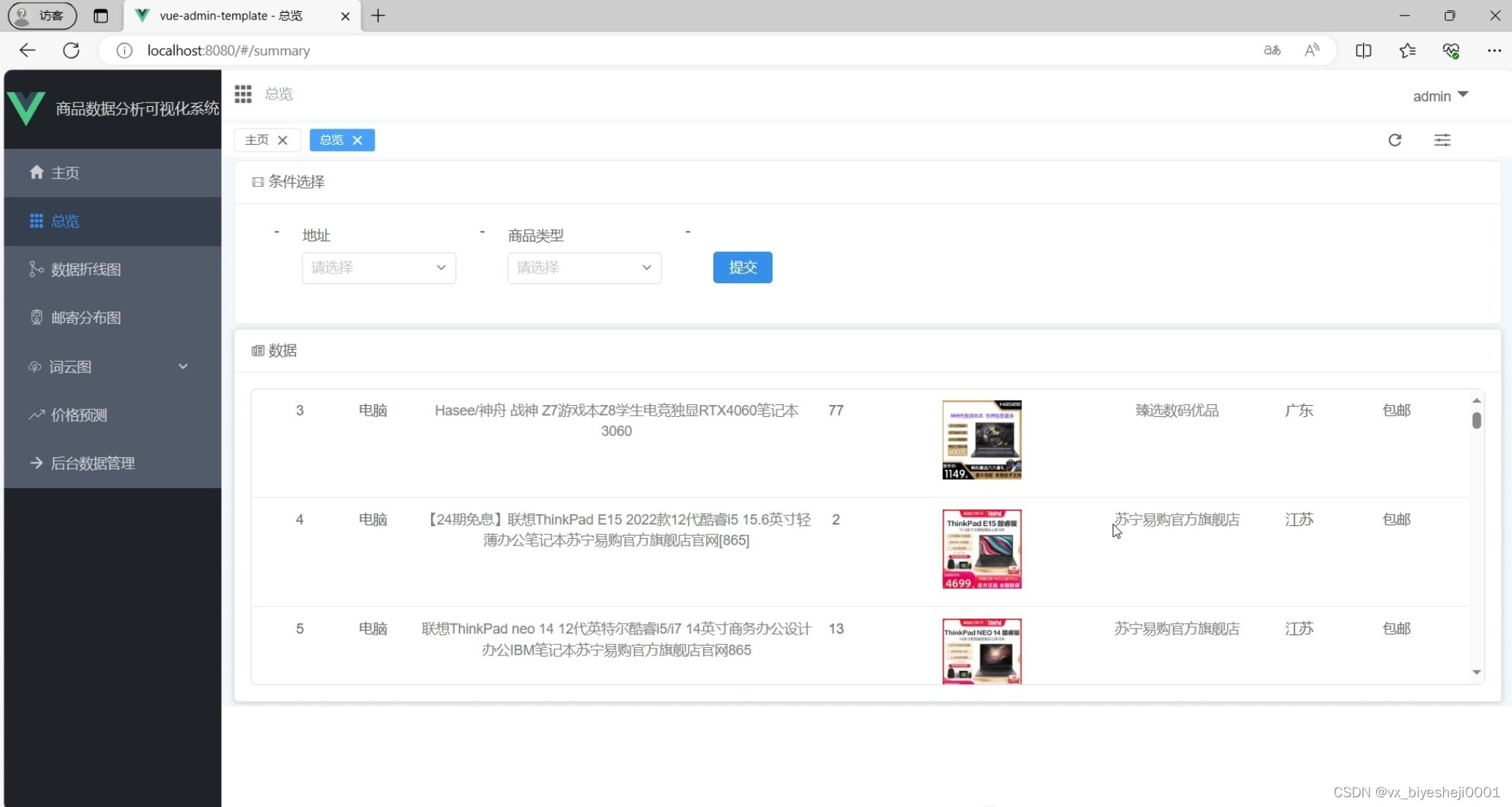
(3)商品数据详情
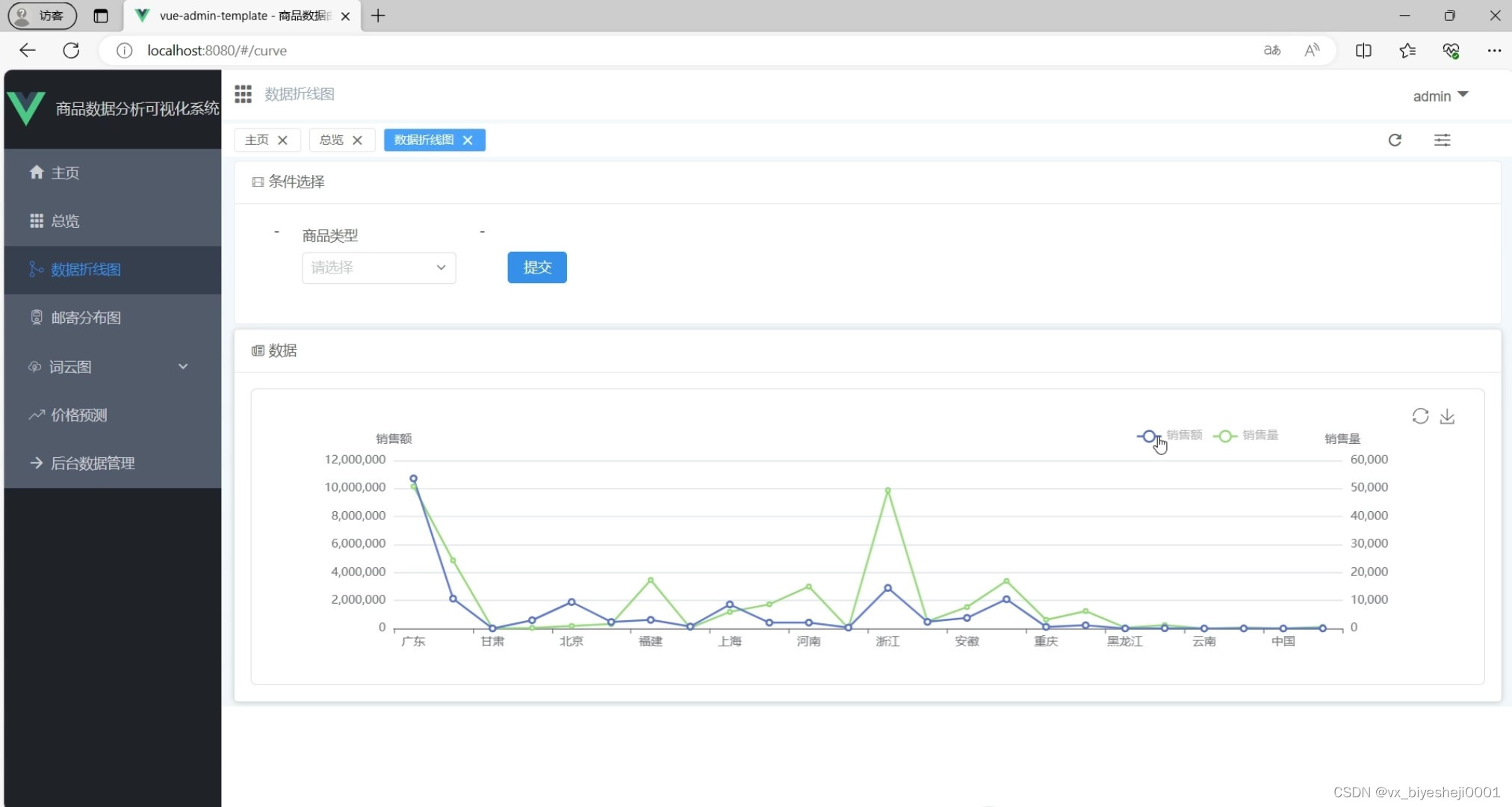
(4)商品各类型各省份销售额、销售量数据折线图
(5)词云图分析
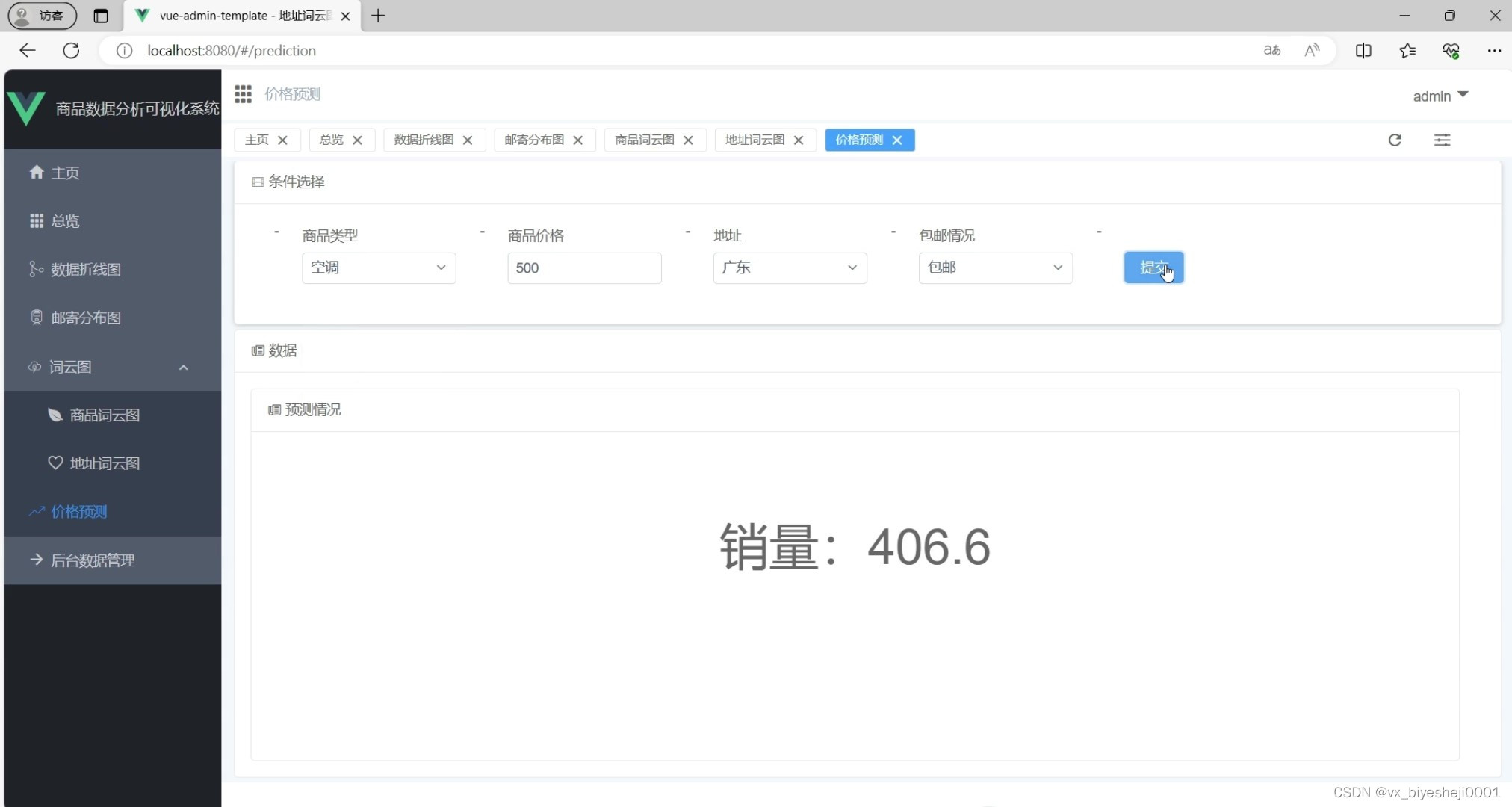
(6)机器学习算法预测(线性回归模型预测商品的销量)
(7)后台数据管理
3、项目说明
商品销售数据爬取分析可视化预测系统是一个基于Python语言和Django框架开发的应用程序。它通过使用selenium爬虫技术从淘宝网上获取商品的销售数据,并使用MySQL数据库存储这些数据。
系统的前端界面使用了Vue前端框架,可以实现用户与系统的交互操作。用户可以通过系统界面输入要查询的商品信息,并选择相应的时间范围来获取该商品的销售数据。
系统使用机器学习预测算法(线性回归模型)来对商品的销量进行预测。通过对历史销售数据的分析和建模,系统可以根据当前的销售情况预测未来一段时间内的商品销量。
为了更直观地展示数据,系统使用了Echarts可视化库来生成各种图表和图形。用户可以通过系统界面查看商品销售数据的趋势图、柱状图、饼图等,以便更好地分析和理解数据。
总之,商品销售数据爬取分析可视化预测系统能够帮助用户方便地获取商品销售数据、分析趋势,并通过机器学习算法预测商品的销量,从而为用户提供决策参考。
4、核心代码
from django.shortcuts import render
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt# Create your views here.
from .utils import getScreenData
from .utils import getSummaryData
from .utils import getCurveData
from .utils import getDeliveryData
from .utils import getPreData
from .machine import predication
from myApp.models import *
@csrf_exempt
def screenData(request):if request.method == 'GET':cityList,volumnList = getScreenData.getSquareData()pieList = getScreenData.getPieDatta()mapData = getScreenData.getMapData()LineRowData,LineColData = getScreenData.getLineData()circlieList = getScreenData.getCircleData()return JsonResponse({'cityList':cityList,'volumnList':volumnList,'pieList':pieList,'mapData':mapData,'LineRowData':LineRowData,'LineColData':LineColData,'circlieList':circlieList})def summary(request):if request.method == 'GET':goodsCity,goodsType = getSummaryData.getChangeList()defaultCity = '不限'defaultType = '不限'if request.GET.get('city'): defaultCity = request.GET.get('city')if request.GET.get('type'): defaultType = request.GET.get('type')print(defaultCity,defaultType)goodsData = getSummaryData.getSummary(defaultCity,defaultType)return JsonResponse({'goodsCity':goodsCity,'goodsType':goodsType,'goodsData':goodsData})def curve(request):if request.method == 'GET':goodsType = getCurveData.getChangeList()defaultType = '不限'if request.GET.get('list'): defaultType = request.GET.get('list')RowList,OneColList,TwoColList = getCurveData.getRealData(defaultType)print(defaultType)return JsonResponse({'goodsType':goodsType,'RowList':RowList,'OneColList':OneColList,'TwoColList':TwoColList})def delivery(request):if request.method == 'GET':defaultDelivery = '不限'diliveryList = getDeliveryData.getChangeList()if request.GET.get('list'): defaultDelivery = request.GET.get('list')print(defaultDelivery)mapData = getDeliveryData.getGeoData(defaultDelivery)return JsonResponse({'diliveryList':diliveryList,'mapData':mapData})def predictionData(request):if request.method == 'GET':typeList,addressList,deliveryList = getPreData.getListData()type = ''price = 0address = ''delivery = ''if request.GET.get('type'): type = request.GET.get('type')if request.GET.get('price'): price = int(request.GET.get('price'))if request.GET.get('address'): address = request.GET.get('address')if request.GET.get('delivery'): delivery = request.GET.get('delivery')print(type,price,address,delivery)preVolumn = ''if type and price and address and delivery:trainData = predication.getData()model = predication.model_train(trainData)preVolumn = predication.pred(model,type,price,address,delivery)print(preVolumn)return JsonResponse({'typeList':typeList,'addressList':addressList,'deliveryList':deliveryList,'preVolumn':preVolumn})@csrf_exempt
def login(request):if request.method == 'POST':uname = request.POST.get('username')pwd = request.POST.get('password')message = ''print(uname,pwd)try:user = User.objects.get(username=uname,password=pwd)print(user)message = '登录成功'print(message)return JsonResponse({'username':uname,'message': message})except:print(1)return JsonResponse({'message': '登录失败'})
@csrf_exempt
def register(request):if request.method == 'POST':uname = request.POST.get('username')pwd = request.POST.get('password')message = ''print(uname,pwd)try:User.objects.get(username=uname)message = '账号已存在'except:if not uname or not pwd:message = '不允许为空'else:User.objects.create(username=uname,password=pwd)return JsonResponse({'message': message})5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻
这篇关于商品销售数据爬取分析可视化系统 爬虫+机器学习 淘宝销售数据 预测算法模型 大屏 大数据毕业设计(附源码)✅的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








