本文主要是介绍MoDS: Model-oriented Data Selection for Instruction Tuning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要用于记录学习的过程,如有理解错误的请指正。
该论文主要通过模型驱动,实现自动筛选高质量的Instruction tuning数据选取,实现大模型的能够和人类的意图进行对齐。
摘要:
一些论文证明Instruction tuning证明只需要很少的数据集就可以实现与人类意图对齐,并且大模型LLM并不能从Instruction tuning中学到东西,仅仅是生成一些可靠的格式。该论文提出通过模型,自动化选取一些少量并且高质量的数据。论文中认为从三个方面,Instruction tuning数据质量、多样性,以及必要性三个方面进行Instruction tuning数据的选取。
- 对于数据质量:质量要求所选的指令数据对问题和答案都足够好。
- 对于数据多样性:覆盖范围要求所选指令数据足够多样化。
- 对于数据的必要性:必要性表明所选的指令数据确实填补了感兴趣的LLM的能力空白。
正文:
对于模型的设计,数据选择模型的设计从数据质量、多样性、必要性三个方面进行设计,模型结构图如下:
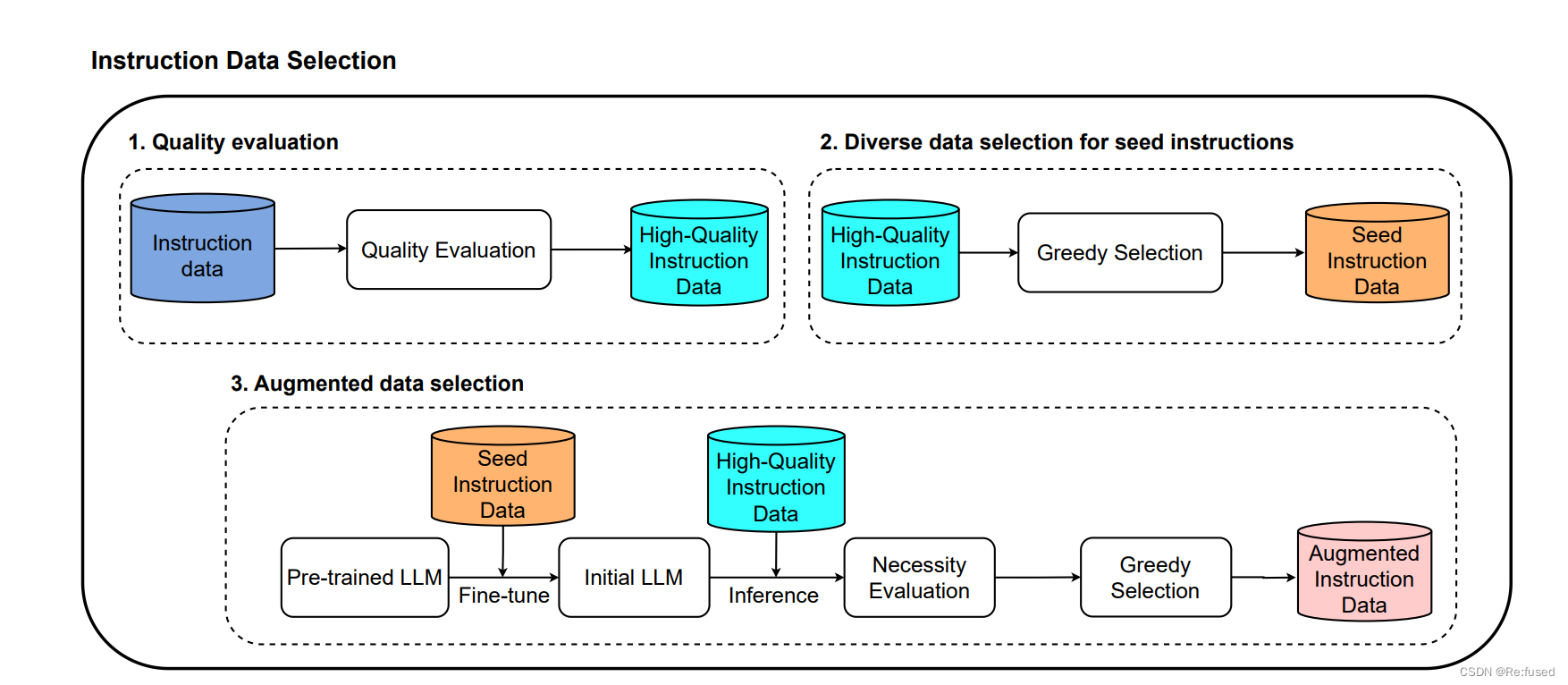
- 数据质量:
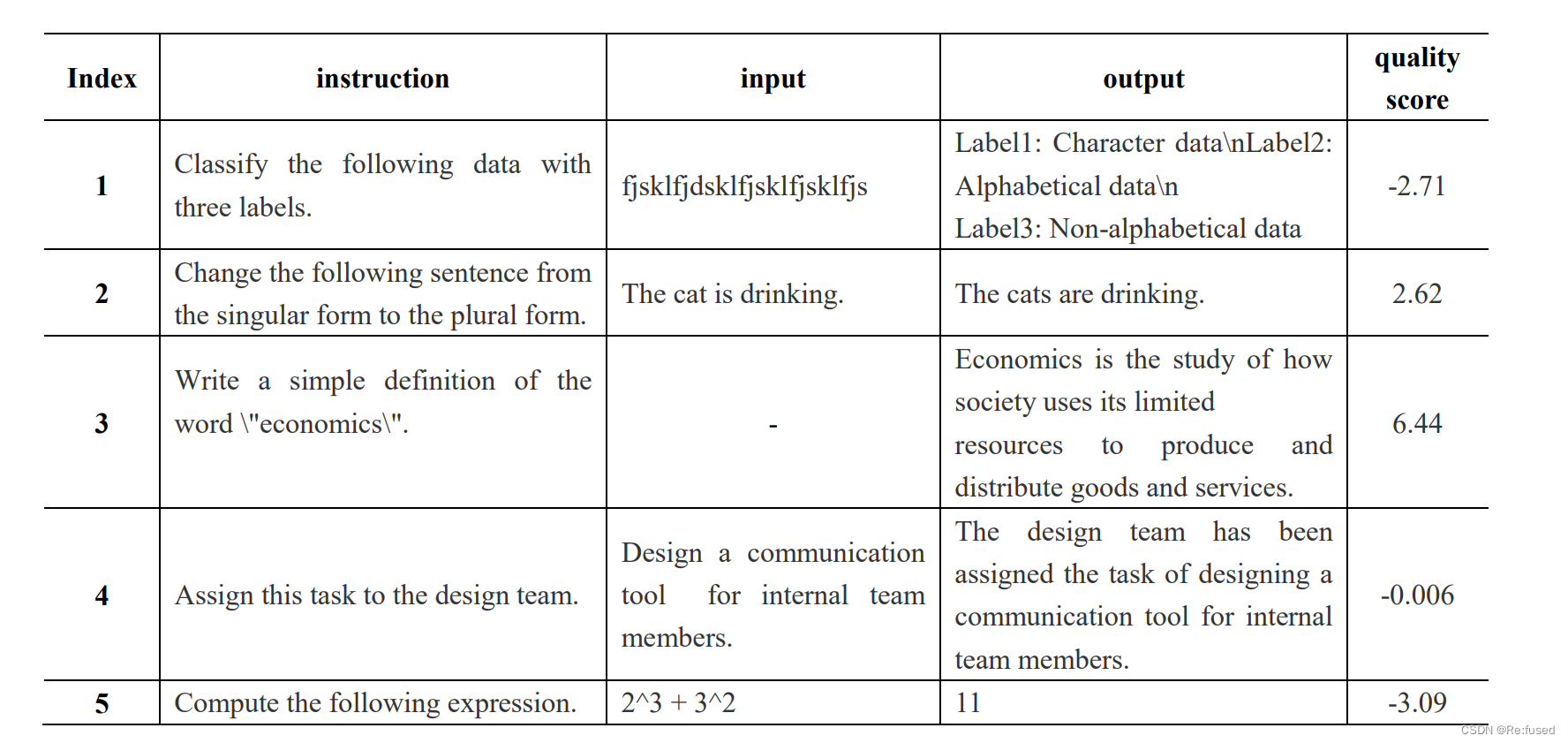
数据质量则是利用huggingface已经训练的一个模型,reward-model-deberta v3-large去给Instruction tunning 数据进行打分,将数据中的(instruction, input, output)进行拼接在一起,作为打分模型的输入,设置一个阈值 α \alpha α。超过这个阈值 α \alpha α则认为是高质量的数据,否则亦然。 - 数据多样性:
对于数据多样性,则是体现大模型,回答是否更加多样性。采用K-Center-Greedy,进行实现。
通过bert(或者其他向量模型)将文本转成向量,我理解就是实现一个K个中心点的算法,简单理解实现多个簇(肯能叙述不严谨),实现算法如下:

必要性
必要性,主要是因为模型学习的内容和学习的程度不同,因此需要针对不同的模型去评估模型已经学习了哪些内容,在上述两个操作之后的结果A。对A进行补充额外的数据B。模型图如下所示:
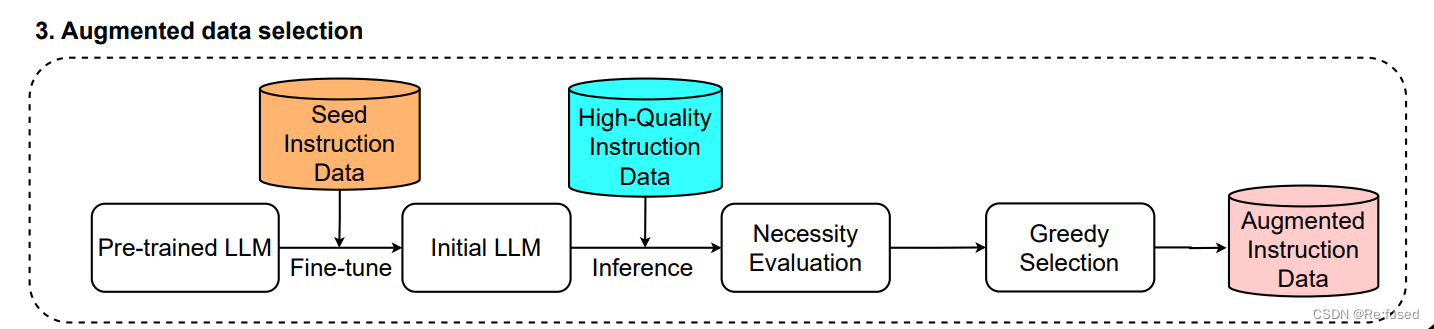
如何获取数据B呢,首先我把A作为基础的数据集对LLM进行微调,然后评估微调的指令生成回答同样采用reward-model-deberta v3-large模型设置阈值 β \beta β, 如果小于 β \beta β,则通过K-Center-Greedy选择一个子集。就可以获得A的扩增数据B。
实验结果
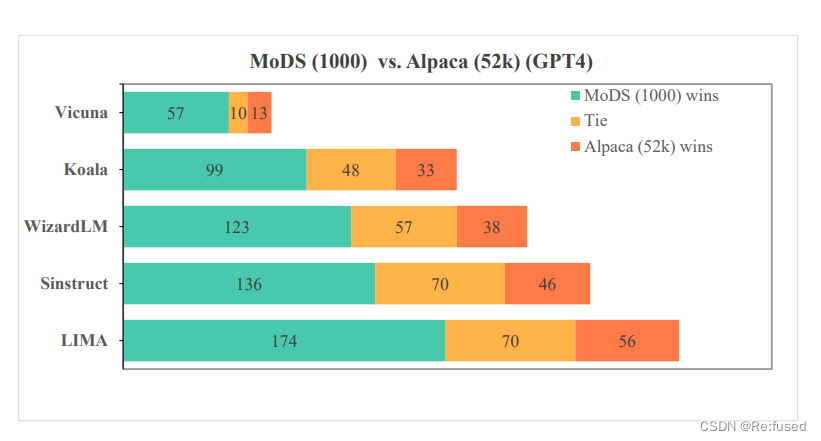
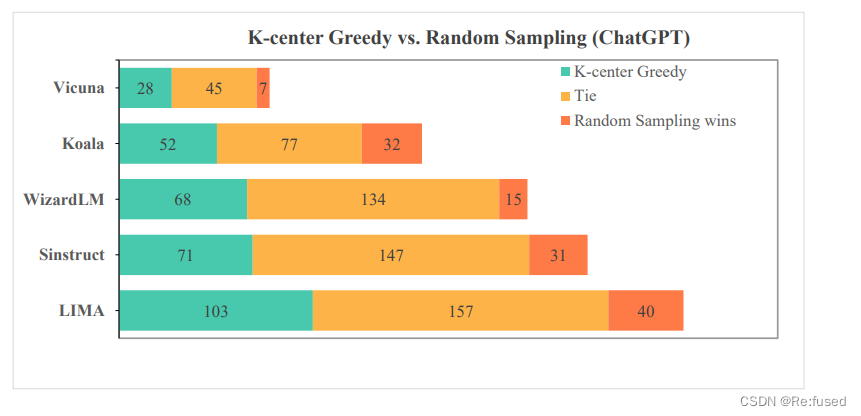
消融实验:数据多样性次啊用K-center Greedy和随机采样进行对比
这篇关于MoDS: Model-oriented Data Selection for Instruction Tuning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



