本文主要是介绍CV-Paper-文字检测-Character Region Awareness for Text Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Character Region Awareness for Text Detection 基于字符识别的文字检测
- 1 确定哪些字符是连接的
- 1.1 ground truth 构造
- 2 数据标注问题-获得字符级别(Character-level)的标注
- 2.1 人工生成数据
- 2.2 弱监督
- 2.3 弱监督GT的生成过程
- 3 热图预测网络
- 4 网络收敛过程
- 5 网络预测性能
- 6 引用
Character Region Awareness for Text Detection 基于字符识别的文字检测
这篇文章是利用关键点检测的思想来进行文字检测。检测单个字符,并且识别出哪些字符是组成文字的,这样就可以检测出一组组文字。
以前的一些方法都是检测word-level的bounding box,但是这样会遇到一些难点,例如文字是弯曲的,不规则的,或则是特别长的。如果是基于character-level的话就没用这些难点了,因为是检测单个字符,所以没有文字形状的规定,并且,只需要小的感受野即可以了, 但是以前的检测包围框的方法就需要很大的感受野才行。
那么,基于单个字符区域的文字检测存在两个难点:
- 如何确定哪些字符是连接在一起组成文字的,而哪些字符是分离的;
- 数据标注问题,因为当前的数据集都是文字级别(word-level)的标注。
下面分别来说明解决这两个难点的方法。
1 确定哪些字符是连接的
字符检测:本文使用的网络使用了目前关键点检测中常用的网络结构,即采用预测热图的方式来进行检测关键点,那么在这里我们就可以把每个字符当做一个关键点,所以每个字符其实对应着一个热点,只要预测每个文字所对应的热点那么就可检测出每个字符。
字符连接的识别:那么,现在字符的检测方法有了,我们要怎么知道哪些字符是组成一个文字的。这里我觉得作者特别聪明,作者也使用热图的方式来表示文字的连接,如果两个字符是相连接的,那么这两个字符之间就有一个热点。很高明的做法,利用热点图来确定两个字符是不是一组的。
热点就代表着一个响应,如果图片中的某个地方有热点响应,那么表示这个地方存在我们需要的信息,热点的值的大小就代表着置信度,如果置信度越高,那么越确定。
1.1 ground truth 构造
如何构造我们的监督信息,可以看下面这幅图。

从上图可以看出,我们的监督信息(或者说网络的预测)有两个,一个是Region Score GT(区域分数),这个是预测字符位置的热图,另外一个是Affinity Score GT(关联分数),这个是预测两个字符是否关联的热图。
region score其实就是单个字符的包围框的一个二维高斯图,他是通过对二维正态分布的高斯图进行仿射变换得到的。
Affinity Score 通过画对角线来连接每个字符框的对角,我们可以生成两个三角形——我们将其称为上字符三角形和下字符三角形。然后,对于每个相邻的字符框对,通过将上三角形和下三角形的中心设置为框的角,生成一个关联框。然后将二维正态分布的高斯图进行仿射变换到关联框来获得对应的热图。
2 数据标注问题-获得字符级别(Character-level)的标注
如果想通过人工进行对字符进行标注,那么可想而知是非常耗时的。所以本文使用人工生成数据和弱监督结合的方式来解决这个问题。
2.1 人工生成数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3YNRfRGS-1571749596163)(file:///Users/jiangzhiqiang/Documents/Gridea/post-images/1557145267677.png)]
人工生成就是将文字黏贴到一下图片上,这时候因为是自己的文字,所以我们可以有字符级别的包围框,所以我们就有了字符级别的标注。
2.2 弱监督

上图就是一个弱监督的网络框架,作者将人工生成的数据和我们word-level标注数据一起进行训练。红色箭头预测的是region score,然后经过字符检测的热图来得到每个字符的框,这样进一步又可以得到affinity score的热图。这样就间接获得了文字的affinity score的热图。然后将预测得到的两个score热图作为ground truth进一步监督网络的训练。
当使用弱监督训练模型时,我们被迫训练不完整的伪GT。 如果使用不准确的区域分数训练模型,则输出可能在字符区域内模糊。 为了防止这种情况,我们测量模型生成的每个伪GT的质量。 幸运的是,文本注释中有一个非常强大的提示,即单词长度。 在大多数数据集中,提供了单词的转录,并且单词的长度可用于评估伪GT的置信度。
所以我们在训练的时候要根据伪GT的置信度来计算loss,如果生成的GT和真实情况很接近,那么这个loss就是有用的,如果生成的GT都很假,我们肯定是不接受这个loss。所以loss的计算方式如下:

那么如何计算这个置信度呢,我们可以通过计算伪GT的字符长度和真实的GT的字符长度比较来得到:
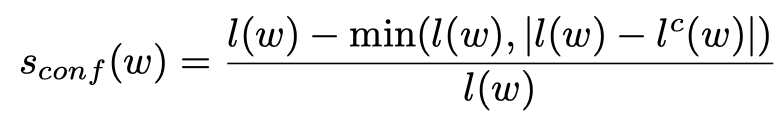
L(w)表示单词的长度,右上角加c的表示预测的得到的长度,取min得到的是不大于L(w)的值,这样Sconf的值就不会是负数,并且Sconf的值是0~1之间的。
并且预测的热图在这个单词的包围框外面则权重为1,其实简单的理解就是只在word的包围框内的时候它的loss需要加权,因为word(所有的单词区域)包围框外面是没有文字的,所以只要预测出来有字符那么都是假阳。
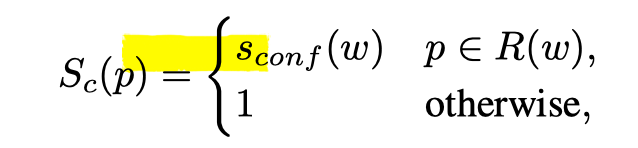
2.3 弱监督GT的生成过程

如图所示,就是先根据word-level标注的数据,将单词切出来,然后再进行预测,得到热图以后再进行处理。
3 热图预测网络
最后热图预测的网络是一个类U-net的网络。

4 网络收敛过程

5 网络预测性能

6 引用
论文:Character Region Awareness for Text Detection
这篇关于CV-Paper-文字检测-Character Region Awareness for Text Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








