本文主要是介绍[论文] End-to-End Text-Dependent Speaker Verification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Abstract
- 1. Introduction
- 2. Speaker Verification Protocol
- 3. D-Vector Baseline Approach
- 4. End-To-End Speaker Verification
- 5. Experimental Evaluation
- 5.1 Data Sets & Basic Setup
- 5.2 Frame-Level vs. Utterance-Level Representation
- 5.3 Softmax vs. End-to-End Loss
- 5.4 Feedforward vs. Recurrent Neural Networks
- 6. Summary & Conclusion
Abstract
本文提出了一种数据驱动的、集成的说话人确认方法,**该方法将一个测试话语和几个参考话语直接映射到单个分数进行验证,并使用与测试时相同的评估协议和度量来联合优化系统的组件。**这样的方法将产生简单而高效的系统,几乎不需要特定领域的知识,也不需要做什么模型假设。我们通过将问题描述为一个单一的神经网络体系结构来实现这一想法,包括只在几个话语上估计说话人模型,并在我们内部的“OK Google”基准上进行评估,以进行文本相关的说话人验证。对于像我们这样需要高精度、易维护、占用空间小的系统的大数据应用程序,我们提出的方法似乎非常有效。
1. Introduction
说话人确认是根据说话人的已知话语来验证话语是否属于说话人的过程。当全部用户所说话语的词典(文本内容)被限制为单个单词或短语时,该过程被称为全局密码文本相关的说话人确认。文本相关的说话人确认通过限制词典来补偿语音的可变性,这给说话人确认带来了巨大的挑战。在Google,我们对使用全局密码“OK Google”的文本相关说话人确认感兴趣。选择这个特别短、大约0.6秒长的全局密码与Google Keyword Spotting System和Google VoiceSearch有关,并便于这两个系统的组合。
在本文中,我们提出将一个测试话语与几个话语一起直接映射到单个分数来建立说话人模型,以进行验证。遵循标准的说话人确认协议,使用基于确认的损失对所有组件进行联合优化。与现有的方法相比,这种端到端的方法可能有几个优点,包括从话语直接建模,这允许捕获远程上下文并降低复杂度(每个话语一个帧评估),以及直接和联合估计,这可以产生更好和更紧凑的模型。此外,这种方法通常导致需要更少概念和启发式的相当简单的系统。
具体地说,本文的贡献包括:·
- 建立端到端的说话人确认体系结构,包括基于几个话语评估说话人模型(第4节);
- 端到端说话人确认的经验评估,包括帧( i-vector、d-vector) 和话语级表示的比较(第5.2节)和端到端损失分析(第5.3节);
- 前馈神经网络和递归神经网络的经验比较(第5.4节)。
本文重点研究小样本文本相关的说话人确认,如文**[4]**中所讨论的那样。但是该方法更通用,可以类似地用于与文本无关的说话人确认。
在以前的研究中,确认问题被分解为更容易处理但联系松散的子问题。例如,i-vector和概率线性判别分析(PLDA) [5,6] 的组合已经成为文本无关说话人确认[5,6,7,8]和文本相关说话人确认[9,10,11]的主要方法。包括基于深度学习组件的混合方法也被证明对与文本无关的说话人识别是有益的[12,13,14]。然而,对于占用空间较小的系统,更直接的深度学习建模可能是一个有吸引力的选择[15,4]。据我们所知,递归神经网络已经被应用于说话人辨认[16]和语言识别[17]等相关问题,但还没有应用于说话人确认任务。所提出的神经网络结构可以被认为是一种生成性-判别性混合的联合优化,与深度展开[18]的适应精神是相同的。
论文的其余部分组织如下:第2节概述了说话人验证的一般情况。第3节介绍了d-vector。第4节介绍了所提出的端到端说话人确认方法。第5节进行了实验评价和分析,第6节对论文进行了总结。
2. Speaker Verification Protocol
标准的确认协议可以分为三个阶段:训练、注册和评估,我们将在下面更详细地描述这三个步骤。
训练:在训练阶段,我们从话语中找到合适的内部说话人表示,通过考虑一个简单的评分函数。通常,该表示取决于模型的类型(例如,高斯模型或深度神经网络)、表示级别(例如,帧或话语)以及模型训练损失(例如,最大似然或softmax)。最先进的表示是帧级别信息的汇总,例如 i-vector 和 d-vector。
注册:在注册阶段,说话人提供一些话语(参见表1),这些话语用于估计说话人模型。一种常见的选择是对这些话语的 i-vectors 或 d-vectors 进行平均。
评估:在评估阶段,执行确认任务并对系统进行评估。为了验证,将话语 X 和测试说话人spk 的打分函数的值 S ( X , s p k ) S(X,spk) S(X,spk) 与预设的阈值进行比较。如果分数超过阈值,即话语 X 来自说话人spk,我们接受,否则拒绝。在此设置中,可能会出现两种类型的错误:错误拒绝和错误接受。显然,错误拒绝率和错误接受率取决于阈值。当两个比率相等时,这个值称为等错误率(EER)。
一个简单的评分函数是评价话语 X 的说话人表示 f ( X ) f(X) f(X)(见段落“训练”)和说话人模型 m s p k m_{spk} mspk(见段落“注册”)之间的余弦相似度:
PLDA已被提议作为一种更精细的、数据驱动的评分方法。
3. D-Vector Baseline Approach

d-vectors 来自深度神经网络(DNN),作为话语的说话人表示。一个DNN由几个非线性函数的连续应用组成,以便将说话人的话语转换成易于做出决定的向量。图1描述了我们的基准DNN的拓扑结构。它包括一个局部连接层[4]和几个全连接层。除最后一层外,所有层都使用ReLu激活(非线性),最后一层是线性的。在训练阶段,使用Softmax损失来优化DNN的参数,为方便起见,我们将其定义为包括权重向量 w s p k w_{spk} wspk 和偏差 b s p k b_{spk} bspk 的线性变换,随后是Softmax函数和交叉熵损失函数:

其中,最后一个隐藏层的激活向量由 y 表示, s p k spk spk 表示正确的说话人。在所有训练的说话人 s p k ~ \tilde{spk} spk~上进行了标准化。
训练阶段结束后,DNN的参数就固定了。话语d-vectors是通过对话语的所有帧的最后隐藏层的激活向量求平均来获得的。每个话语生成一个d-vector。对于注册,说话人模型是注册话语的d-vectors的平均值。最后,在评价阶段,评分函数是说话人模型d-vector与测试话语的d-vector之间的余弦相似度。
对这种基准方法的批评包括从帧(窗口)获取的d-vector的有限上下文和损失的类型。Softmax损失试图区分真实说话人和所有竞争说话人,但不遵循第2节中的标准确认协议。
因此,需要启发式和评分标准化技术来补偿这种不一致。此外,Softmax损失不能随更多的数据很好地扩展,因为计算复杂度在训练说话人的数量中是线性的,并且需要每个说话人的最小数据量来估计说话人特定的权重和偏差。复杂性问题(但不是估计问题)可以通过候选采样[20]来缓解。
类似的担忧也存在于其他几种说话人确认方法中,其中一些组件块要么是松散连接的,要么就不是按照说话人确认协议直接优化的。例如,GMM-UBM[7]或i-vector模型不直接优化确认问题;PLDA[5]模型不遵循i-vector提取的改进;或者基于帧的GMM-UBM模型忽略较长的上下文特征。
4. End-To-End Speaker Verification
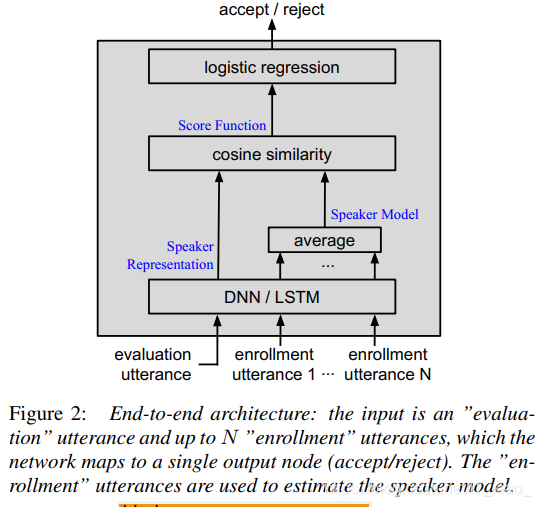
在这一节中,我们将说话人确认协议(第2节)的步骤集成到单个网络中,见图2。**该网络的输入由“评估”话语和一小组“注册”话语组成。输出是指示接受或拒绝的单个节点。**我们使用TensorFlow的前身DistBelef共同优化了这种端到端架构。在这两种工具中,都可以将复杂的计算图(如我们的端到端拓扑定义的图)分解为具有简单梯度的操作序列,如和、除和与向量的叉积。在训练步骤之后,除了人工调整注册数据的一维Logistic回归(图2)的偏差之外,所有的网络权重都保持不变。除此之外,由于说话人模型是网络的一部分,所以在注册步骤中不做任何事情。在测试时,我们将待测说话人的评价话语和注册话语喂给网络,网络直接输出决策。

我们通过神经网络获得说话人表示。我们在这项工作中使用的两种类型的网络如图1和图3所示:具有局部连接和完全连接层的深度神经网络(DNN)作为我们在第三节中的基线DNN,以及具有单一输出的长短期记忆递归神经网络(LSTM)。DNN假定输入长度固定。为了遵守这一限制,我们对话语将足够大的固定长度窗口的帧堆叠在一起,并将它们用作输入。LSTM不需要此技巧,但我们使用相同的帧窗口以获得更好的可比性。与具有多个输出的普通LSTM不同,我们只将最后一个输出与损失连接,以获得单个话语级别的说话人表示。
说话人模型是少数“注册”表示的平均值(第2节)。我们使用相同的网络来计算“测试”话语的内部表示和说话人模型的话语的内部表示。训练中每个说话人的实际可用话语数通常比注册时(少于10个)多得多(几百或更多),请参见表1。为了避免不匹配,我们只对每个训练话语采样同一说话人的几个话语,以在训练时建立说话人模型。一般来说,我们不能假设每个说话人有N个话语。为了允许可变数量的话语,我们将权重与话语一起传递,以指示是否使用该发声。
最后,我们计算说话人表示和说话人模型之间的余弦相似度 S ( X , s p k ) S(X,spk) S(X,spk),并将其提供给包含有偏差的线性层的Logistic回归。使用端到端损失对架构进行优化:
其中, t a r g e t ∈ { a c c e p t , r e j e c t } target \in \{accept,reject\} target∈{accept,reject}, p ( a c c e p t ) = ( 1 + e x p ( − w S ( X , s p k ) − b ) ) − 1 p(accept) = (1+exp(-wS(X,spk)-b))^{-1} p(accept)=(1+exp(−wS(X,spk)−b))−1, p ( r e j e c t ) = 1 − p ( a c c e p t ) p(reject)=1-p(accept) p(reject)=1−p(accept)。值 - b / w b/w b/w 对应于确认阈值。
端到端架构的输入是1+N个话语,即待测试的话语和同一说话人的用于估计说话人模型的最多N个不同话语。为了在数据打乱和记忆之间实现良好的折衷,输入层为每个训练步骤维护一个语音池以对1+N个语音进行采样,并频繁刷新以获得更好的数据打乱。由于说话人模型需要同一说话人的一定数量的话语,所以数据以同一说话人的话语的小分组呈现。
5. Experimental Evaluation
我们在我们内部的“OK Google”基准上评估了提出的端到端方法。
5.1 Data Sets & Basic Setup
我们在匿名语音搜索日志中收集的一组“OK Google”话语上测试了所提出的端到端方法。为了提高噪声的鲁棒性,我们进行了多种风格的训练。这些数据是通过人为添加不同SNR下的汽车和自助餐厅噪声,并模拟扬声器和麦克风之间的不同距离来扩大的,详情请参见[2]。注册和评估数据仅包括真实数据。表1显示了一些数据集统计数据。

话语被强制对齐以获得“OK Google”片段。对于100Hz的帧率,这些片段的平均长度约为80帧。基于这一观察,我们从每个片段中提取了最后80帧,可能会填充或截断片段开头的帧。每个帧由40个对数滤波器组组成(带有一些基本的谱减法)。
对于DNN,我们将80个输入帧连接起来,得到80x40维的特征向量。除非另有说明,否则DNN由4个隐藏层组成。DNN中的所有隐藏层都有504个节点,除了最后一层使用线性激活外,其他都使用ReLU激活。DNN局部连接层的块大小为10×10。对于LSTM,我们逐帧提供40维的特征向量。我们使用具有504个节点的单个LSTM层,而不使用投影层。所有实验的批次大小均为32。
结果以等错误率(EER)的形式报告,没有和有 t-norm 得分归一化[25]。
5.2 Frame-Level vs. Utterance-Level Representation
首先,我们比较帧级别和话语级别的说话人表示,参见表2。这里,我们使用如图1所示的具有Softmax层的DNN,并在线性层中具有50%的丢失率的train_2M(表1)上进行训练。**话语级方法的性能比帧级方法高30%。**在这两种情况下,分数归一化都能大幅提升性能(相对提升高达20%)。作为比较,展示了两条 i-vector 基准模型,第一个基准基于[6],使用具有一阶和二阶导数的13 PLPs、1024个高斯和300维i-vector。第二个基准基于[27]具有150维特征语音。对 i-vector+PLDA基准应该持保留态度,因为我们当前实现的限制,PLDA模型只在2M训练数据集(4k说话者和每个说话者50个话语)的子集上进行了训练。同样,基准模型没有使用提取精调技术。请注意,与[15]相比,我们显著改进了d-vector[4]。

5.3 Softmax vs. End-to-End Loss
接下来,我们比较了用于训练话语级说话人表示的Softmax损失(第2部分)和端到端损失(第4部分)。表3显示了图1中DNN的等错误率。
如果在小训练集(训练2M)上进行训练,对于不同的损失函数,原始分数上的错误率是相当的。
虽然dropout为Softmax提供了1%的绝对收益,但我们没有观察到端到端损失从dropout中获得的收益。同样,t-normalization (t归一化)对Softmax有20%的帮助,但对端到端损失毫无帮助。
如果在更大的训练集(序列22M)上进行训练,端到端损失明显优于Softmax,参见表3。
尽管因为说话人模型是动态计算的,端到端方法的步长比采用候选采样的Softmax方法的步长要大,但总体收敛时间是相当的。
被称为说话人模型大小的用于估计训练中的说话人模型的话语数量的最佳选择取决于注册话语的平均)数量。然而,在实践中,较小的说话人模型尺寸可能更有吸引力,以减少训练时间,但也使训练变得更加困难。图4显示了测试的等错误率对说话人模型大小(即,用于估计说话人模型的话语数量)的依赖性。在模型大小为 5 的情况下,存在一个相对较宽的最优模型,错误率为2.04%,而模型大小为1时的错误率为2.25%。此模型大小接近真实的平均模型大小,即我们的注册集的平均模型大小为6。本文中的其他配置也有类似的趋势(未显示)。这表明所提出的训练算法与确认协议的一致性,并表明特定于任务的训练倾向于更好。
5.4 Feedforward vs. Recurrent Neural Networks
到目前为止,我们关注的是图1中具有一个局部连接和三个完全连接的隐藏层的“小足迹”DNN。
接下来,我们将探索更大、更不同的网络架构,而不考虑其大小和计算复杂性。表4总结了这些结果。与占用空间较小的DNN相比,最好的DNN使用了额外的隐藏层,并得到了10%的相对收益。图3中的**LSTM在此最佳DNN上又增加了30%的提升。参数的数量与DNN相当,但LSTM涉及的乘法和加法大约是DNN的十倍。**更多的超参数调优有望进一步降低计算复杂度,使其变得可行。
6. Summary & Conclusion
我们提出了一种新的端到端说话人确认方法,该方法直接将话语映射到分数,并利用相同的损失进行训练和评估,联合优化内部说话人表示和说话人模型。假设有足够的训练数据,在我们内部的“OK Google”基准上,提出的方法将我们最好的小容量DNN基准从3%改进到2%的等错误率。大部分增益来自话语级与帧级建模。与其他损失相比,端到端损失取得了相同或略好的结果,但增加的概念更少。例如,在Softmax的情况下,只有在运行时使用分数归一化,候选抽样使训练可行,以及在训练中dropout时,我们才能获得类似的错误率。此外,我们还表明,使用递归神经网络而不是简单的深度神经网络可以将等错误率进一步降低到1.4%,尽管计算时间开销较高。相比之下,合理但不是完全最先进的i-vector/PLDA系统的等错误率是4.7%。显然,还需要更多的比较研究。然而,我们相信我们的方法为大数据验证应用提供了一个很有前途的新方向。
这篇关于[论文] End-to-End Text-Dependent Speaker Verification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

