本文主要是介绍基于paddlepaddle的FPS最远点采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是FPS最远点采样?
最远点采样(Farthest Point Sampling,FPS)是一种常用的采样算法,主要用于点云数据(如激光雷达点云数据、分子坐标等)的采样。
为了方便解释,定义一下待采样点到采样点的“距离”为待采样点到所有采样点的距离的最小值。
这种算法的核心思想是,一开始先从数据集中随机采样一个点,然后采样距离采样点最远的待采样点作为下一个采样点,以此类推,直到达到所需的采样点数量。通过这种方式,最远点采样能够保证对样本的均匀采样。
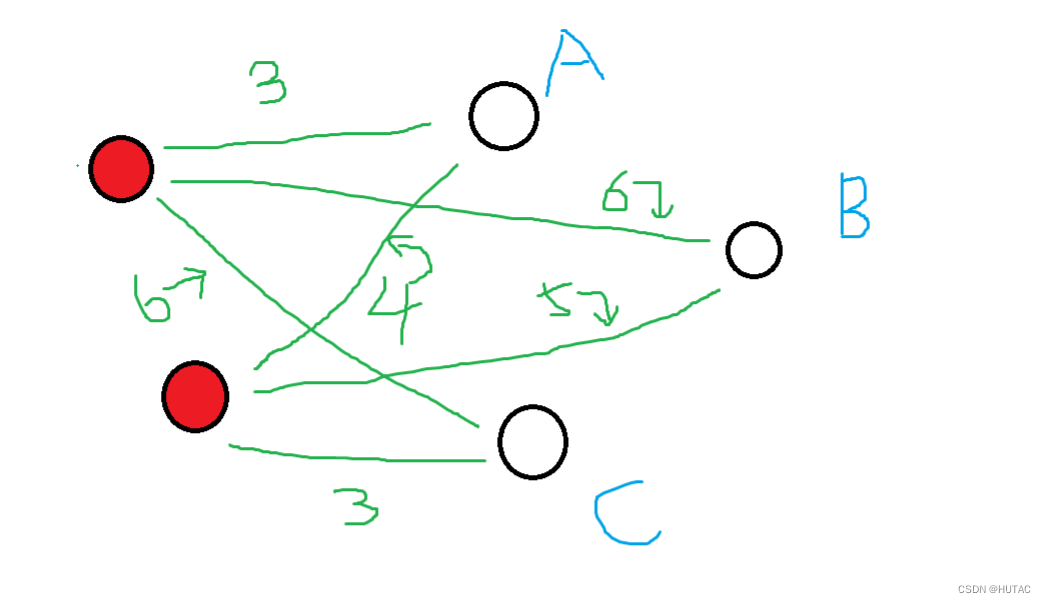
例如下图,红点都是采样点,白点都是待采样点,如果此时还没有达到所需的采样点数量,那么就会采样B点。因为A到采样点的距离为min(3,4)=3,B到采样点的距离为min(6,5)=5,C到采样点的距离为min(6,3)=3,在其中点B的距离是最远的。
怎么实现FPS最远点采样?
解释都在代码注释里。
import paddledef farthest_point_sample(xyz, npoint):"""Input:xyz: pointcloud data, [B, N, 3]B: batch 批次数N: 一批次点的数量3: 代表x,y,z轴三个通道npoint: number of samples 需要采样点的个数Return:centroids: sampled pointcloud index, [B, npoint]返回的是采样点的索引"""B, N, C = xyz.shape# 获取点云的 batch, 点数, 通道数# B*N = xzy所存储的所有的点# 可以形象地理解xyz为 B张二维表格里面存储的都是点坐标centroids = paddle.zeros([B, npoint])# centroids用来保存采样点的索引下标 初始全部为0# 可以形象地理解为一张二维表格 有B行 npoint列# 表里面每个单元格代表的意思是 B batch下 最远点的索引distance = paddle.ones([B, N])*1e10# 一开始初始化要大# 存储所有点到当前采样点的距离# 可以形象地理解为一张二维表格 有B行 N列# 表里面每个单元格代表的意思是 B batch下 第N个点距离采样点的距离farthest = paddle.randint(0, N, (B,))# 一开始先随机生成采样点# 用于存储当前batch批次中距离已采样点最远的点的索引。batch_indices = paddle.arange(B)# 一个从0到B-1的整数序列,代表批次的索引。for i in range(npoint):# 代表进行n次点的采样 for n 次centroids[:, i] = farthest# 更新表的第i列 用于记录每个batch下的第i个最远点的索引xyz_np = xyz.numpy()# 获取到所有点的坐标batch_indices_np = batch_indices.numpy().astype('int64')# 获取到batch批次的索引farthest_np = farthest.numpy().astype('int64')# 获取到不同批次的采样点的索引centroid = xyz_np[batch_indices_np, farthest_np, :]# 获取到不同批次下的采样点的坐标# shape = [b,1000 ,3]centroid = paddle.to_tensor(centroid).unsqueeze(1)# todo 笔记# shape = [b, 1 ,1000, 3]dist = paddle.sum((xyz - centroid) ** 2, -1)# todo 笔记# 计算所有点到采样点的距离 -1代表在最后一个维度进行相加mask = dist < distance# todo 笔记# mask 为tensor bool[……]# dist 保存的是待采样点到 前一个采样点的距离# distance 保存的是 待采样点到 其他采样点的距离(除了前一个采样点)# 有多个采样点时, 其余点到采样点的距离应该取最小值# 例如 A B 为采样点 C为其余点 AC距离为5 BC距离为3 则采用3 不用5distance_np = distance.numpy()dist_np = dist.numpy()mask_np = mask.numpy()distance_np[mask_np] = dist_np[mask_np]# todo 笔记# 只有mask_np 为True时才会 替换 也就是 dist更小时才会替换# 确保里面都是最小值distance = paddle.to_tensor(distance_np)farthest = paddle.argmax(distance, -1)# -1 代表在最后一个维度找最大值并返回索引return centroids这篇关于基于paddlepaddle的FPS最远点采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!