character专题

深度剖析AI情感陪伴类产品及典型应用 Character.ai
前段时间AI圈内C.AI的受够风波可谓是让大家都丈二摸不着头脑,连C.AI这种行业top应用都要找谋生方法了!投资人摸不着头脑,用户们更摸不着头脑。在这之前断断续续玩了一下这款产品,这次也是乘着这个风波,除了了解一下为什么这么厉害的创始人 Noam Shazeer 也要另寻他路,以及产品本身的发展阶段和情况! 什么是Character.ai? Character.ai官网:https://

VSCode中latex文件(Misplaced alignment tab character .LaTeX
Misplaced alignment tab character &.LaTeX 先给出参考文章1 Misplaced alignment tab character &.LaTeX 把bib文件中的 &改为 and 。删除原有的bbl文件、重新运行 选择这个运行 这个错误在overleaf上并没有遇到、在vscode上遇到了 方法二就是把 &改为 \& ,记得删除

Java Character 类 和 方法
Character 类用于对单个字符进行操作。 Character 类在对象中包装一个基本类型 char 的值 实例 char ch = 'a';// Unicode 字符表示形式char uniChar = '\u039A'; // 字符数组char[] charArray ={ 'a', 'b', 'c', 'd', 'e' }; 然而,在实际开发过程中,我们经常会遇到需要使用对象

mysql 中 character set 与 collation 的点滴理解
转载自:http://zhongwei-leg.iteye.com/blog/899227 转载: http://zhongwei-leg.iteye.com/blog/899227 使用 mysql 创建数据表的时候, 总免不了要涉及到 character set 和 collation 的概念, 之前不是很了解。 这两天不是很忙, 就自己整理了一下。
配置aop报错: Pointcut is not well-formed: expecting 'name pattern' at character position
切入点表达式的使用规则: execution(modifiers-pattern? ret-type-pattern declaring-type-pattern? name-pattern(param-pattern) throws-pattern?) 有“?”号的部分表示可省略的,modifers-pattern表示修饰符如public、protected等,ret-type-patter

Shortest Distance to a Character
Given a string S and a character C, return an array of integers representing the shortest distance from the character C in the string. Example 1: Input: S = "loveleetcode", C = 'e'Output: [3, 2, 1,
Malformed version string ‘~‘: invalid character(s)
conda upgrade -n base -c defaults --override-channels conda

illegal character: '\ufeff' 错误
在linux服务器上启动项目,可能会报这个错误,原因是由于编码导致的错误,解决方式如下: 在本地用notepad++打开该文件,修改编码为UTF-8无BOM格式保存,然后再提交到服务器即可, 再次启动项目不会报错。success!
python2.7 的中文编码处理,解决UnicodeEncodeError: 'ascii' codec can't encode character 问题
python2.7 的中文编码处理 最近业务中需要用 Python 写一些脚本。尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息。 很快,我就遇到了异常: UnicodeEncodeError: 'ascii' codec can't encode characters in p

SyntaxError: Non-ASCII character '\xe6' in file
python默认编码是ASCII,你在脚本里加注释是中文的话会报这个错,只需要在脚本开头加上#coding=utf-8
SQLAlchemy查询Mysql报错unsupported format character ''' (0x27) at index 175
解决办法: 是使用带有模糊匹配或者百分号 % 的SQL, 前两者pymysql和pyhs2还好,不会有异常,但是如果使用SQLAlchemy去查询的话,需要将SQL中单个百分号%改成两个百分号%%。

ORA-12737: Instant Client Light: unsupported server character set CHS16GBK
当使用Navicat Premiun 英文版连接oracl时可能会报ORA-12737: Instant Client Light: unsupported server character set CHS16GBK错误 这是只要打开Navicat Premiun-->tools-->options 把OCI的地址指向oracle安装目录下的oci.dll即可,地址可能不完全相同,我的是在:F:
SyntaxError- Non-ASCII character '-xe8' in file
python编译报错: SyntaxError: Non-ASCII character ‘\xe8’ in file xxx原因是不支持中文注释,如这种中英文混杂注释: # Subtract off the mean and divide by the variance of the pixels.#减去平均值并除以像素的方差 解决办法: 在文件第一行加上 #encoding:utf

打开pl/sql developer出现NLS_LANG和字符集(Character set)问题
打开pl/sql developer出现NLS_LANG和字符集(Character set)问题 公司最近培训pl/sql,我安装完毕后打开,遇到如图问题。 PS:我的操作系统是英文的。 这是因为系统没有设置NLS_LANG系统变量。有两种方式查看。 1. 查看电脑属性。 2. 命令行查看。 PS:这里我已经设置过了,所以仅仅
python write出现 Non-character array cannot be interpreted as character buffer.
比如z是一个数字 out.wirte(z)报错 那么out.wirte(str(z))
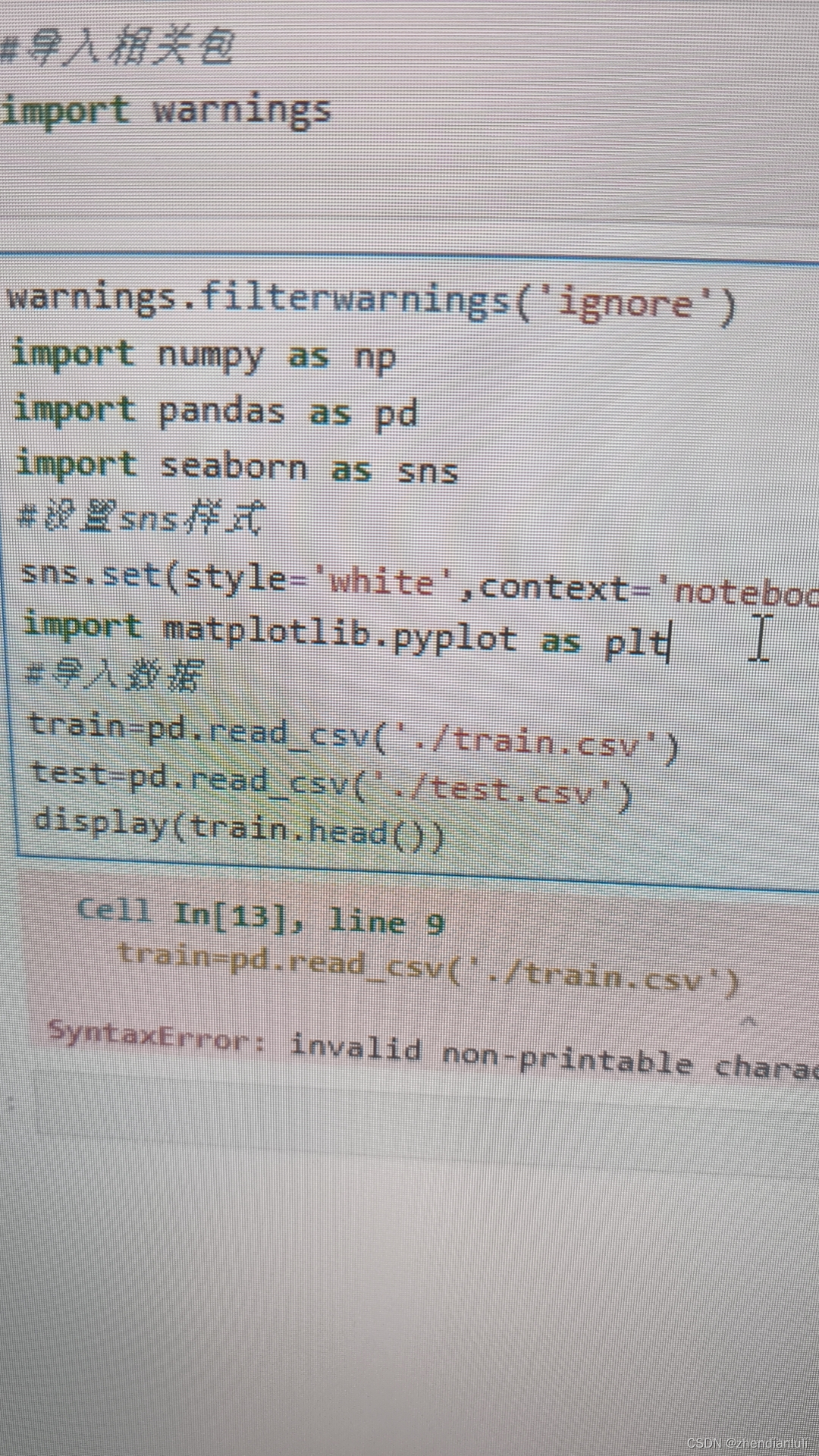
jupyter使用的一个奇怪bug——SyntaxError: invalid non-printable character U+00A0
bug来由:从其他部分例如kaggle里复制来的代码直接粘贴在jupyter notebook里,每一行代码都会出现: Cell In[5], line 1 warnings.filterwarnings('ignore') ^ SyntaxError: invalid non-printable character U+00A0 单元格 In[5],第 1 行 warnings.filterw
Longest Repeating Character Replacement问题及解法
问题描述: Given a string that consists of only uppercase English letters, you can replace any letter in the string with another letter at most k times. Find the length of a longest substring containin
error MSB8031 Building an MFC project for a non-Unicode character set is deprecated
VS2013多字节工程问题 使用VS2013编译旧版VC++程序时,提示Building an MFC project for anon-Unicode character set is deprecated,微软提供了解决方案。 一、错误信息 1>C:\ProgramFiles (x86)\MSBuild\Microsoft.Cpp\v4.0\V120\Microso

A JSONObject text must begin with '{' at character 1 of 1
JSONObject json = JSONObject.fromObject(str);JSONObject stateJson = (JSONObject) json.get("stateVO");String code = stateJson.getString("code"); 报异常,而结果是返回的json 对象, 这么写就不 报错

Character Region Awareness for Text Detection论文学习
1.首先将模型在Synth80k数据集上训练 Synth80k数据集是合成数据集,里面标注是使用单个字符的标注的,也就是这篇文章作者想要的标注的样子,但是大多数数据集是成堆标注的,也就是每行或者一堆字体被整体标注出来,作者想使用这部分数据集 2.对成行标注的数据集来说,先把成行的文字行切出来,然后用在Synth80k数据集上训练得到的模型推理得到Region score然后再用分水岭算法将单
在db2中varchar和character有何区别
character 就是char, 1.最大长度不同,char 最大254 bytes,varchar 最大 32672 bytes 2 存储不同 char(n) 在数据库占用 n 个字节,在数据库中以空格补足,但在取出来时末尾的空格将被去掉 varchar(n) 在数据库中至少占用1个字节,在数据库中末尾的空格将自动去掉,实际占用录入数据长度 +1 或者 +2

报错The environment variable 'Path' seems to have some paths containing the '' character.
我每次启动VSCODE时,总提示如下内容 问题 The environment variable ‘Path’ seems to have some paths containing the ‘"’ character. The existence of such a character is known to have caused the Python extension to not l
request error : ValueError invalid control character at line 1 ****
使用post请求服务,服务端出现解析参数错误: ValueError invalid control character at line 1 **** 解决办法: 原来的解析方式: arg_inner = json.loads(request.body) 修改为: arg_inner = json.loads(request.body.replace('\r\n', ' ').repl
SyntaxError: Non-ASCII character '/xe6'
转载自:http://blog.csdn.net/kofandlizi/article/details/6340221,谢谢分享! 这是在文本上写的第一个python语句,就是两个简单的print语句,但是都有中文的注释,然后用python命令在DOS命令行中执行python文件的时候,就出现了上面的问题。建议是在www.python.org/peps/pep-0263.html中查找原因
Leetcode 3144. Minimum Substring Partition of Equal Character Frequency
Leetcode 3144. Minimum Substring Partition of Equal Character Frequency 1. 解题思路2. 代码实现 题目链接:3144. Minimum Substring Partition of Equal Character Frequency 1. 解题思路 这一题的话思路上还是比较直接的,就是一个动态规划,这里就不过多展开了
处理字符串中的正则字符时报错:unterminated character class
需求是将某字符串中的正则特殊字符'{'替换为'\\{' 结果在relpace中报错:unterminated character class,如下代码: handleRegExp(str){let newStr=''let regs=['{','}','[',']','(',')']for(let reg of regs){if(str.indexO