本文主要是介绍19:nuScenes: A multimodal dataset for autonomous driving,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
目标的鲁棒检测与跟踪是自动驾驶汽车技术发展的关键。基于图像的基准数据集推动了计算机视觉任务的发展,如目标检测、跟踪和环境中代理的分割。然而,大多数自动驾驶汽车都配有摄像头和测距传感器,如激光雷达和雷达。随着基于机器学习的检测和跟踪方法变得越来越流行,有必要在包含距离传感器数据和图像的数据集上训练和评估这些方法。在这项工作中,我们展示了nuTonomy场景(nuScenes),这是第一个搭载全自动汽车传感器套件的数据集:6个摄像头、5个雷达和1个激光雷达,所有这些都具有360度的视场。nuScenes由1000个场景组成,每个20分钟长,并带有23个类和8个属性的3D边框。它有7倍的注释和100倍的图像,这是开创性的KITTI数据集。我们定义了新的3D检测和跟踪指标。我们也提供仔细的数据集分析以及基线的李达和基于图像的检测和跟踪。数据,开发工具包和更多的信息可在网上获得。
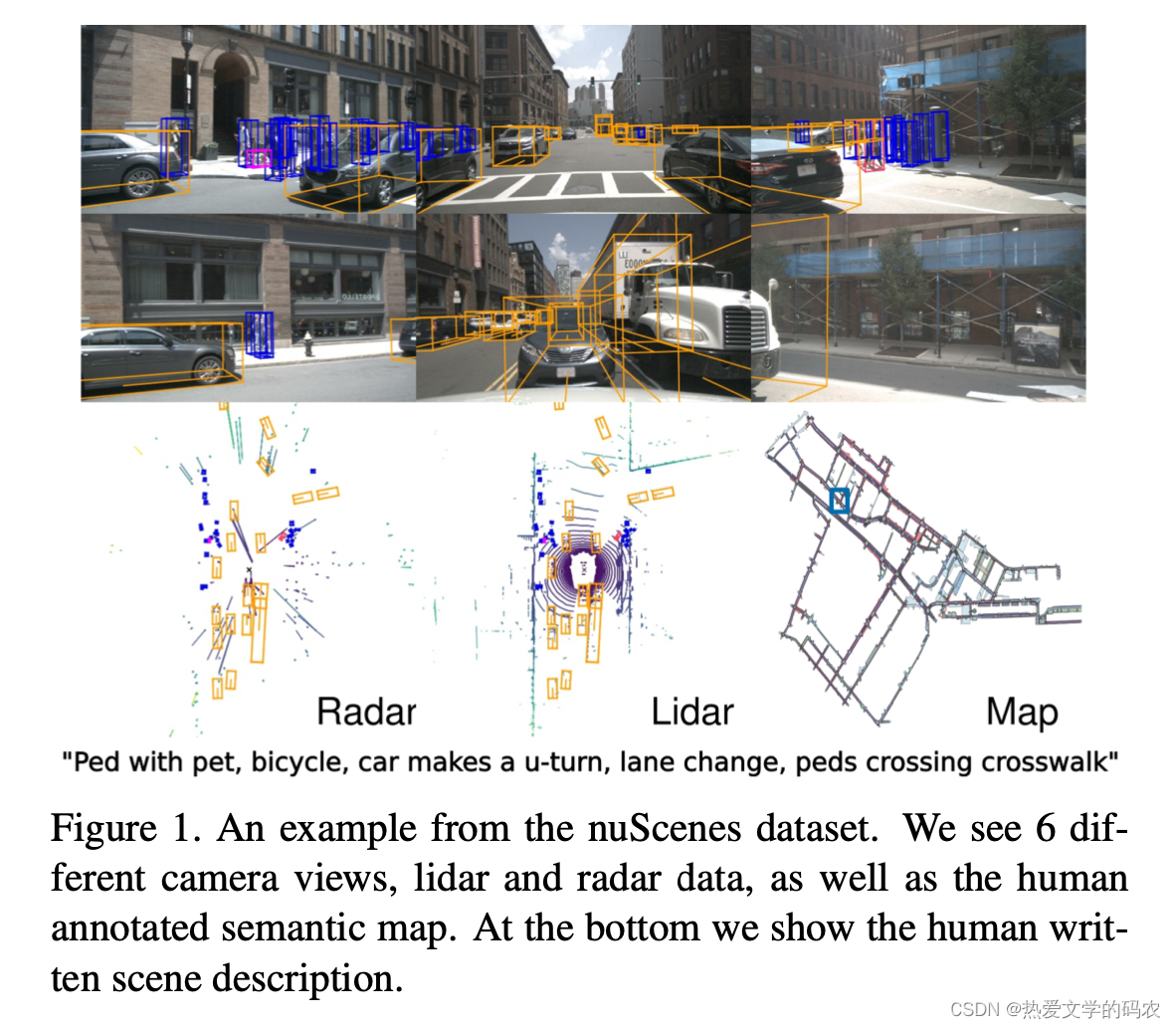
多模态数据集特别重要,因为单一类型的传感器是不够的,而传感器类型是互补的。相机允许精确测量边缘,颜色和照明,使分类和局部化的图像平面。然而,从图像中进行3D定位具有挑战性。而激光雷达点云在三维中包含的语义信息较少,但定位精度较高。此外,激光雷达的反射率是一个重要的特征。然而,激光雷达的数据是稀少的,范围通常限制在50-150米。雷达传感器达到200- 300米的范围,并通过多普勒效应测量物体的速度。然而,它的结果比激光雷达更稀疏,在定位方面也更不精确。虽然雷达已经使用了几十年,但我们还没有发现任何自动驾驶数据集可以提供雷达数据。

虽然已有一些工作提出了基于摄像机和 lidar 的融合方法,但PointPillars展示了一种仅使用激光雷达的方法,其性能与现有的基于融合的方法相当。这表明需要更多的工作来以一种有原则的方式结合多模态测量。
在最初发布nuScenes时,只有少数数据集使用3D boxes 标注对象,而且它们没有提供完整的传感器套件。在nuScenes发布之后,现在有几个集包含了完整的传感器套件。尽管如此,据我们所知,没有其他3D数据集提供属性注解,如行人姿势或车辆状态。
现有的自动驾驶汽车数据集和车辆集中在特定的操作设计领域。将其推广到复杂、杂乱和不可见的环境中还需要更多的研究。因此,有必要研究如何将检测方法推广到不同的国家、照明(白天vs.夜间)、驾驶方向、道路标记、植被、降水和以前未见过的对象类型。
使用语义地图的上下文知识也是场景理解的重要先决条件。例如,人们可能会在路上看到汽车,但不会在人行道上或建筑物内。值得注意的是,大多数AV数据集不提供语义图。
从多模态三维检测挑战的复杂性和当前AV数据集的局限性来看,一个具有360度覆盖从不同情况下收集的所有视觉和距离传感器以及地图信息的大规模多模态数据集将进一步促进对AV场景的理解研究。nuScenes正是这样做的,这也是这项工作的主要贡献。
2. 贡献
这也是第一个包含雷达数据的自动驾驶汽车数据集,并使用经批准用于公共道路的自动驾驶汽车进行捕获。它是第一个包含夜间和雨天数据的多模态数据集,除了对象类和位置外,还包含对象属性和场景描述。nuScenes是AVs的整体场景理解基准。它使研究多任务,如对象检测,跟踪和在一系列条件下的行为建模。
一些工作扩展了我们的数据集,引入了新的符号,用于自然语言对象引用和高级场景理解。检测挑战的能力,基于激光雷达和摄像头检测工作等, 改进的最先进的最初版本的时候提高了40%和81%。nuScenes已被用于3d对象检测, 多智能预测, 行人定位, 天气增强, 和移动点云预测。nuScenes仍然是唯一一个提供雷达数据的带注释的AV数据集,因此鼓励研究人员探索雷达和传感器融合用于目标检测。
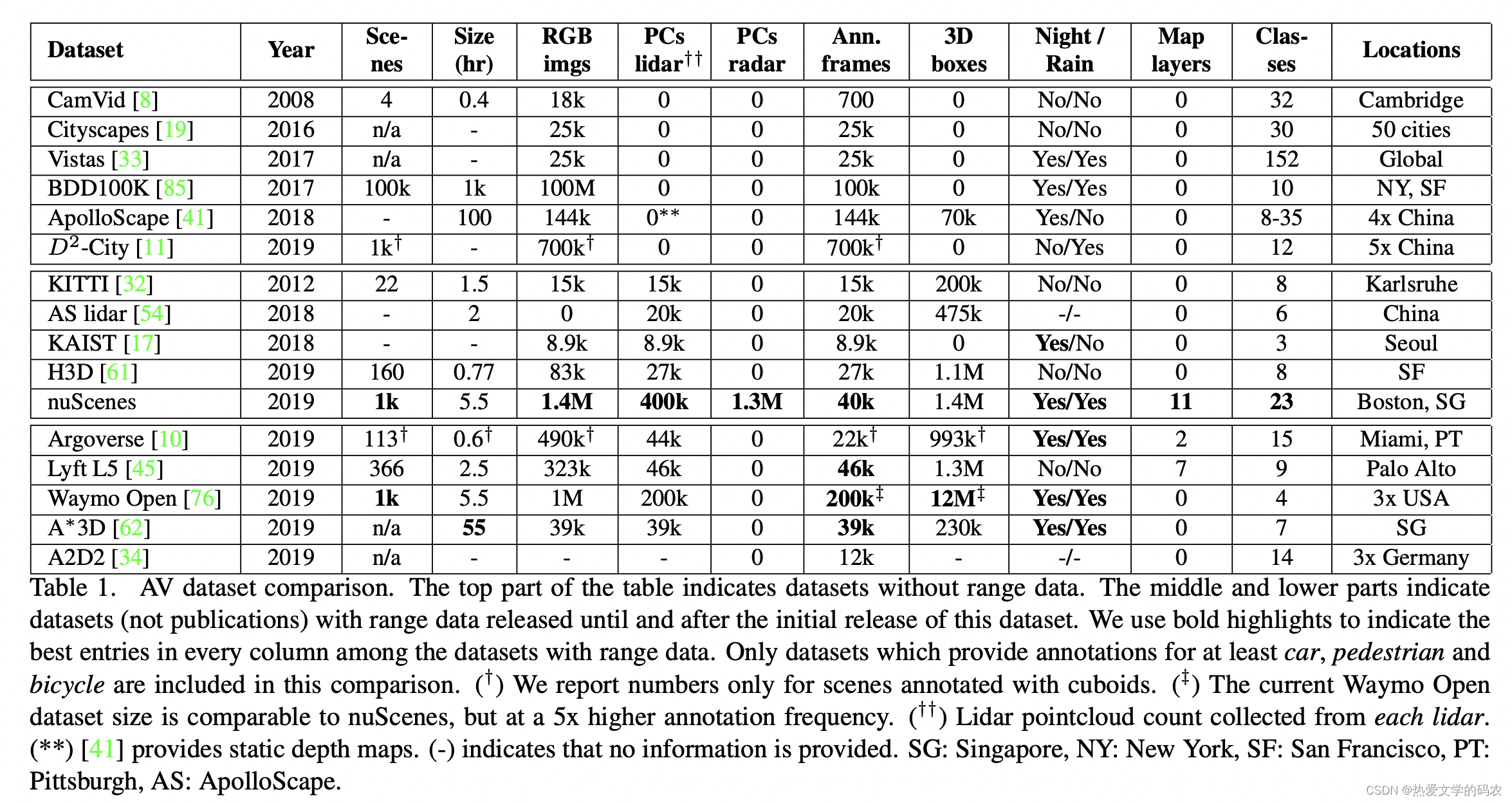
另一方面,通常由图像、距离传感器数据(激光雷达、雷达)和GPS/IMU数据组成的多模态数据集,由于集成、同步和校准多个传感器的困难,收集和注释成本昂贵。KITTI是领先的多模态数据集,提供来自激光雷达传感器的密集点云,以及面向前方的立体图像和GPS/IMU数据。它在22个场景中提供了20万个3D盒子,这有助于推进3D对象检测的最先进的技术。最近的H3D数据集包括160个拥挤的场景,总共有110万个3D盒子标注超过27k帧。对象是在全360视图中标注的,而KITTI只有在正面视图中才标注对象。KAIST多光谱数据集是由RGB和热相机、RGB立体、3D激光雷达和GPS/IMU组成的多模态数据集。它提供夜间数据。其他值得注意的多模式数据集包括提供驾驶行为标签,提供地点分类标签和提供没有语义标签的原始数据。
3.The nuScenes dataset
作者采用了一系列的行车日志

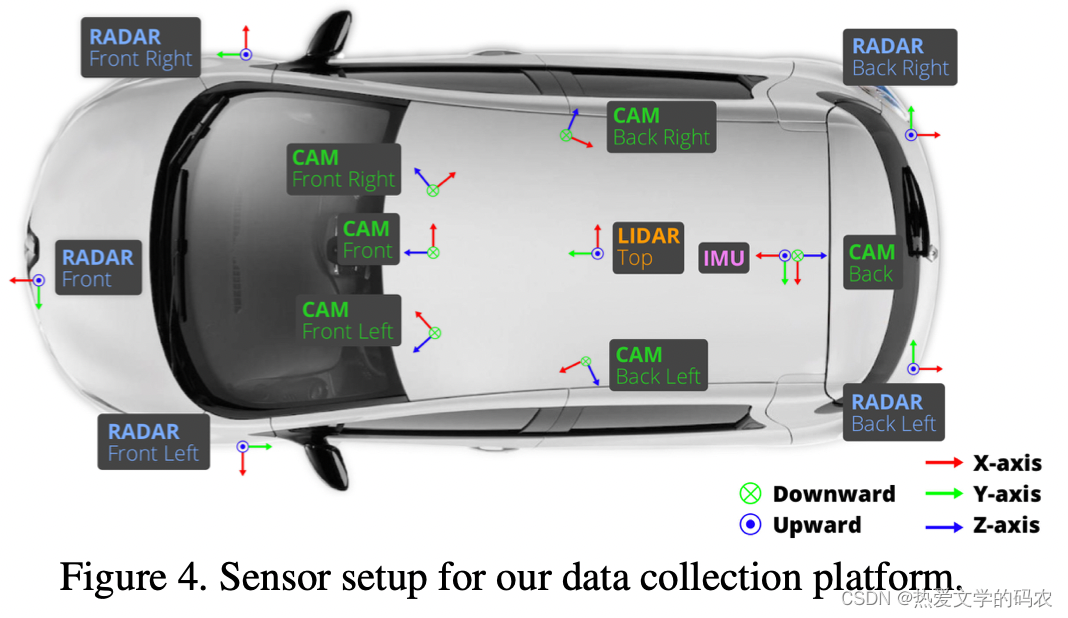
车的设置。我们在波士顿和新加坡使用了两辆传感器布局相同的雷诺佐伊(Renault Zoe)超小型电动汽车。前面和侧面相机有一个70◦视场和偏移55◦。后摄像头的视场为110◦。
传感器同步。为了在激光雷达和相机之间实现良好的跨模态数据对齐,当顶部激光雷达扫过相机的视场中心时,相机的曝光被触发。图像的时间戳为曝光触发时间;激光雷达扫描的时间戳是当前激光雷达帧实现全旋转的时间。考虑到相机的曝光时间几乎是瞬时的,这种方法通常可以得到很好的数据对齐。我们使用下面描述的定位算法进行运动补偿。
本地化。现有的大多数数据集提供基于GPS和IMU的车辆位置。如KITTI数据集所示,这种本地化系统容易受到GPS中断的影响。在人口密集的城区,这个问题就更加突出了。为了准确地定位我们的车辆,我们创建了一个详细的高清地图的激光雷达点在离线的步骤。在采集数据时,利用激光雷达和里程计信息进行蒙特卡罗定位。该方法具有很强的鲁棒性,实现了≤10cm的定位误差。为了鼓励机器人研究,我们还提供了类似于原始CAN总线数据(如速度、加速度、扭矩、转向角度、轮速)。
地图。我们提供了相关领域的高度精确的人类注释的语义地图。原始的栅格化地图只包括道路和人行道,分辨率为10px/m。向量化地图扩展提供了图3中所示的11个语义类的信息,使其比自最初发布以来发布的其他数据集的语义地图更加丰富。我们鼓励使用本地化和语义地图作为所有任务的强先验。
场景的选择。采集完原始的传感器数据后,我们手动选择1000个20秒的有趣场景。这些场景包括高交通密度(如十字路口、建筑工地)、罕见等级(如救护车、动物)、潜在危险交通状况(如行人、不正确行为)、机动(如变道、转弯、我们还选择了一些场景,以鼓励在空间覆盖、不同的场景类型以及不同的天气和照明条件方面的多样性。专家为每个场景写文字描述或说明(例如:“在十字路口等候,孩子在人行道上,自行车过马路,乱穿马路的人,右转,停车的汽车,下雨”)。
数据注释。选定场景后,我们以2Hz的频率采样关键帧(图像、激光雷达、雷达)。我们用语义类别、属性(可见性、活动和姿势)和一个以x、y、z、宽度、长度、高度和偏航角度为模型的长方体来注解每个关键帧中的23个对象类。如果对象被至少一个激光雷达或雷达点覆盖,我们将在每个场景中不断地注释对象。使用专家注释器和多个验证步骤,我们实现了高度准确的注释。我们还发布了中间传感器帧,中间传感器帧对于跟踪、预测和目标检测非常重要。在相机、雷达和激光雷达的捕捉频率为12Hz、13Hz和20Hz时,这使我们的数据集独一无二。只有Waymo Open数据集提供了类似的10Hz的高捕获频率。
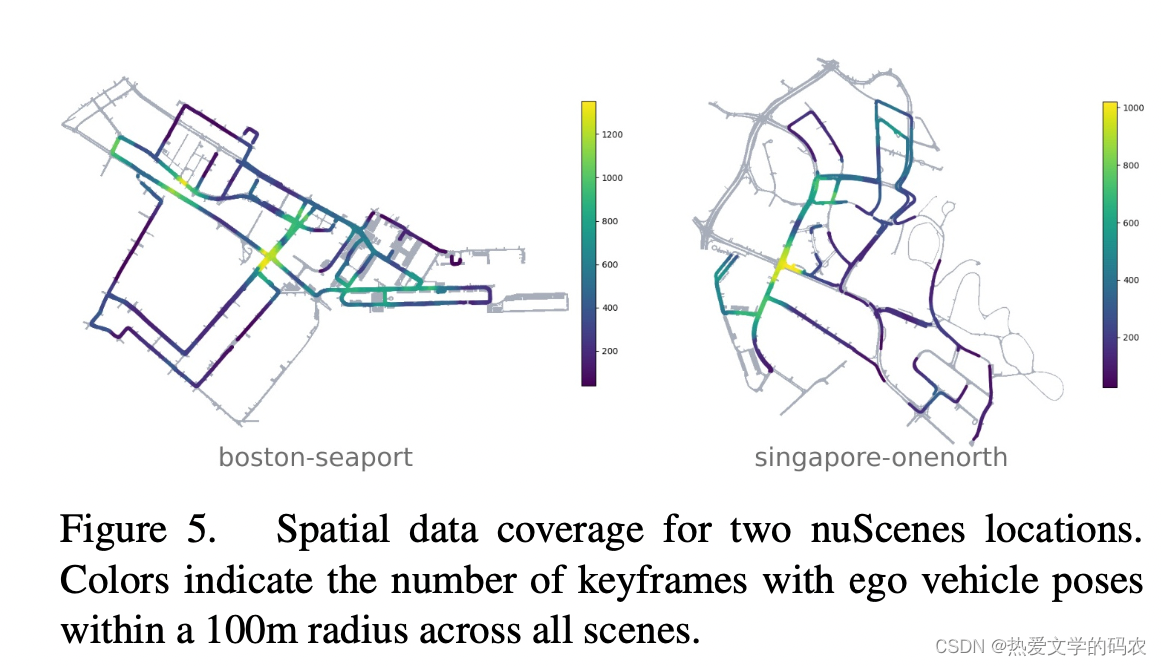
注释的统计数据。我们的数据集有23个类别,包括不同的车辆、行人类型、移动设备和其他对象。我们给出了不同类别的几何和频率的统计数据。每个关键帧平均有7个行人和20辆车辆。此外,40k关键帧拍摄于四个不同的场景地点(波士顿:55%,SG-OneNorth: 21.5%, SG-Queenstown: 13.5%, SG-HollandVillage: 10%),不同的天气和光照条件(雨:19.4%,夜晚:11.6%)。由于nuScenes中的细粒度类,该数据集显示了严重的类失衡,最小和最常见的类标注的比例为1:10k(在KITTI中为1:36)。这鼓励社区更深入地探索这个长尾问题。
4.任务
nuScenes的多模态特性支持多种任务,包括检测、跟踪、预测和本地化。这里我们介绍了检测和跟踪任务和指标。我们定义检测任务只对时刻为t的目标在[t 0.5, t]秒之间的传感器数据进行操作,而跟踪任务则对[0,t]秒之间的数据进行操作。
4.1. Detection
nuScenes检测任务需要检测10个带有3D包围盒、属性(例如坐与站)和速度的对象类。这10个类是所有nuScenes中注释的23个类的子集。
平均精度指标。
我们使用平均精度(AP)度量,但通过阈值定义匹配在地平面上的二维中心距离d,而不是在联合(IOU)的交叉。这样做是为了几个检测对象大小和方向也因为对象与小的足迹,行人和自行车,这个很难比较vision-only方法的性能往往有大定位错误。
然后我们将AP计算为查全率曲线下的归一化面积,查全率在10%以上。召回率或召回精度低于10%的工作点被删除,以尽量减少噪声的影响——在低召回率和召回率区域常见的噪声。如果在该区域内没有达到工作点,则该类的AP设置为零。然后我们对D ={0.5, 1,2,4}米和C类集合的匹配阈值进行平均:
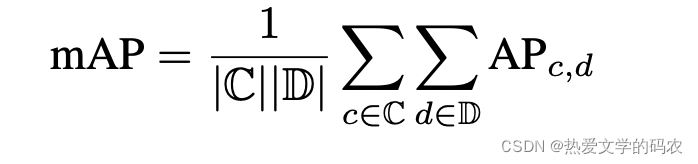
真正积极的指标。除了AP之外,我们还为与地面真值框相匹配的每个预测度量了一组真值度量(TP度量)。在匹配过程中,所有的TP度量都采用d = 2m的中心距离来计算,它们都被设计为正标量。在提议的度量中,TP度量都是本地单位,这使得结果易于解释和比较。匹配和评分在每个类独立进行,每个指标是在每个达到的回忆水平超过10%时的累积平均值。如果某一特定类没有达到10%的召回率,则将该类的所有TP错误设置为1。定义了以下TP错误:
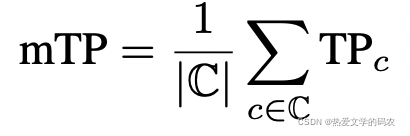
nuScenes检测得分。
带有IOU阈值的mAP可能是最流行的对象检测度量。然而,这个指标不能捕捉nuScenes检测任务的所有方面,如速度和属性估计。此外,它还结合了对位置、大小和方向的估计。ApolloScape 3D汽车实例挑战通过定义每种错误类型的阈值和召回阈值来解开这些问题。使这种方法复杂、任意和不直观。我们建议将不同的错误类型合并成一个标量分数:nuScenes检测分数
(NDS)。

4.2 Tracking
在本节中,我们将介绍跟踪任务的设置和指标。跟踪任务的重点是跟踪场景中所有被检测到的目标。除了静态类:barrier、construct和trafficcone外,所有检测类都被使用。AMOTA和amtp指标。Weng和Kitani在KITTI上提出了类似的3D MOT基准。他们指出,传统的衡量标准没有考虑预测的可信度。因此,他们开发了平均多目标跟踪精度(Avaverage Multi - Object Tracking Accuracy, AMOTA)和平均多目标跟踪精度(average Multi - Object Tracking Precision, amtp),它们跨越所有召回阈值的平均多目标跟踪精度(Av- average MOTA, MOTP)。通过比较KITTI和nuScenes在检测和跟踪方面的排行榜,我们发现nuScenes明显更困难。由于nuScenes的难度,传统的MOTA度量通常为零。因此,在更新后的sMOTAr公式中,MOTA增加了一个术语,以便对各自的召回进行调整。
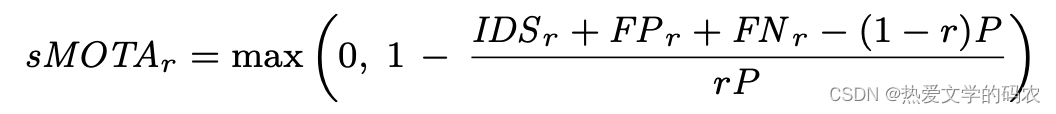
这是为了保证sMOTAr值跨越整个 [0, 1]区间。我们在查全率范围[0.1]内插40点(查全率值记为R),得到的sAMOTA度量是跟踪任务的主要度量:
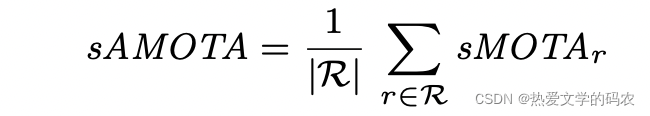
我们还使用传统的跟踪指标,如MOTA和MOTP、每帧的假警报、主要跟踪轨迹、主要丢失轨迹、假阳性、假阴性、身份切换和轨迹碎片。我们尝试了所有的回忆阈值,然后使用达到sMOTAr最高的阈值。TID和LGD度量。此外,我们设计了两个新的度量指标:跟踪初始化持续时间(TID)和最长间隔持续时间(LGD)。一些跟踪器需要一个固定的窗口过去的传感器读数或执行差,没有良好的初始化。TID度量从跟踪开始到第一次检测到对象的持续时间。LGD计算轨道中任何检测间隙的最长持续时间。如果一个对象没有被跟踪,我们将整个跟踪持续时间分配为TID和LGD。对于这两个指标,我们计算了所有轨道的平均值。这些指标与AVs是相关的,因为许多短期轨道碎片可能比错过一个对象几秒钟更容易接受。
5.实验
在本节中,我们将介绍nuScenes数据集上的目标检测和跟踪实验,分析它们的特点,并提出未来研究的方向。
5.1 Baselines
Lidar detection baseline.
为了演示一种领先的算法在nuScenes上的性能,我们训练了一个仅用于激光雷达的三维物体检测器PointPillars。我们利用在nuScenes中可用的时间数据,通过累积激光雷达扫描获得一个更丰富的pointcloud作为输入。一个单一的网络被训练用于所有的类别。该网络被修改学习速度作为一个额外的回归目标为每个3D盒子。我们将框属性设置为训练数据中每个类最常见的属性。
Image detection baseline.
为了检验纯图像的三维目标检测,我们重新实现了正投影特征变换(OFT)方法。一个单一的OFT网络被用于所有的类。我们将原来的OFT修改为使用SSD检测头,并确认这与KITTI上发布的结果一致。该网络采取了一个单一的图像,从全360◦预测结合在一起的6个相机使用非最大抑制(NMS)。属性设为列车数据中每个类最常见的属性。
Detection challenge results.
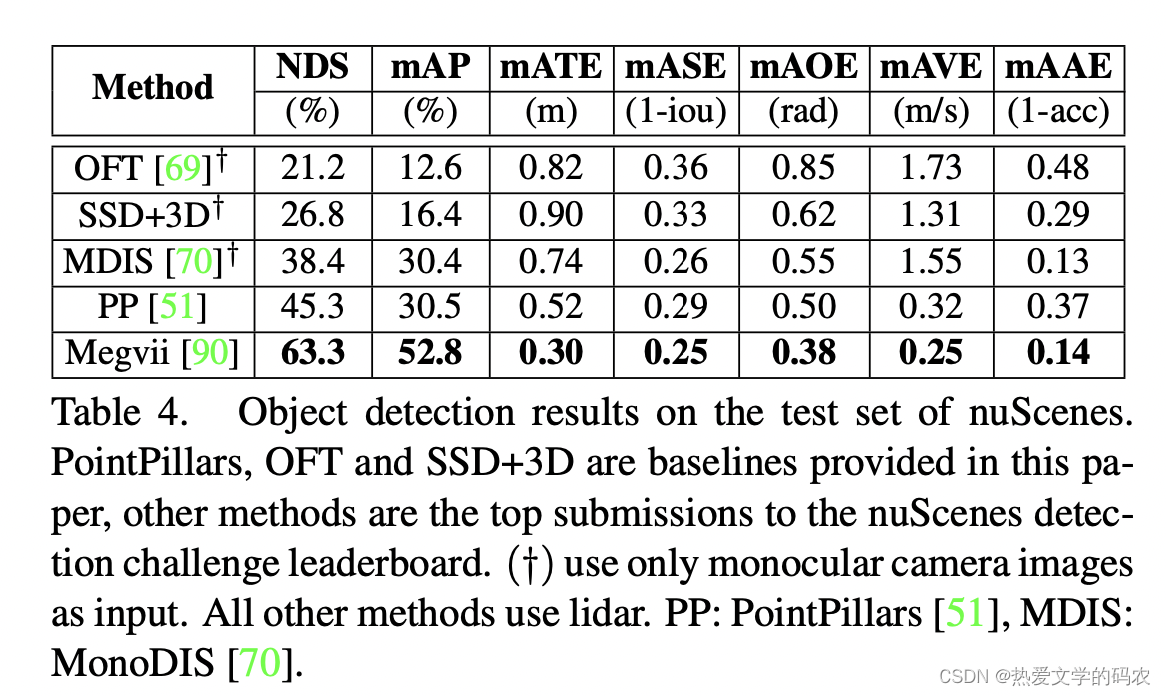
我们将比较2019年nuScenes检测挑战的最佳提交结果。在所有提交的作品中,Megvii表现最好。它是一种基于激光雷达的基于稀疏三维卷积的类平衡多头网络。MonoDIS是最好的,明显优于我们的图像基线,甚至一些基于激光雷达的方法。它采用了一种新颖的二维和三维探测分解方法。注意,最上面的方法都进行了重要抽样,这表明了解决类别不平衡问题的重要性。
Tracking baselines.
我们提出了几个基线跟踪相机和激光雷达数据。从探测挑战中,我们选择了性能最好的激光雷达方法,推理时间报告速度最快的方法(PointPillars),以及性能最好的相机方法。利用每种方法的检测结果,我们使用描述的跟踪方法建立基线。我们提供了每一种方法的检测和跟踪结果测试分割,以促进更系统的研究。
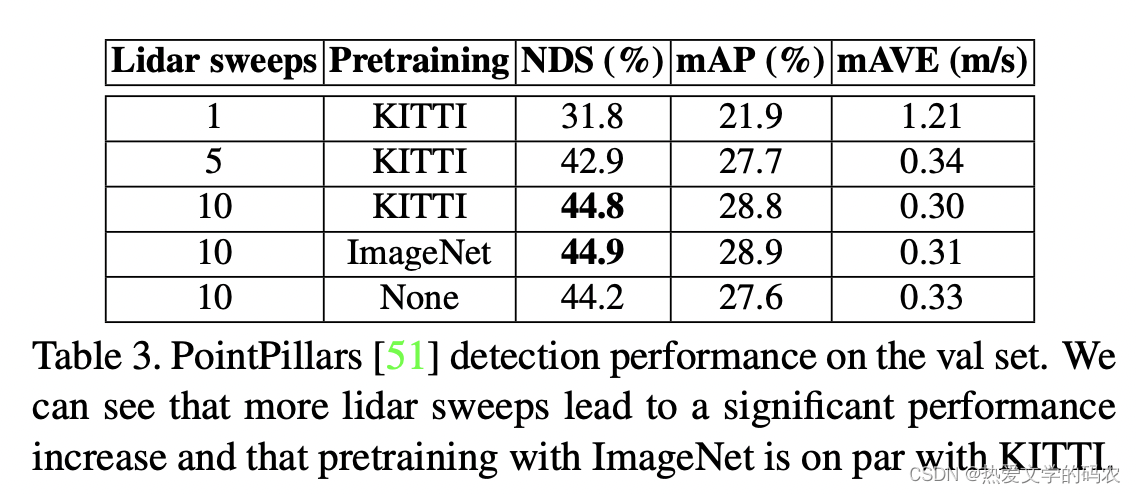
根据我们的评估方案,只允许使用0.5s的先前数据来做出检测决策。这相当于之前的10次激光雷达扫描,因为激光雷达的采样频率为20Hz。我们设计了一种简单的方法,将多个点云合并到点柱基线中,并研究了性能影响。累加是通过将所有点云移动到关键帧的坐标系统,并在每个点上附加一个标量时间戳来实现的,该时间戳表示从关键帧开始的时间增量(以秒为单位)。编码器包括时间delta作为激光雷达点的额外装饰。除了丰富点云的优点外,这也提供了时间信息,这有助于网络定位和速度预测。我们用1、5和10次激光雷达扫描进行实验。结果表明,探测和速度估计都随着激光雷达扫描次数的增加而提高,但recall率减小。
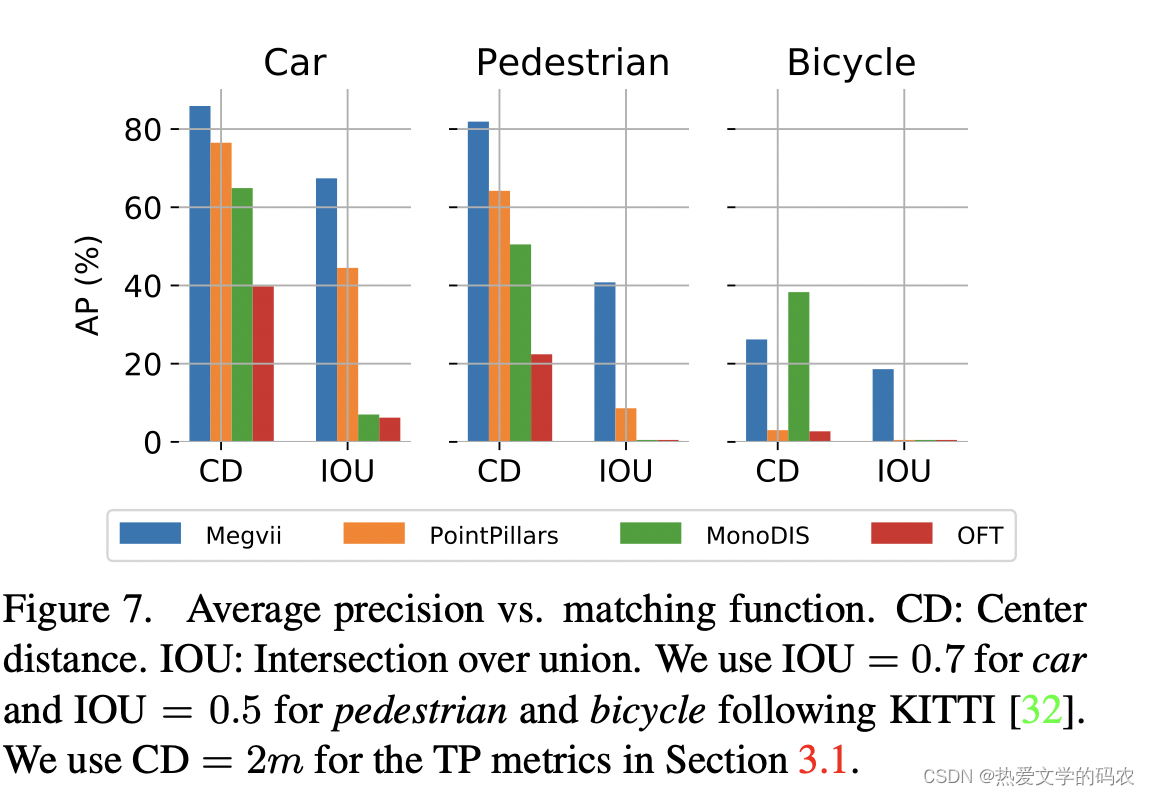
对于自动驾驶汽车来说,一个重要的问题是需要什么样的传感器才能达到最佳的检测性能。本文对激光雷达和图像探测器的性能进行了比较。我们关注这些模式,因为在文献中没有具有竞争力的雷达唯一方法,并且我们对雷达数据的pointpillar的初步研究没有取得令人满意的结果。我们将PointPillars快速、轻激光雷达探测器与MonoDIS顶级图像探测器进行了比较。两种方法的mAP相似(30.5% vs. 30.4%),但PointPillars具有更高的NDS (45.3% vs. 38.4%)。近距离地图本身是值得注意的,它说明了最近单目视觉在3D估计方面的优势。然而,如上所述,使用基于IOU的匹配函数,差异会更大。PointPillars在两个最常见的类别中表现更强:汽车(68.4%对47.8%的AP)和行人(59.7%对37.0%的AP)。另一方面,MonoDIS在小班自行车(24.5%对1.1%的AP)和锥形自行车(48.7%对30.8%的AP)上表现更强。这是预料之中的,因为自行车是薄物体,通常很少有激光雷达的返回;交通锥很容易在图像中被发现,但在激光雷达点云中很小,很容易被忽视。 MonoDIS在训练过程中使用重要度采样来增加稀有类。在相似的检测性能下,为什么MonoDIS的NDS较低?主要原因是平均翻译误差(52cm vs. 74cm)和速度误差(1.55m/s vs. 0.32m/s),两者都与预期一致。MonoDIS也有较大的尺度误差,平均IOU分别为74%和71%,但差异较小,表明单图像方法从外观推断尺寸的能力较强。
在本文中,我们介绍了nuScenes数据集、检测和跟踪任务、指标、基线和结果。这是第一个收集的数据集,从AV批准测试在公共道路上,并包含完整的360◦传感器套件(图像和雷达)。nuScenes拥有任何以前发布的数据集中最大的3D框注释集合。为了促进对AVs三维目标检测的研究,我们引入了一种新的检测指标,平衡了检测性能的各个方面。我们在nuScen上演示了领先的激光雷达和图像目标探测器和跟踪器的新适应性
这篇关于19:nuScenes: A multimodal dataset for autonomous driving的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








