speaker专题

基于Dragonboard 410c的mic和speaker的loopback调试
最进用dragonboard 410c做一个东西,其中用到了互相对话的功能,场景就是一个说一个听,可以对话,所以这就需要两个mic和两个speaker,还好410c的板子上面已经有两个mic的接口和一个speaker的接口了,经过测试mic是可以直接用的,speaker只有一个,那另一个怎么办呢?幸好HDMI是可以用的,另一个就走HDMI就可以了。这些问题解决后,最主要的还是loopback功

2016--AN EXTENSIBLE SPEAKER IDENTIFICATION SIDEKIT IN PYTHON
AN EXTENSIBLE SPEAKER IDENTIFICATION SIDEKIT IN PYTHON Anthony Larcher1, Kong Aik Lee2, Sylvain Meignier1 1LIUM - Universite ́ du Maine, France 法国 勒芒大学 2Human Language Technology Department, Institut

Tweet Speaker:一款Twitter消息朗读应用
北京时间 10 月9日消息,《 移动新发现》介绍一款针对 Twitter 研发的一款语音广播应用 Tweet Speaker,它能帮助用户朗读出 Twitter 最近的更新消息,随时随地让微博变成您的个人专属电台! 微博达人们往往都会遇到这样一个问题,自己希望无时无刻同微博联系在一起,但在跑步、开车等情景下却无暇关注,这些用户需求催生了 Tweet Speaker 这样的应用。
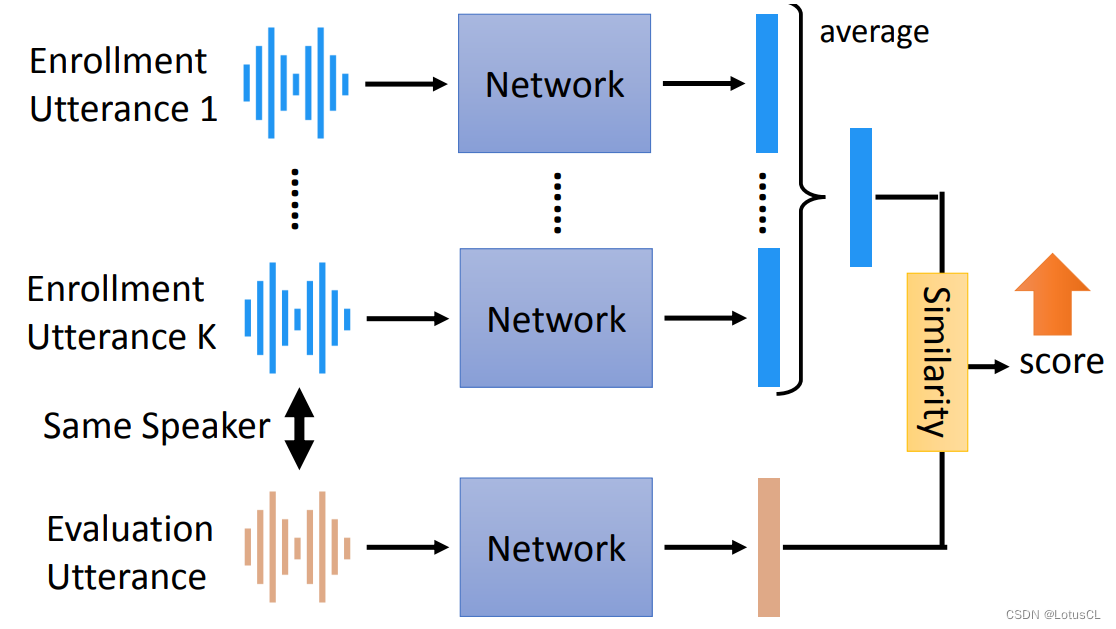
Speaker Verification,声纹验证详解——语音信号处理项目学习(九)
参考文献: Speaker Verification哔哩哔哩bilibili 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 声纹识别 - 16 - 知乎 (zhihu.com) (2) Meta Learning – Metric-based (1/3) - YouTube 如何理解等错误率(EER, Equal Error Rate)?请不要只给定义 - 知乎 (zhihu.com
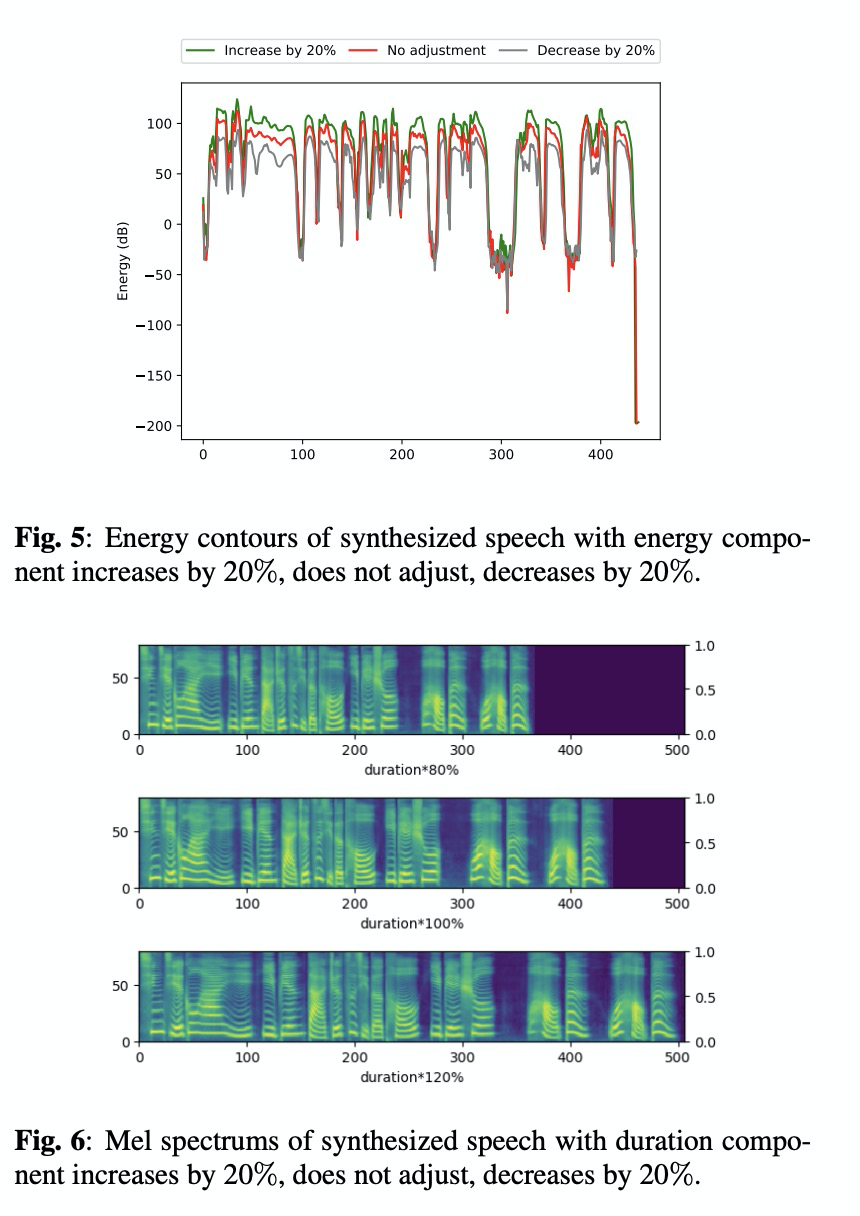
语音合成论文优选:Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Trainin
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章h

The NIST Year 2010 Speaker Recognition Evaluation Plan
The NIST Year 2010 Speaker Recognition Evaluation Plan 原文见: https://www.nist.gov/sites/default/files/documents/itl/iad/mig/NIST_SRE10_evalplan-r6.pdf 历年赛事结果查询: https://www.nist.gov/itl/iad/mig/speake
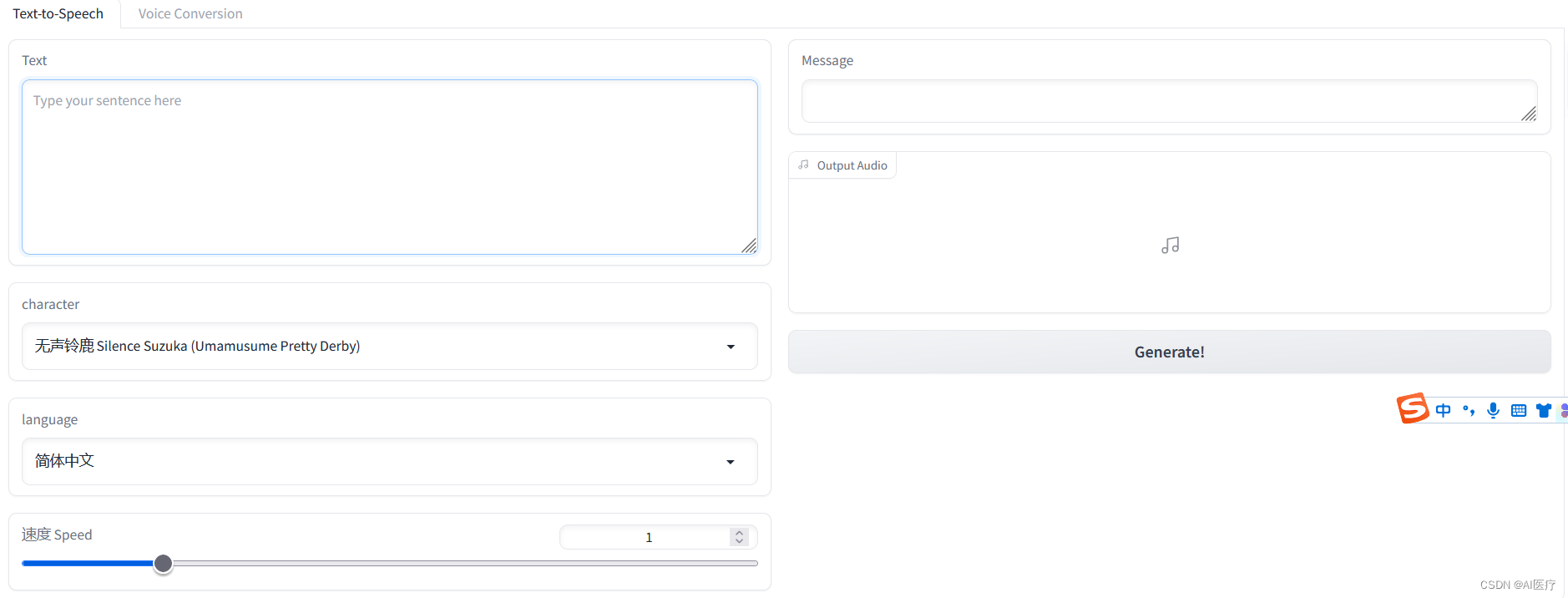
AI数字人:基于VITS-fast-fine-tuning构建多speaker语音训练
1 VITS模型介绍 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种语音合成方法,它使用预先训练好的语音编码器 (vocoder声码器) 将文本转化为语音。 VITS 的工作流程如下: (1)将文本输入 VITS 系
![mt6735 [Speaker Customization]添加外置PA等Speaker客制化问题整理](http://bbs.16rd.com/data/attachment/forum/201709/09/101825hfeyh6huek00ke4k.png)
mt6735 [Speaker Customization]添加外置PA等Speaker客制化问题整理
[DESCRIPTION] 对于MT6589、MT6572、MT6582的Speaker的客制化需求部分的一些整理。 一些可能的配置请参考下面的表格,Solution请根据序号参考对应的Solution. 外置PA的驱动,请参考如下方式完成:也可参考 [FAQ05881] [Audio Driver] 6589、6572、6582喇叭无声,软件上应该如何配置 把CUSTOM_KERNEL_SOU

SLT2021: LEARN2SING: TARGET SPEAKER SINGING VOICE SYNTHESIS BY LEARNING FROM A SINGING TEACHER
0. 题目 LEARN2SING: TARGET SPEAKER SINGING VOICE SYNTHESIS BY LEARNING FROM A SINGING TEACHER 学会唱歌: 目标说话人从一个歌唱老师那里学会唱歌(歌声合成) 1. 摘要 唱歌声合成已受到越来越多的关注 语音合成领域发展迅速。通常,为了从歌词和与音乐相关的录音, 乐谱等中产生自然的演唱声音,通常需要录
![[论文] End-to-End Text-Dependent Speaker Verification](https://img-blog.csdnimg.cn/20210705161429773.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUX3hpYW9f,size_16,color_FFFFFF,t_70#pic_center)
[论文] End-to-End Text-Dependent Speaker Verification
文章目录 Abstract1. Introduction2. Speaker Verification Protocol3. D-Vector Baseline Approach4. End-To-End Speaker Verification5. Experimental Evaluation5.1 Data Sets & Basic Setup5.2 Frame-Level vs. U