本文主要是介绍语音合成论文优选:Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Trainin,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
本文为西北工业大学在2021.12.23更新的文章,主要做style迁移的研究,主要文章链接https://arxiv.org/pdf/2112.12743.pdf
(本文比较简单易懂,比近两年的以高深数学为基础的文章简单多了)
1 研究背景
语音合成的风格迁移主要让说话人合成该说话人本不具有的风格的语音,比如,让普通说话人合成故事、新闻、广播、朗读等等风格语音。为了使合成系统能够学习style的信息,以往的研究所使用的语料是一位说话人要具备多种风格的语料,这将对说话人提出较高的要求。本文为了解决以上的问题,设计了Multi-speaker Multi-style的合成系统,该系统的训练语料的每位说话人只要具备一种风格即可。而且本文对音素级别的细粒度的韵律进行控制,从而更容易对风格轻度进行控制。
2 详细设计
本文的系统是在tacotron2基础上进行修改,如图1所示。其中text based prosody module是控制style,speaker identity controller是控制音色。对于style的控制主要采用pitch, duration, and energy特征,即multi-scale prosody encoder的输入特征,其结构如图3所示。对于pitch, duration, and energy等特征的预测模型如图2所示,即使用文本特征对韵律特征进行预测。训练的loss如公式1所示。


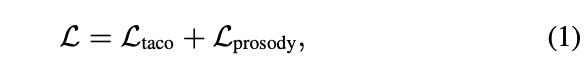
3 实验
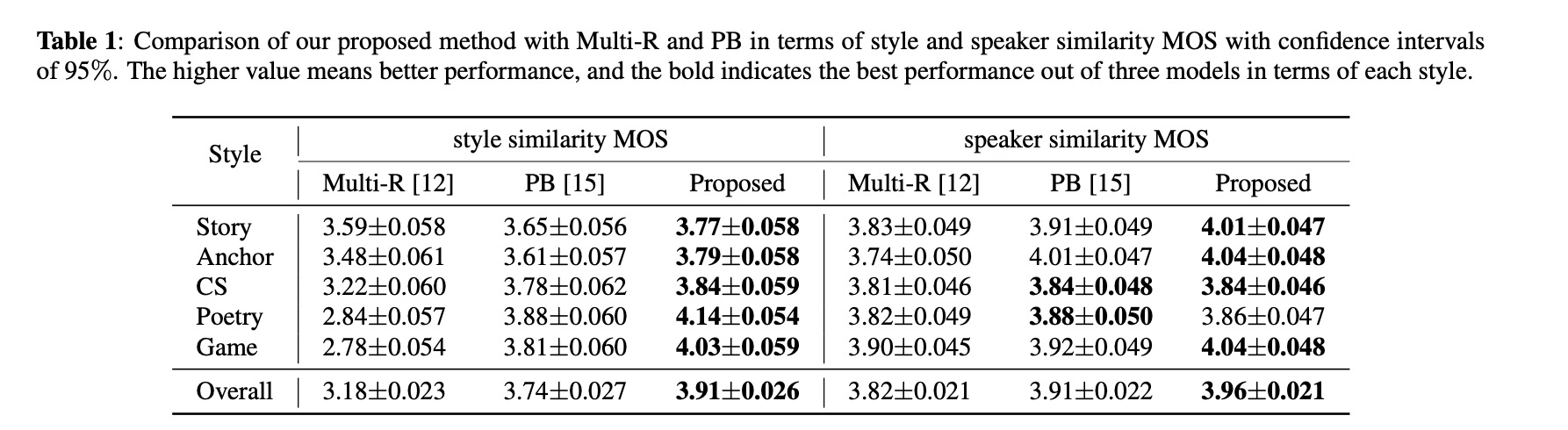
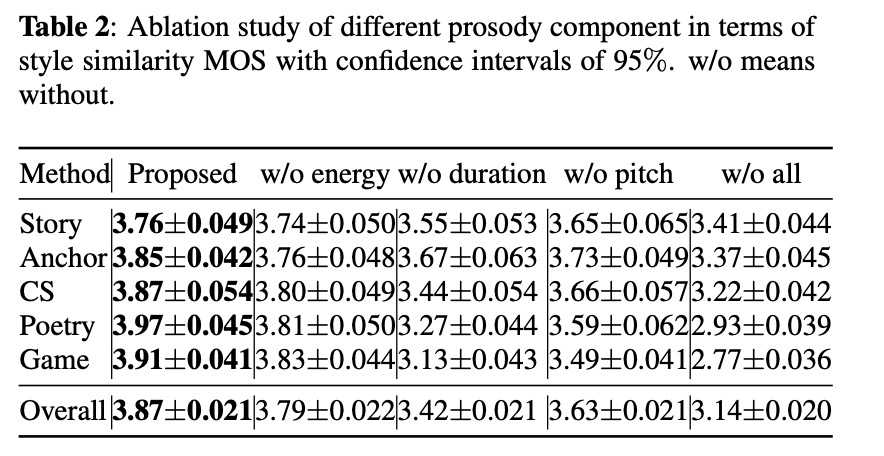
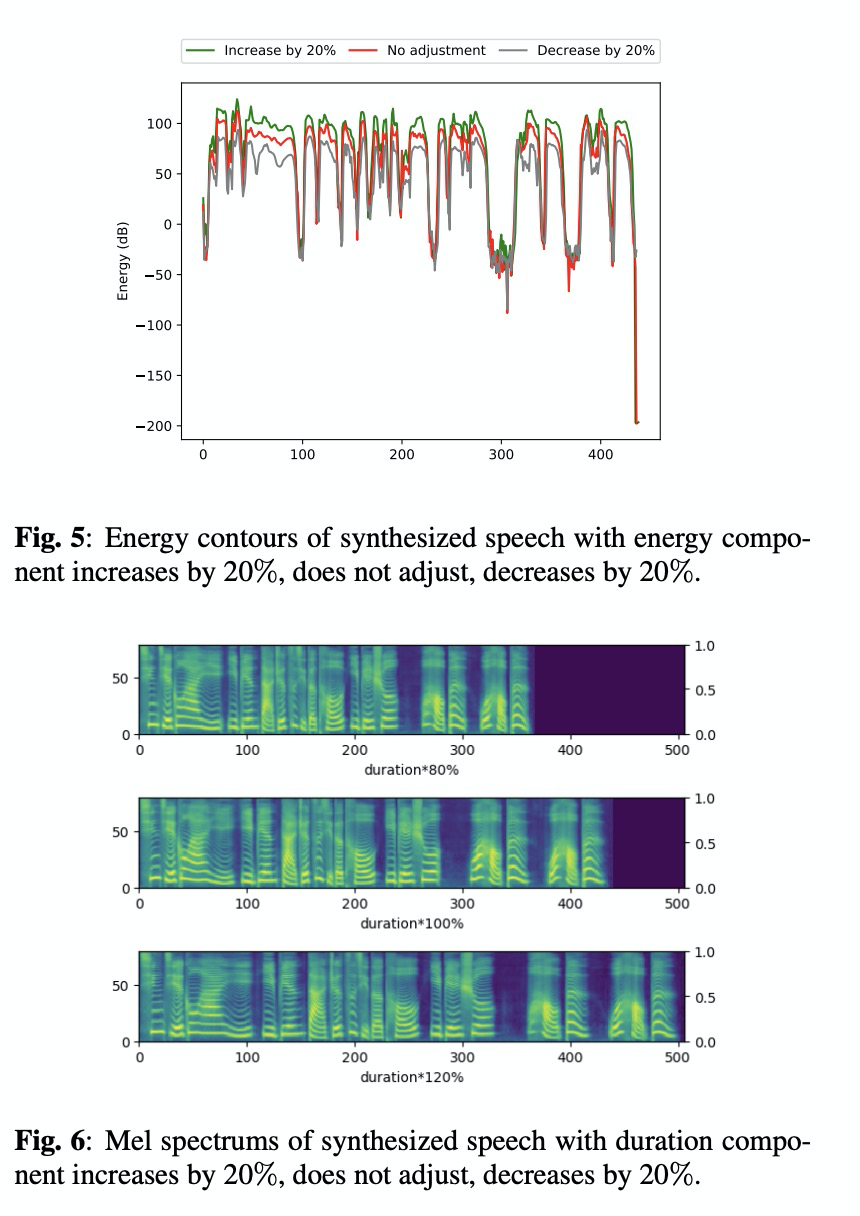
本文实验的数据具备的风格 reading, radio anchor, story telling, customer service (CS), poetry and game character。其对比的系统为 Multi-R and PB。对比的准则为style similarity mos和 speaker similarity mos。demo的链接https://qicongxie.github.io/SRM2TTS/。table 1对比的style similarity mos和 speaker similarity mos,由结果可知本文的方案的mos最高。Table 2展示了energy, pitch, duration对结果的影响状况。图4到图6展示了通过对energy, pitch, duration的大小调控对最终的合成特征的控制。

4 总结
本文使用单说话人单风格的语料来构建多说话人多风格的系统,从而降低了风格语音合成系统对训练数据的要求。而且本系统可以通过细粒度的韵律模块对风格进行调控。
这篇关于语音合成论文优选:Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Trainin的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





