本文主要是介绍MSCNN论文解读-A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多尺度深度卷积神经网络进行快速目标检测:
两阶段目标检测器,与faster-rcnn相似,分为an object proposal network and an accurate detection network. 文章主要解决的是目标大小不一致的问题,尤其是对小目标的检测,通过多层次的结构,实现多尺度的目标检测。
之前所使用的简单的单一尺度的目标检测器通常为了识别出图片中大小适中的目标而将感受野设定为一个适当的大小,这种设定对于较大或较小的目标的识别效果都比较差。通常解决小目标的识别是通过将输入图片进行上采样的方法,但是这种方法所消耗的内存和计算量都很大,所以本篇文章所采用的多尺度目标检测器能够解决这种目标大小与感受野不一致的现象,每一个检测层只着重检测与这一层尺寸相匹配的目标。换句话说,就是在网络的浅层检测小目标,在深层检测大目标。

文章第二个贡献在于利用特征上采样代替输入图片上采样,扩大小目标的分辨率,提高识别准确率。这一部分是利用一个反卷积层实现,采用的方法是双线性插值的方法,减少了内存和计算的消耗。
第三部分是目标检测网络的第一个阶段-生成候选框的子网络(Multi-scale Object Proposal Network )。这一部分分三个主要部分。
3.1多尺度检测
多尺度检测分为两种方法:(1)利用一个单一尺度的分类器并将输入图片多次重新缩放成不同比例进行检测,使分类器能够与所有尺寸的目标相匹配。(2)利用卷积神经网络特征的复杂性。本文采用的是一个多尺度的检测方法,在卷积过程中的多个卷积层中进行检测,但是输入采用单一尺度的图片,并且每个检测层只检测固定尺寸大小的图片。
3.2架构
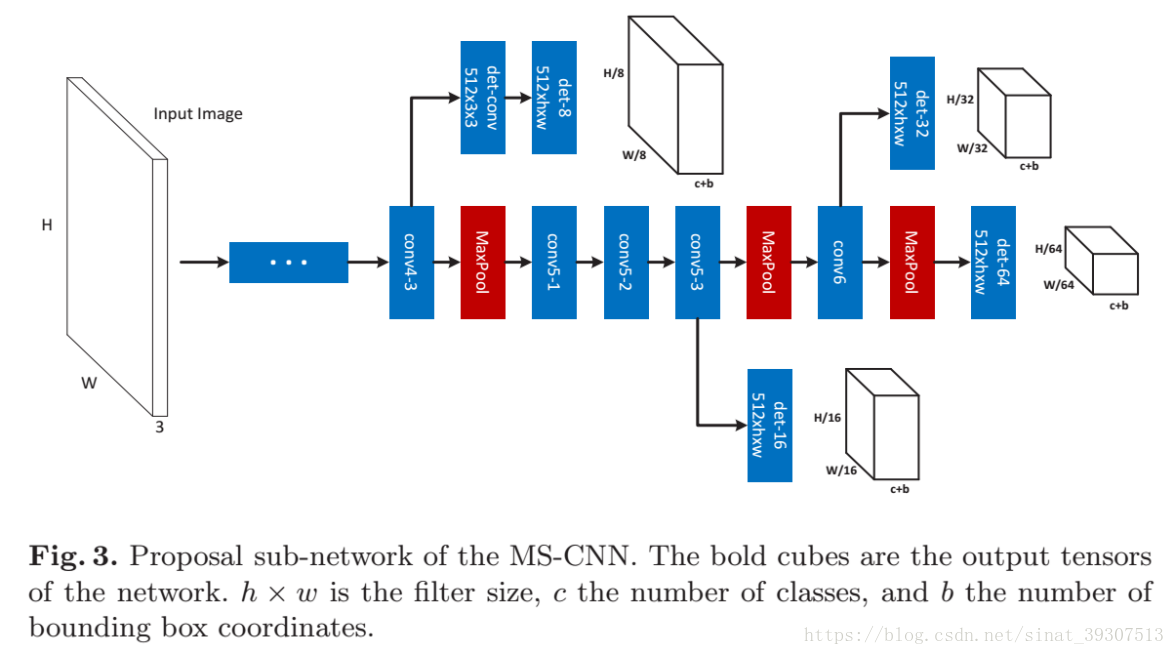
文章中的MS-CNN proposal network如图三所示,图像中间是网络的主干,同时在一些卷积层中带有分支结构。其中每个分支都是一个单一尺度的目标检测器。注意在第4-3个卷积层后带有一个缓冲层,是为了防止低层次卷积层在反向传播过程中影响主干网络的梯度。
整个proposal network子网络的损失用W来表示,S是训练目标的一个集合。其中整体的损失数由公式(1)进行计算,是将每一个检测层的损失叠加在一起作为整体损失,损失的计算与faster r-cnn相似,分别计算分类损失和回归损失。分类采用对数损失,回归采用SMOOTH-L1损失。
3.3采样
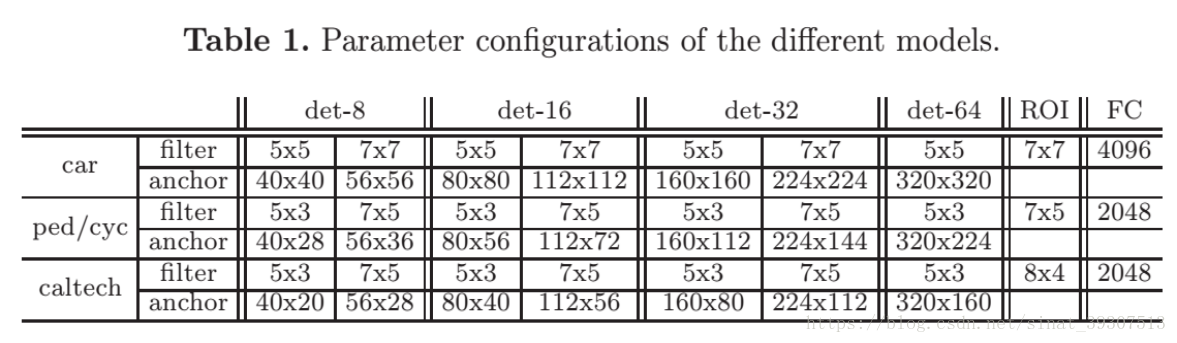
对于每一个检测层训练样本都分为正、负样本。其中候选框是通过一个Anchor作为滑动窗口的中心,在特征映射上滑动产生的。Anchor的大小设置与卷积核的大小相关,并且不同检测层的大小设置也不同,具体设置如表一所示。当候选框与真实样本的IOU值大于等于0.5时,被标记为正样本,当IOU值小于0.2时被标记为负样本,其余的丢弃。
但是对于一张自然图片,目标与非目标的比例通常不匹配。采样就是要解决这种正负样本不平衡的现象,通常是对负样本进行采样,文中介绍了三种方法分别为:(1)随机采样,即随机的选取负样本。(2)自定义方法,文中是将所有负样本按照分数进行排名,选取前n个强负样本。(3)混合方法,一半采用随机采样,一半采用按分数排名。
为了保证每一个检测层只检测这一层次所对应尺度的目标,在训练样本中,这一层次的训练样本必须包含所对应范围内的所有尺寸。那么就可能会出现一个检测层中没有正样本的出现,导致正负样本比例失调,使学习的模型不稳定,所以在计算分类损失时将检测到的正负样本乘以不同的系数一减少负样本对整体的影响。
第四部分是目标检测子网络的介绍,在加入检测子网络后,整个网络的损失通过公式(6)进行计算,前一部分为候选框子网络的损失,后一部分为检测子网络的损失。其中检测子网络的损失计算公式与faster r-cnn相似,M+1为M个类别和一个背景。第四部分分为两个主要部分:
4.1 cnn特征值插图
在第4-3个卷积层后通过反卷积加入一个卷积层,实现特征映射的上采样,对于小目标的识别更加准确。
4.2上下文嵌入
如图绿色框代表检测到的目标候选框,蓝色框为带有该目标的上下文信息的候选框,其中蓝色框为绿色框的1.5倍,通过将这两个框进行堆叠,在通过一个降维卷积层将冗余的信息进行压缩,在不损失准确率的情况下减少了参数。
这篇关于MSCNN论文解读-A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





