本文主要是介绍EDT:On Efficient Transformer-Based Image Pre-training for Low-Level Vision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
EDT:On Efficient Transformer-Based Image Pre-training for Low-Level Vision
论文地址:On Efficient Transformer-Based Image Pre-training for Low-Level Vision
代码地址:fenglinglwb/EDT: On Efficient Transformer-Based Image Pre-training for Low-Level Vision
现阶段问题
预训练在high-level计算机视觉中产生了许多最先进的技术,但很少有人尝试研究预训练如何在low-level任务中。
主要贡献
-
提出了一个用于低级视觉的高效且通用的Transformer框架:改进window attention,分别从高、宽进行切块计算注意力。
-
是第一个对低级视觉的图像预训练进行深入研究的人,揭示了预训练如何影响模型的内部表示以及如何进行有效的预训练的见解
网络框架
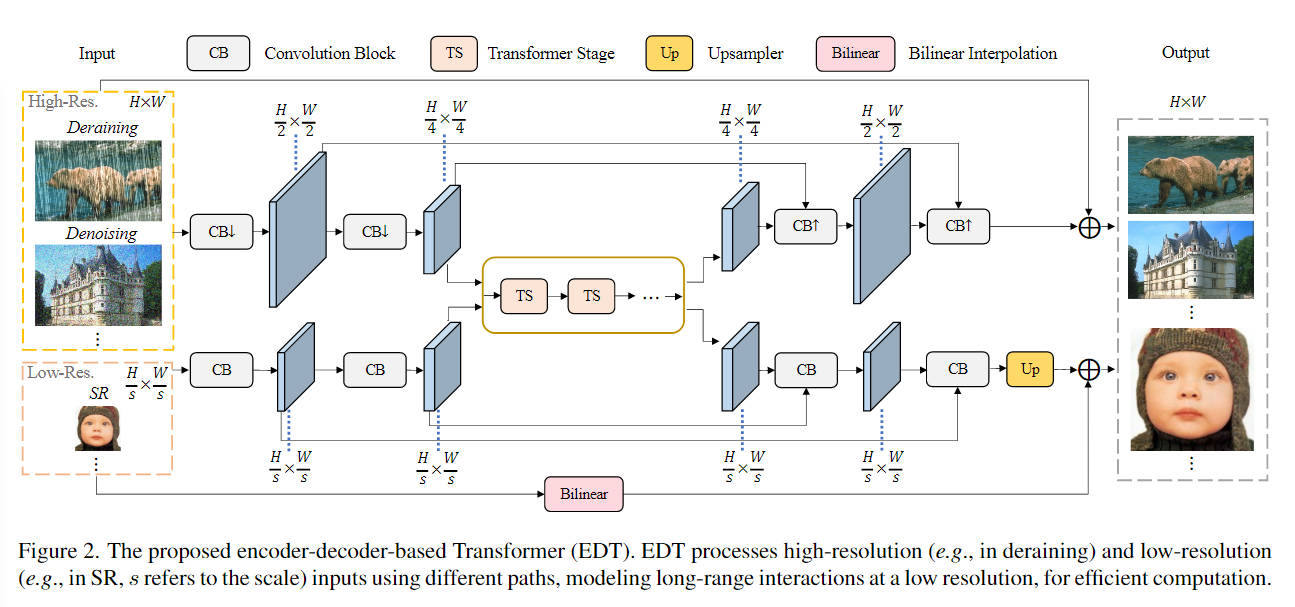
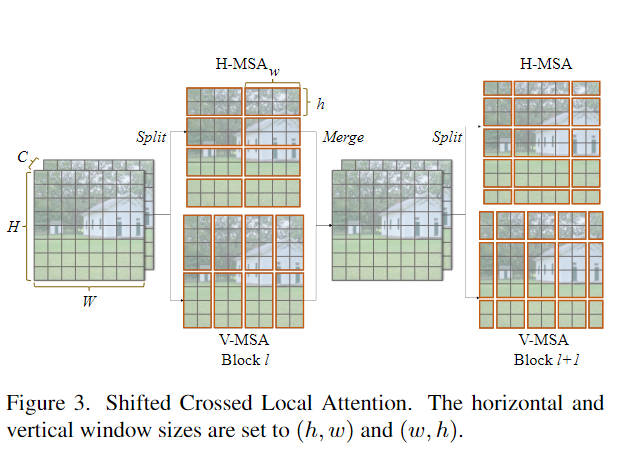
Shifted Crossed Local Attention
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows基础上进行改进。
X = [ X 1 , X 2 ] , w h e r e X 1 , X 2 ∈ R ( H × W ) × C / 2 , X 1 ′ = H − M S A ( X 1 ) , X 2 ′ = V − M S A ( X 2 ) , ( S ) C L − M S A ( X ) = P r o j ( [ X 1 ′ , X 2 ′ ] ) , \begin{aligned} &\mathbf{X}=[\mathbf{X}_{1},\mathbf{X}_{2}],\mathrm{~where~}\mathbf{X}_{1},\mathbf{X}_{2}\in\mathbb{R}^{(H\times W)\times^{C/2}}, \\ &\mathbf{X}_{1}^{'}=\mathrm{H-MSA}(\mathbf{X}_{1}), \\ &\mathbf{X}_{2}^{^{\prime}}=\mathrm{V-MSA}(\mathbf{X}_{2}), \\ &(\mathrm{S})\mathrm{CL-MSA}(\mathbf{X})=\mathrm{Proj}([\mathbf{X}_{1}^{'},\mathbf{X}_{2}^{'}]), \end{aligned} X=[X1,X2], where X1,X2∈R(H×W)×C/2,X1′=H−MSA(X1),X2′=V−MSA(X2),(S)CL−MSA(X)=Proj([X1′,X2′]),
def calculate_mask(self, x_size, index):# calculate attention mask for SW-MSAif self.shift_size is None:return NoneH, W = x_sizeimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_window_size, w_window_size = self.window_size[0], self.window_size[1]h_shift_size, w_shift_size = self.shift_size[0], self.shift_size[1]if index == 1:h_window_size, w_window_size = self.window_size[1], self.window_size[0]h_shift_size, w_shift_size = self.shift_size[1], self.shift_size[0]h_slices = (slice(0, -h_window_size),slice(-h_window_size, -h_shift_size),slice(-h_shift_size, None))w_slices = (slice(0, -w_window_size),slice(-w_window_size, -w_shift_size),slice(-w_shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size, index) # nW, h_window_size, w_window_size, 1mask_windows = mask_windows.view(-1, h_window_size * w_window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskx = self.qkv(x) #B H W 3Cx = x.view(B, H, W, 3, C).permute(3,0,1,2,4).contiguous()#3 B H W Cx_h = x[...,:C//2]x_v = x[...,C//2:]if self.shift_size:x_h = torch.roll(x_h, shifts=(-self.shift_size[0],-self.shift_size[1]), dims=(2,3))x_v = torch.roll(x_v, shifts=(-self.shift_size[1],-self.shift_size[0]), dims=(2,3))if self.input_resolution == x_size:attn_windows_h = self.attns[0](x_h, mask=self.attn_mask_h)attn_windows_v = self.attns[1](x_v, mask=self.attn_mask_v)else:mask_h = self.calculate_mask(x_size, index=0).to(x_h.device) if self.shift_size else Nonemask_v = self.calculate_mask(x_size, index=1).to(x_v.device) if self.shift_size else Noneattn_windows_h = self.attns[0](x_h, mask=mask_h)attn_windows_v = self.attns[1](x_v, mask=mask_v)if self.shift_size:attn_windows_h = torch.roll(attn_windows_h, shifts=(self.shift_size[0],self.shift_size[1]), dims=(1,2))attn_windows_v = torch.roll(attn_windows_v, shifts=(self.shift_size[1],self.shift_size[0]), dims=(1,2))attn_windows = torch.cat([attn_windows_h, attn_windows_v], dim=-1)attn_windows = self.proj(attn_windows) #B H W C
Anti-Blocking FFN
分组卷积是指将输入和输出通道分为若干组,在每组内部进行卷积操作,这可以加速计算并在一定程度上提高模型的表征能力
self.dwconv = nn.Conv2d(hidden_features, hidden_features, 5, 1, 5//2, groups=hidden_features)
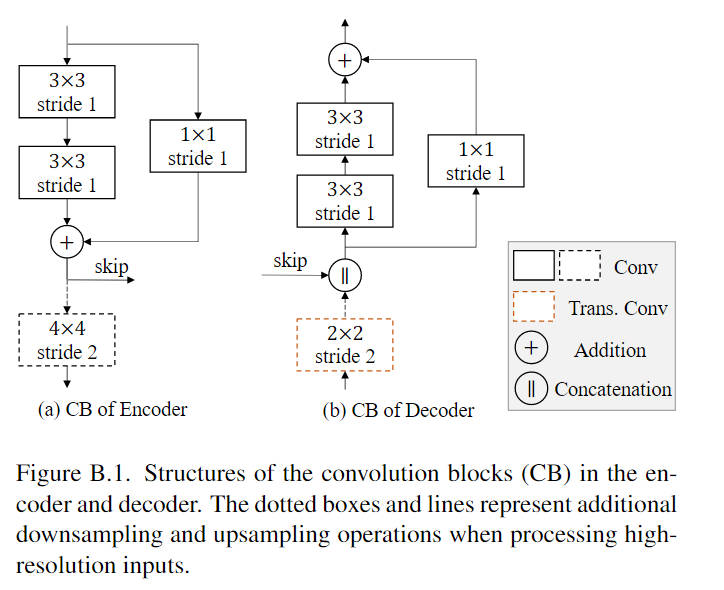
Convolution Block
这篇关于EDT:On Efficient Transformer-Based Image Pre-training for Low-Level Vision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)


