本文主要是介绍The NIST Year 2010 Speaker Recognition Evaluation Plan,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
The NIST Year 2010 Speaker Recognition Evaluation Plan
原文见:
https://www.nist.gov/sites/default/files/documents/itl/iad/mig/NIST_SRE10_evalplan-r6.pdf
历年赛事结果查询:
https://www.nist.gov/itl/iad/mig/speaker-recognition
文章目录
- 1 INTRODUCTION
- 2 TECHNICAL OBJECTIVE
- 2.1 Task Definition
- 2.2 Task Conditions
- 2.2.1 Training Conditions
- 2.2.3 Training/Segment Condition Combinations
- 3 PERFORMANCE MEASURE
- 4 EVALUATION CONDITIONS
- 4.1 Training Data
- 4.1.1 10-second Excerpts
- 4.1.2 Two-channel Conversations
- 4.1.3 Interview Segments
- 4.1.4 Summed-channel Conversations
- 4.2 Test data
- 4.2.1 10-second Excerpts
- 4.2.2 Two-channel Conversations
- 4.2.3 Interview Segments
- 4.2.4 Summed-channel Conversations
- 4.3 Factors Affecting Performance
- 4.4 Common Evaluation Condition
- 4.5 Comparison with Previous Evaluations
- 5 DEVELOPMENT DATA
- 6 EVALUATION DATA
- 6.1 Numbers of Models
- 6.2 Numbers of Test Segments
- 6.3 Numbers of Trials
- 7 EVALUATION RULES
- 8 EVALUATION DATA SET ORGANIZATION
- 8.1 data Sub-directory
- 8.2 train Sub-directory
- 8.3 trials Sub-directory
- 8.4 doc Sub-directory
- 9 SUBMISSION OF RESULTS
- 9.1 Format for Results
- 9.2 Means of Submission
- 10 SYSTEM DESCRIPTION
- 11 HASR TEST
- 11.1 Trials and Data
- 11.2 Rules
- 11.3 Scoring
- 11.4 Submissions
- 12、SCHEDULE
- 13 GLOSSARY
1 INTRODUCTION
The year 2010 speaker recognition evaluation is part of an ongoing series of evaluations conducted by NIST.
2010年说话人识别评估比赛(SRE)是NIST正在进行的一系列比赛的一部分。
These evaluations are an important contribution to the direction of research efforts and the calibration of technical capabilities.
这些比赛对指导SRE,研究方向和技术能力的校准,做出了重要贡献。
They are intended to be of interest to all researchers working on the general problem of text independent speaker recognition.
这个比赛希望引起,所有,研究文本无关说话人识别,一般问题的,研究人员的兴趣。
To this end the evaluation is designed to be simple, to focus on core technology issues, to be fully supported, and to be accessible to those wishing to participate.
为此目的,这个评估比赛设计的很简单,重点关注在核心技术问题上,所有参赛人员都会得到充分的支持,报名参赛也很容易。
The 2010 evaluation will be similar to that of 2008 but different from prior evaluations by including in the training and test conditions for the core (required) test not only conversational telephone speech recorded over ordinary (wired or wireless) telephone channels, but also such speech recorded over a room microphone channel, and conversational speech from an interview scenario recorded over a room microphone channel.
2010年评估比赛将类似于2008年的,但是不同于之前的是,训练集和测试集都是,不仅有电话录音(有线或无线),还有房间里的交谈录音,和在一个访谈环境下的交谈录音。
But unlike in 2008 and prior evaluations, some of the data involving conversational telephone style speech will have been collected in a manner to produce particularly high, or particularly low, vocal effort on the part of the speaker of interest.
但与2008年和之前的评估比赛不同的是,一些涉及电话式对话的录音,将以一种特别高或特别低的方式收集,看说话者的兴趣了。
Unlike 2008, the core test interview segments will be of varying duration, ranging from three to fifteen minutes.
与2008年不同的是,核心语音段的时长各不相同,从3分钟到15分钟不等。
Systems will know whether each segment comes from a telephone or a microphone channel, and whether it involves the interview scenario or an ordinary telephone conversation, but will be required to process trials involving all segments of each type.
系统将知道每短语音是来自电话还是麦克风通道,以及它是否涉及interview场景或普通电话对话场景,但每种类型都需要试验。
Systems will not know a-priori the elicited level of vocal effort in the conversational telephone style speech.
系统不会预先知道在电话会话式讲话中所引出的声音努力程度。
Submitted results will be scored after the fact to determine performance levels for telephone data, for microphone data of different conversational styles and microphone types, for conversational telephone style data of different levels of vocal effort, and for differing combinations of training and test data.
提交的结果将在事后进行评分,以确定电话数据、不同会话风格和麦克风类型的麦克风数据、不同语音努力级别的会话电话风格数据以及不同的训练和测试数据组合的性能水平。
The 2010 evaluation will primarily use recently collected speech data from speakers not included in previous evaluations, but will also include some old and new conversational telephone speech segments from speakers in various past evaluations.
2010年的评估将主要使用以前评估中没有包括的发言者最近收集的语音数据,但也将包括过去各种评估中发言者的一些新老会话电话语音片段。
Some new speech has recently been collected from speakers appearing in earlier evaluations, and this will support examination in this evaluation of the effect of the time interval between training and test on performance.
最近从早期评估中出现的发言者中收集了一些新的讲话,这将支持在评估训练和测试之间的时间间隔对绩效的影响时进行检查。
Unlike recent evaluations, all of the speech in the 2010 evaluation is expected to be in English, though English may not be the first language of some of the speakers included.
与最近的评估不同,2010年评估中的所有演讲都将使用英语,尽管英语可能不是其中一些演讲者的第一语言。
The 2010 evaluation will include an alternative set of parameters for the evaluation performance measure, to be implemented along with the parameter values used in the past evaluations.
2010年评估将包括用于评估性能度量的一组备选参数,将与过去评估中使用的参数值一起实施。
This is discussed in section 3.
这将在第3节中讨论。
The evaluation will include 9 different speaker detection tests defined by the duration and type of the training and test data.
评估将包括9种不同的说话人检测测试,这些测试由训练和测试数据的持续时间和类型定义。
Three-conversation training will not be included this year, and the summed-channel 3-conversation training condition will be replaced with a summed-channel 8-conversation training condition.
3人对话的训练今年将不包括在内,并将summed-channel 3-conversation训练条件替换为summed-channel 8-conversation训练条件。
Because of the changed performance measure, and limited participation in past evaluations, the unsupervised adaptation condition will not be included in the 2010 evaluation.
由于衡量标准的变化,以及过去评估中的限制,2010年评估将不包括无监督适应条件。
The 2010 evaluation will also include a Human Assisted Speaker Recognition (HASR) test.
2010年的评估还将包括一个辅助说话人识别(HASR)测试。
This is described in section 11, and will consist of a limited number of trials, which will be a subset of the main evaluation trials.
这将在第11节中进行描述,并将包括有限数量的试验,这些试验将是主要评价试验的一个子集。
It is intended to test the capabilities of speaker recognition systems involving human expertise, possibly combined with automatic processing.
它的目的是测试涉及人类专业知识的说话人识别系统的能力,并可能与自动处理相结合。
Those participating in this test are not required to also do the core test otherwise required of all evaluation participants.
参加测试的人不需要做核心测试,否则所有评估参与者都需要做核心测试。
The evaluation will be conducted from March to May of 2010 (HASR data will be available in February of 2010).
评估将于2010年3月至5月进行(HASR数据将于2010年2月提供)。
A follow-up workshop for evaluation participants to discuss research findings will be held June 24-26 in Brno, the Czech Republic.
将于6月24日至26日在捷克共和国布尔诺举行评价参加者讨论研究结果的后续讲习班。
Specific dates are listed in the Schedule (section 12).
具体日期见附表(第12条)。
Participation in the evaluation is invited for all sites that find the tasks and the evaluation of interest.
邀请所有对任务感兴趣的人来参加。
Participating sites must follow the evaluation rules set forth in this plan and must be represented at the evaluation workshop (except for HASR-only participants as described in section 11.2).
参与者必须遵守本计划中规定的评估规则,并且必须在评估研讨会上有代表(除了第11.2节中描述的只有hasr的参与者)。
For more information, and to register to participate in the evaluation, please contact NIST.1
如需更多信息,并报名参加评估,请联系nists .1
Send email to speaker_poc@nist.gov, or call 301/975-3605. Each site must complete the registration process by signing and returning the registration form, which is available online at: . http://www.itl.nist.gov/iad/mig/tests/sre/2010/NIST_SRE10_agreement_v1.pdf
2 TECHNICAL OBJECTIVE
2、技术目标
This evaluation focuses on speaker detection in the context of conversational speech over multiple types of channels.
本评估的重点是在多渠道的会话语音环境下的说话人检测。
The evaluation is designed to foster research progress, with the goals of:
评估的目的是促进研究进展,目标是:
Exploring promising new ideas in speaker recognition.
探索说话人识别的新思路。
Developing advanced technology incorporating these ideas.
利用这些思想发展先进技术。
Measuring the performance of this technology.
衡量这项技术的性能。
2.1 Task Definition
2.1任务定义
The year 2010 speaker recognition evaluation is limited to the broadly defined task of speaker detection.
2010年度说话人识别评估仅限于广义的说话人检测任务。
This has been NIST’s basic speaker recognition task over the past fourteen years.
这是NIST在过去14年里的基本说话人识别任务。
The task is to determine whether a specified speaker is speaking during a given segment of conversational speech.
其任务是确定特定的说话者是否在给定的会话语音片段中说话。
2.2 Task Conditions
2.2任务条件
The speaker detection task for 2010 is divided into 9 distinct and separate tests.
2010年的speaker检测任务分为9个不同的测试。
(The HASR test, discussed in section 11, is not included here.)
(第11节中讨论的HASR测试不包括在这里。)
Each of these tests involves one of 4 training conditions and one of 3 test conditions.
每个测试都涉及4种训练条件和3种测试条件中的一种。
One of these tests (see section 2.2.3 below) is designated as the core test.
其中一个测试(参见下面的2.2.3节)被指定为核心测试。
Participants must do the core test (except those doing only the HASR test) and may choose to do any one or more of the other tests.
参与者必须做核心测试(除了那些只做HASR测试的人),并且可以选择做任何一个或多个其他测试。
Results must be submitted for all trials included in each test for which any results are submitted.
所有提交结果的试验都必须提交结果。
2.2.1 Training Conditions
2.2.1Training条件
The training segments in the 2010 evaluation will be continuous conversational excerpts.
2010年评估中的培训部分将是连续的对话节选。
As in recent evaluations, there will be no prior removal of intervals of silence.
在最近的评估中,将不会事先消除静音。
Also, except for summed channel telephone conversations as described below, two separate conversation channels will be provided (to aid systems in echo cancellation, dialog analysis, etc.).
此外,除了如下所述的汇总通道电话会话外,还将提供两个单独的会话通道(以帮助系统进行回声消除、对话分析等)。
For all such two-channel segments, the primary channel containing the target speaker to be recognized will be identified.
对于所有这样的双信道段,将识别包含要识别的目标说话人的主信道。
The four training conditions to be included involve target speakers defined by the following training data:
将列入的四项训练条件涉及下列训练数据所界定的目标发言者:
1.10-sec: A two-channel excerpt摘录 from a telephone conversation estimated to contain approximately 10 seconds of speech of the target on its designated side.
1.10秒:从一段电话交谈中截取的两通道会话,估计包含目标方大约10秒的讲话。
(An energy-based automatic speech detector will be used to estimate the duration of actual speech in the chosen excerpts.)
(一个基于能量的自动语音探测器将被用来估计实际语音的持续时间在选择的摘录。)
2.core: One two-channel telephone conversational excerpt, of approximately five minutes total duration, with the target speaker channel designated or a microphone recorded conversational segment of three to fifteen minutes total duration involving the interviewee (target speaker) and an interviewer.
2.核心:一个两通道的电话会话摘录,总时长约5分钟。(Each conversation side will consist of five minutes of a longer conversation, and will exclude the first minute. This will eliminate from the evaluation data the less-topical introductory dialogue, which is more likely to contain language that identifies the speakers.)指定的目标说话人通道或麦克风记录了涉及被采访者(目标说话人)和采访者的会话片段,总时长为3到15分钟。
In the former case the designated channel may either be a telephone channel or a room microphone channel;
在前一种情况下,指定的信道可以是电话信道或房间麦克风信道;
the other channel will always be a telephone one.
另一个信道永远是电话信道。
In the latter case the designated microphone channel will be the A channel, and most of the speech will generally be spoken by the interviewee, while the B channel will be that of the interviewer’s head mounted close-talking microphone, with some level of speech spectrum noise added to mask any residual speech of the target speaker in it.
在后一种情况下指定的麦克风通道将是A通道,而且大部分的话语通常会被,被采访者说,而B通道将面试官的头部安装close-talking麦克风,添加了某种程度的语音频谱噪声,来掩盖。。。。。
3.8conv: Eight two-channel telephone conversation excerpts involving the target speaker on their designated sides.
3.8conv:八段双通道电话对话摘录,涉及目标说话人。
4.8summed: Eight summed-channel excerpts from telephone conversations of approximately five minutes total duration formed by sample-by-sample summing of their two sides.
4.8段会话合在一起的:通过对双方的样本逐一进行总结,总结出八段总时长约为五分钟的电话对话。
Each of these conversations will include both the target speaker and another speaker.
每个对话都包括目标说话者和另一个说话者。
These eight non-target speakers will all be distinct.
这8位非目标说话者都是不同的人。
Word transcripts (always in English), produced using an automatic speech recognition (ASR) system, will be provided for all training segments of each condition.
使用自动语音识别(ASR)系统生成的transcripts(英语)将提供每个条件下的所有训练片段的翻译。
These transcripts will, of course, be errorful, with English word error rates typically in the range of 15- 30%.
当然,这些文字记录会是有错误的,英语单词错误率通常在15- 30%之间。
Note, however, that the ASR system will always be run on two separated channels, and run only once for those segments that have been simultaneously recorded over multiple channels, and the ASR transcripts provided may sometimes be superior to what current systems could provide for the actual channel involved.
然而,请注意,ASR系统将始终在两个独立的通道上运行,并且对于那些同时在多个通道上记录的片段只运行一次,并且所提供的ASR转录本有时可能比当前系统所提供的实际所涉及的通道要好。
This is viewed as reasonable since ASR systems are expected to improve over time, and this evaluation is not intended to test ASR capabilities.
这被认为是合理的,因为ASR系统预计会随着时间的推移而改进,而本次评估比赛并不打算测试ASR能力。
For the interview segments, the provision条款 of the interviewer’s head- mounted close-talking microphone signal in a time aligned second channel, with speech spectrum noise added to mask any residual speech of the interviewee, is intended to assist systems in doing speaker separation, such as by using a speech detector to determine and remove from processing the time intervals where the interviewer is speaking.
面试部分,面试官的头部安装的close-talking麦克风信号被排列在第二通道,添加了语音谱噪声来掩盖。。。,旨在协助系统做说话者分离,如,通过使用语音检测器来消除说话的时间间隔。
2.2.2 Test Segment Conditions 这个和上面训练数据的条件很相似
The test segments in the 2010 evaluation will be continuous conversational excerpts. As in recent evaluations, there will be no prior removal of intervals of silence. Also, except for summed channel telephone conversations as described below, two separate conversation channels will be provided (to aid systems in echo cancellation, dialog analysis, etc.). For all such two-channel segments, the primary channel containing the putative target speaker to be recognized will be identified.
The three test segment conditions to be included are the following:
1.10-sec: A two-channel excerpt from a telephone conversation estimated to contain approximately 10 seconds of speech of the putative target speaker on its designated side (An energy-based automatic speech detector will be used to estimate the duration of actual speech in the chosen excerpts.)
2.core: One two-channel telephone conversational excerpt, of approximately five minutes total duration, with the target speaker channel designated or a microphone recorded conversational segment of three to fifteen minutes total duration involving the interviewee (speaker of interest) and an interviewer. In the former case the designated channel may either be a telephone channel or a room microphone channel; the other channel will always be a telephone one. In the latter case the designated microphone channel will be the A channel, and most of the speech will generally be spoken by the interviewee, while the B channel will be that of the interviewer’s head mounted close-talking microphone, with some level of speech spectrum noise added to mask any residual speech of the target speaker in it.
3.summed: A summed-channel telephone conversation of approximately five minutes total duration formed by sample-by-sample summing of its two sides
Word transcripts (always in English), produced using an automatic speech recognition (ASR) system as described in section 2.2.1, will be provided for all test segments of each condition.
For the interview segments, the provision of the interviewer’s head mounted close-talking microphone signal in a time aligned second channel, with speech spectrum noise added to mask any residual speech of the interviewee, is intended to assist systems in doing speaker separation, such as by using a speech detector to determine and remove from processing the time intervals where the interviewer is speaking.
2.2.3 Training/Segment Condition Combinations
2.2.3Training /段条件组合
The matrix of training and test segment condition combinations is shown in Table 1.
训练和测试段条件组合矩阵如表1所示。
Note that only 9 (out of 12) of the possible condition combinations will be included in this year’s evaluation.
请注意,在今年的评估中,可能的条件组合只有9种(12种)。
Each test consists of a sequence of trials, where each trial consists of a target speaker, defined by the training data provided, and a test segment.
每个测试由一系列试验组成,其中每个试验由一个目标说话者(由提供的训练数据定义)和一个测试部分组成。
The system must decide whether speech of the target speaker occurs in the test segment.
系统必须判断目标说话人的语音是否出现在测试段中。
The shaded box labeled “required” in Table 1 is the core test for the 2010 evaluation.
表1中标记为“required”的阴影框是2010年评估的核心测试。
All participants (except those doing HASR only) are required to submit results for this test.
所有的参与者(除了那些只做HASR的)都被要求提交这个测试的结果。
Each participant may also choose to submit results for all, some, or none of the other 8 test conditions.
每个参与者也可以选择提交全部、部分或全部8个测试条件的结果。
For each test for which results are submitted, results for all trials must be included.
对于提交结果的每个测试,必须包括所有试验的结果。

3 PERFORMANCE MEASURE
3、性能测量
Each trial of each test must be independently judged as “true” (the model speaker speaks in the test segment) or “false” (the model speaker does not speak in the test segment), and the correctness of these decisions will be tallied。
每个测试的每个试验必须独立判断为“正确”(说话者在测试段说话)或“错误”(说话者不在测试段说话),以及这些决定的正确性将予以记录。(This means that an explicit speaker detection decision is required for each trial. Explicit 清晰的,明确的 decisions are required because the task of determining appropriate decision thresholds is a necessary part of any speaker detection system and is a challenging research problem in and of itself.)
There will be a single basic cost model for measuring speaker detection performance, to be used for all speaker detection tests.
将有一个基本的cost模型来衡量说话人检测性能,将用于所有说话人检测测试。
In 2010, however, for two of the test conditions (including the core condition), there will be a new set of parameter values used to compute the detection cost over the test trials.
然而在2010年,对于两个测试条件(包括核心条件),将会有一组新的参数用于计算测试试验的检测成本。
The old parameter values used in previous evaluations will be used for the other conditions and will also be computed for these two conditions, thus supporting historical comparisons with past evaluations.
在以前的评估中使用的旧参数值将用于其他条件,并将为这两个条件计算,从而支持与过去比赛的历史记录比较。
This detection cost function is defined as a weighted sum of miss and false alarm error probabilities:
该检测成本函数定义为失误率和误报概率的加权和:

For the core test, and for the “train on 8conv/test on core” condition (see section 2.2.3), the parameter values in Table 2 will be used as the primary evaluation metric of speaker recognition performance.
对于core测试,对于“train on 8conv/test on core”条件(参见第2.2.3节),表2中的参数值将作为说话人识别性能的主要评价指标。
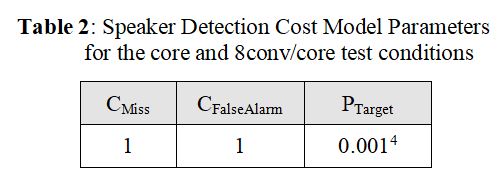
These parameters differ from those used in prior NIST SRE evaluations.
这些参数与之前NIST SRE评估中使用的参数不同。
The parameters for the historical cost function, which will be the primary metric in 2010 for the other test conditions, are specified in Table 3.
以前的cost function是2010年其他测试条件(非core测试)的主要度量,其参数如表3所示。

To improve the intuitive meaning of CDet, it will be normalized by dividing it by the best cost that could be obtained without processing the input data (i.e.
为了提高CDet的直观意义,将其除以…数据(即
, by either always accepting or always rejecting the segment speaker as matching the target speaker, whichever gives the lower cost):
,要么一直接受,要么一直拒绝与目标说话人相匹配的部分说话人,以成本较低者为准):

In addition to the actual detection decision, a score will also be required for each test hypothesis.
除了实际的检测决策外,每个测试假设还需要一个分数。
This score should reflect the system’s estimate of the probability that the test segment contains speech from the target speaker.
这个分数应该反映系统对测试段包含目标说话者的语音的概率的估计。
Higher scores should indicate greater estimated probability that the target speaker’s speech is present in the segment.
分数越高,表示目标说话者的演讲出现在该片段中的估计概率越大。
The scores will be used to produce Detection Error Tradeoff (DET) curves, in order to see how misses may be traded off against false alarms.
这些分数将被用来产生检测误差权衡(DET)曲线,以了解miss如何与false alarm进行权衡。
Since these curves will pool all trials in each test for all target speakers, it is necessary to normalize the scores across all target speakers.
由于这些曲线将在每个测试中汇集所有目标说话人的所有试验,因此有必要对所有目标说话人的分数进行标准化。
NIST traditionally reports for each evaluation system the actual normalized CDet score as defined above, and the minimum possible such score based on the DET curve, assuming perfect calibration.
NIST传统上报告每个评估系统的实际归一化CDet评分,如上述定义,以及基于DET曲线的最小可能的此类评分,假设有完美的校准。
For historical continuity with respect to the core test and the train on 8conv/test on core condition NIST will report this minimum score for both the new and historical cost functions for these conditions.
为了保持核心测试的历史连续性,NIST将报告这些条件下的新成本函数和历史成本函数的最低得分。
The ordering of the scores is all that matters for computing the detection cost function, which corresponds to a particular application defined by the parameters specified above, and for plotting DET curves.
分数的排序是计算检测成本函数和绘制DET曲线的关键,检测成本函数对应于由上述指定的参数定义的特定应用程序。
But these scores are more informative, and can be used to serve any application, if they represent actual probability estimates.
但这些分数信息更丰富,如果它们代表实际的概率估计,可以用于任何应用程序。
It is suggested that participants provide as scores estimated log likelihood ratio values (using natural logarithms), which do not depend on the application parameters.
建议参与者提供不依赖于应用参数的对数似然比估计值(使用自然对数)作为分数。
In terms of the conditional probabilities for the observed data of a given trial relative to the alternative target and non-target hypotheses the likelihood ratio (LR) is given by:
对于给定试验观测数据相对于备选目标和非目标假设的条件概率,似然比(LR)为:

Sites are asked to specify if their scores may be interpreted as log likelihood ratio estimates.
参赛者被要求详细说明他们的分数是否可以解释为log似然比估计。
A further type of scoring and graphical presentation will be performed on submissions whose scores are declared to represent log likelihood ratios.
更进一步的的评分和图表presentation将被要求,如果提交者的分数被声明为log似然比。
A log likelihood ratio (llr) based cost function, which is not application specific and may be given an information theoretic interpretation, is defined as follows:
基于对数似然比(llr)的成本函数定义为:
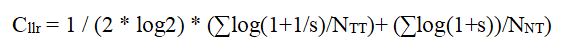
where the first summation is over all target trials, the second is over all non-target trials, NTT and NNT are the total numbers of target and non-target trials, respectively, and s represents a trial’s likelihood ratio.5
其中第一个总和为所有目标试验,第二个总和为所有非目标试验,NTT和NNT分别为目标试验和非目标试验的总数,s为试验的似然比
Graphs based on this cost function, somewhat analogous to DET curves, will also be included.
基于这个成本函数的图形,有点类似于DET曲线,也将包括在内。
These may serve to indicate the ranges of possible applications for which a system is or is not well calibrated.6
这些参数可以用来表示一个系统是否经过良好校准的可能应用范围
4 EVALUATION CONDITIONS
4、评估条件
Performance will be measured, graphically presented, and analyzed, as discussed in section 3, over all the trials of each of the 9 tests specified in section 2.2.3, and over subsets of these trials of particular evaluation interest.
如第3节所述,将在第2.2.3节中指定的9个试验的所有试验中,以及在这些试验的特定评价兴趣的子集中,对性能进行测量、图形化描述和分析。
Comparisons will be made of performance variation across the different training conditions and the different test segment conditions which define these tests.
比较不同的训练条件和定义这些测试的不同测试段条件下的性能差异。
The effects of extrinsic (channel) factors such as telephone transmission type, and microphone type, will be examined.
外部(渠道)因素的影响,如电话传输类型,麦克风类型,将进行检查。
The effects of intrinsic (speaker) factors such as sex, age, and native English speaking status will also be examined.
此外,还将考察性别、年龄和英语母语者地位等内在(说话者)因素的影响。
Speaking style factors, including conversational telephone vs. interview speech and the effects of high or low vocal effort will be investigated.
说话风格的因素,包括谈话电话和面试演讲和高或低的声音努力的影响将被调查。
We will also examine performance as a function of the time interval between the recording of training and test (target speaker) segments.
我们还将研究表现作为记录训练和测试(目标说话者)部分之间的时间间隔的函数。
Several common evaluation conditions of interest, each a subset of the core test, will be defined.
将定义几个常见的评估条件,每个条件都是核心测试的子集。
And relevant comparisons will be made between this year’s evaluation results and those of recent past years.
并将今年的评价结果与最近几年的评价结果作相应的比较。
4.1 Training Data
4.1 训练数据
As discussed in section 2.2.1, there will be four training conditions.
如第2.2.1节所述,将有四种训练条件。
NIST is interested in examining how performance varies among these conditions for fixed test segment conditions.
NIST感兴趣的是在固定的测试段条件下,研究这些条件之间的性能变化。
The sex of each target speaker will be provided to systems (see section Error!
每个目标说话人的性别将提供给系统(见Error! Reference source not found!)
Reference source not found.), but other emographic information will not be.
但是其他的表情信息将不会被找到。
For all training conditions, English language ASR transcriptions of all data will be provided along with the audio data.
对于所有的训练条件,所有数据的英语ASR转录将与音频数据一起提供。
Systems may utilize this data as they wish.
系统可以根据需要使用这些数据。
The acoustic data may be used alone, the transcriptions may be used alone, or all data may be used in combination.
声学数据可以单独使用,转录可以单独使用,或所有数据可以组合使用。
4.1.1 10-second Excerpts
4.1.1 10-second摘录
As discussed in section 2.2.1, one of the training conditions is an excerpt of a telephone conversation containing approximately 10 seconds of estimated speech duration in the channel of interest.
如第2.2.1节所讨论的,其中一个训练条件是一段电话对话的摘录,其中包含了在感兴趣的频道中估计的大约10秒钟的说话时间。
The actual duration of target speech will vary (so that the excerpts include only whole turns whenever possible) but the target speech duration will be constrained to lie in the range of 8-12 seconds.
目标语音的实际持续时间会有所不同(因此只要有可能,这些摘录只包括完整的回合),但是目标语音的持续时间将被限制在8-12秒的范围内。
4.1.2 Two-channel Conversations
4.1.2 Two-channel对话
As discussed in section 2.2.1, there will be training conditions consisting of one or eight two-channel telephone conversational excerpts of a given speaker.
如第2.2.1节所述,将有一个或八个给定演讲者的双通道电话会话摘录组成的培训条件。
(The first of these conditions will also include interview segments.)
(第一个条件还包括采访片段。)
These will each consist of approximately five minutes from a longer original conversation.
每段对话将包含大约五分钟较长的原始对话。
The excision points will be chosen so as not to include partial speech turns.
将选择切除点,以不包括部分语音转弯。
4.1.3 Interview Segments
4.1.3Interview段
As discussed in section 2.2.1, one of the training conditions involves conversational interview segments (along with single two- channel telephone conversations).
如第2.2.1节所述,其中一个训练条件涉及会话访谈部分(以及单通道电话会话)。
These will have varying durations of between three and fifteen minutes from a longer interview session.
面试的时间长短不一,从3分钟到15分钟不等。
The effect of longer or shorter segment durations on performance may be examined.
较长或较短的分段持续时间对性能的影响可以进行检验。
Two channels will be provided, the first from a microphone placed somewhere in the interview room, and the other from the interviewer’s head mounted close- talking microphone with some level of speech spectrum noise added to mask any interviewee speech.
将提供两个通道,第一个通道来自放置在面试室某处的麦克风,另一个通道来自安装在采访者头上的近距离交谈麦克风,它具有一定程度的语音频谱噪声,以掩盖任何面试者的讲话。
Information on the microphone type of the first channel will not be available to systems.
系统将无法获得关于第一通道的麦克风类型的信息。
The microphone data will be provided in 8-bit -law form that matches the telephone data provided.
麦克风数据将以与所提供的电话数据相匹配的8位法律形式提供。
4.1.4 Summed-channel Conversations
4.1.4 Summed-channel对话
As discussed in section 2.2.1, one of the training conditions will consist of eight summed-channel telephone conversation segments of about five minutes each.
如第2.2.1节所述,其中一项训练条件将包括8个总信道电话会话段,每个约5分钟。
Here the two sides of each conversation, in which both the target speaker and another speaker participate, are summed together.
在这里,目标说话者和另一个说话者参与的每个对话的双方被总结在一起。
Thus the challenge is to distinguish speech by the intended target speaker from speech by other participating speakers.
因此,我们面临的挑战是如何区分预期目标演讲者的演讲和其他参与演讲者的演讲。
To make this challenge feasible, the training conversations will be chosen so that each non-target speaker participates in only one conversation, while the target speaker participates in all eight.
为了使这一挑战可行,将选择训练对话,以便每个非目标发言者只参加一次对话,而目标发言者参加所有八次对话。
The difficulty of finding the target speaker’s speech in the training data is affected by whether the other speaker in a training conversation is of the same or of the opposite sex as the target.
在训练数据中找到目标说话者的讲话的难度取决于训练对话中的另一个说话者是与目标说话者相同还是相反性别。
Systems will not be provided with this information, but may use automatic gender detection techniques if they wish.
系统不会提供这些信息,但如果愿意,可以使用自动性别检测技术。
Performance results may also be examined as a function of how many of the eight training conversations contain same-sex other speakers.
性能结果也可以作为八个训练对话中有多少包含其他同性说话者的函数来检查。
4.2 Test data
4.2 测试数据
As discussed in section 2.2.2, there will be three test segment conditions.
如第2.2.2节所述,将有三个测试段条件。
NIST is interested in examining how performance varies among these conditions for fixed training conditions.
NIST有兴趣研究在固定的训练条件下,这些条件下的表现如何变化。
For all test conditions, English language ASR transcriptions of the data will be provided along with the audio data.
对于所有测试条件,数据的英文ASR转录将与音频数据一起提供。
Systems may utilize this data as they wish.
系统可以根据需要使用这些数据。
The acoustic data may be used alone, the ASR transcriptions may be used alone, or all data may be used in combination.
声学数据可以单独使用,ASR转录可以单独使用,或所有数据可以组合使用。
4.2.1 10-second Excerpts
4.2.1 10-second摘录
As discussed in section 2.2.2, one of the test conditions is an excerpt of a telephone conversation containing approximately 10 seconds of estimated speech duration in the channel of interest.
如第2.2.2节所讨论的,其中一个测试条件是在感兴趣的信道中包含约10秒估计的语音持续时间的电话对话摘录。
The actual duration of target speech will vary (so that the excerpts include only whole turns whenever possible) but the target speech duration will be constrained to lie in the range of 8-12 seconds.
目标语音的实际持续时间会有所不同(因此只要有可能,这些摘录只包括完整的回合),但是目标语音的持续时间将被限制在8-12秒的范围内。
4.2.2 Two-channel Conversations
4.2.2 Two-channel对话
As discussed in section 2.2.2, one of the test conditions involves single two-channel telephone conversational excerpts (or an interview segment).
如第2.2.2节所述,其中一个测试条件涉及单个双通道电话对话摘录(或访谈片段)。
Each excerpt will consist of approximately five minutes from a longer original conversation.
每一段摘录将包含大约五分钟的较长的原始对话。
The excision points will be chosen so as not to include partial speech turns.
将选择切除点,以不包括部分语音转弯。
4.2.3 Interview Segments
4.2.3 Interview段
As discussed in section 2.2.2, one of the test conditions involves conversational interview segments (along with single two-channel telephone conversations).
如第2.2.2节所述,其中一个测试条件涉及会话访谈片段(以及单个双通道电话会话)。
These will have varying durations of between three and fifteen minutes from a longer interview session.
面试的时间长短不一,从3分钟到15分钟不等。
The effect of longer or shorter segment durations on performance may be examined.
较长或较短的分段持续时间对性能的影响可以进行检验。
Two channels will be provided, the first from a microphone placed somewhere in the interview room, and the other from the interviewer’s head mounted close-talking microphone with some level of speech spectrum noise added to mask any interviewee speech.
将提供两个通道,第一个通道来自放置在面试室某处的麦克风,另一个通道来自面试者头上安装的近距离交谈麦克风,该麦克风添加了一定程度的语音频谱噪声,以掩盖任何面试者的讲话。
Information on the microphone type of the first channel will not be available to systems.
系统将无法获得关于第一通道的麦克风类型的信息。
The microphone data will be provided in 8-bit -law form that matches the telephone data provided.
麦克风数据将以与所提供的电话数据相匹配的8位法律形式提供。
4.2.4 Summed-channel Conversations
4.2.4 Summed-channel对话
As discussed in section 2.2.2, one of the test conditions is a single summed-channel conversational excerpt of about five minutes.
如第2.2.2节所述,其中一个测试条件是一个约五分钟的总和通道会话摘录。
Here the two sides of the conversation are summed together, and one of the two speakers included may match a target speaker specified in a trial.
在这里,对话的双方被总结在一起,其中一个说话者可能与试验中指定的目标说话者相匹配。
The difficulty of determining whether the target speaker speaks in the test conversation is affected by the sexes of the speakers in the test conversation.
在测试会话中,确定目标说话人是否说话的难度受到测试会话中说话人性别的影响。
Systems will not be told whether the two test speakers are of the same or opposite sex, but automatic gender detection techniques may be used.
系统不会被告知两个测试演讲者是同性还是异性,但可以使用自动性别检测技术。
Performance results will be examined with respect to whether one or both of the test speakers are of the same sex as the target.
测试结果将根据测试演讲者的性别来确定。
(For all trials there will be at least one speaker who is of the same sex as the target speaker.)
(在所有的试验中,至少要有一位与目标演讲者性别相同的演讲者。)
Note that an interesting contrast will exist between this condition and that consisting of a single two-channel conversation.
请注意,在这个条件和由一个单一的双通道对话组成的条件之间存在一个有趣的对比。
4.3 Factors Affecting Performance
4.3 性能影响因素
All trials will be same-sex trials.
所有的实验都将是同性别的实验。
This means that the sex of the test segment speaker in the channel of interest (two-channel), or of at least one test segment speaker (summed-channel), will be the same as that of the target speaker model.
这意味着感兴趣的通道(双通道)中的测试段说话者的性别,或者至少一个测试段说话者的性别(总和通道),将与目标说话者模型的性别相同。
Performance will be reported separately for males and females and also for both sexes pooled.
Performance将分别报告的男性和女性,也为两性总合。
This evaluation will focus on examining the effects of channel on recognition performance.
该评估将重点考察信道对识别性能的影响。
This will include in particular the comparison of performance involving telephone segments with that involving microphone segments.
这将特别包括涉及电话段的性能与涉及麦克风段的性能的比较。
Since each trial has a training and a test segment, four combinations may be examined here.
因为每个试验都有一个训练和一个测试部分,所以这里可以检查四种组合。
For test segments only, performance on telephone channel telephone conversations will be compared with performance on microphone channel telephone conversations and with performance on microphone interview segments.
仅就测试段而言,电话通道电话会话的性能将与麦克风通道电话会话的性能和麦克风访谈段的性能进行比较。
For trials involving microphone segments, it will be of interest to examine the effect of the different microphone types tested on performance, and the significance on performance of the match or mismatch of the training and test microphone types.
对于涉及麦克风段的试验,我们有兴趣检查不同麦克风类型对性能的影响,以及训练和测试麦克风类型的匹配或不匹配对性能的影响。
All or most trials involving telephone test segments will be different-number trials.
所有或大部分涉及电话测试部分的试验将是不同数量的试验。
This means that the telephone numbers, and presumably the telephone handsets, used in the training and the test data segments will be different from each other.
这意味着用于培训和测试数据段的电话号码(可能还有电话听筒)将会彼此不同。
If some trials are same-number, primary interest will be on results for different- number trials (see section 4.4 below), which may be contrasted with results on same-number trials.
如果一些试验是相同数目的,主要兴趣将是不同数目试验的结果(见下文第4.4节),这可能与相同数目试验的结果形成对比。
Past NIST evaluations have shown that the type of telephone handset and the type of telephone transmission channel used can have a great effect on speaker recognition performance.
过去的NIST评估表明,电话听筒的类型和电话传输通道的类型对说话人的识别性能有很大的影响。
Factors of these types will be examined in this evaluation to the extent that information of this type is available.
将在本评价中审查这些类型的因素,以确定是否有这种类型的资料。
Telephone callers are generally asked to classify the transmission channel as one of the following types:
电话用户一般会被要求将传输通道划分为以下类型之一:
Cellular 蜂窝电话
Cordless 无线
Regular (i.e., land-line) 固定电话
Telephone callers are generally also asked to classify the instrument used as one of the following types:
一般来说,致电人士亦须将所使用的设备分为以下类别:
Speaker-phone 免提式的?
Head-mounted 头戴式的?
Ear-bud 耳插式的?
Regular (i.e., hand-held) 手持的?
Performance will be examined, to the extent the information is available and the data sizes are sufficient, as a function of the telephone transmission channel type and of the telephone instrument type in both the training and the test segment data.
在信息可用和数据大小足够的情况下,将根据训练和测试段数据中的电话传输通道类型和电话仪器类型来检查性能。
4.4 Common Evaluation Condition
4.4 通用的评估条件
In each evaluation NIST has specified one or more common evaluation conditions, subsets of trials in the core test that satisfy additional constraints, in order to better foster technical interactions and technology comparisons among sites.
在每一次评估中,NIST都指定了一个或多个常见的评估条件,即满足附加约束条件的核心测试的子集,以便更好地促进技术交互和站点之间的技术比较。
The performance results on these trial subsets are treated as the basic official evaluation outcomes.
这些试验子集的绩效结果被视为基本的官方评估结果。
Because of the multiple types of training and test conditions in the 2010 core test, and the likely disparity in the numbers of trials of different types, it is not appropriate to simply pool all trials as a primary indicator of overall performance.
由于2010年核心测试的训练和测试条件多种多样,而且不同类型的试验数量可能存在差异,因此不能简单地将所有试验都作为总体表现的主要指标。
Rather, the common conditions to be considered in 2010 as primary performance indicators will include the following subsets of all of the core test trials:
相反,2010年作为主要绩效指标的一般情况将包括以下所有核心试验的子集:
1.
All trials involving interview speech from the same microphone in training and test在训练和测试中,所有的测试都涉及到同一个麦克风的采访演讲
2.
All trials involving interview speech from different microphones in training and test所有的试验都包括在训练和测试中使用不同麦克风进行的采访
3.
All trials involving interview training speech and normal vocal effort conversational telephone test speech
所有的试验包括采访、训练和正常的语音努力、对话电话测试
4.
All trials involving interview training speech and normal vocal effort conversational telephone test speech recorded over a room microphone channel
所有的试验包括采访训练演讲和正常的语音努力会话电话测试演讲记录在房间麦克风通道
5.
All different number trials involving normal vocal effort conversational telephone speech in training and test
在训练和测试中,所有不同的数字试验都涉及正常的语音努力,会话电话语音
6.
All telephone channel trials involving normal vocal effort conversational telephone speech in training and high vocal effort conversational telephone speech in test
所有电话信道试验都包括正常语音努力训练中的电话交谈语音和高语音努力训练中的电话交谈语音
7.
All room microphone channel trials involving normal vocal effort conversational telephone speech in training and high vocal effort conversational telephone speech in test
所有房间麦克风通道试验,包括正常语音努力会话电话语音训练和高语音努力会话电话语音测试
8.
All telephone channel trials involving normal vocal effort conversational telephone speech in training and low vocal effort conversational telephone speech in test
所有的电话通道试验都包括正常语音努力训练中的电话交谈和低语音努力训练中的电话交谈
9.
All room microphone channel trials involving normal vocal effort conversational telephone speech in training and low vocal effort conversational telephone speech in test
所有房间麦克风通道试验,包括正常语音努力会话电话语音训练和低语音努力会话电话语音测试
4.5 Comparison with Previous Evaluations
4.5 与以前评估的比较
In each evaluation it is of interest to compare performance results, particularly of the best performing systems, with those of previous evaluations.
在每次评估中,都有必要将性能结果(特别是性能最好的系统的性能结果)与以前的评估结果进行比较。
This is generally complicated by the fact that the evaluation conditions change in each successive evaluation.
这通常是复杂的事实,即评估条件的变化,在每一个后续的评估。
For the 2010 evaluation the test conditions involving normal vocal effort English language conversational telephone speech will be essentially identical those used in 2008.
在2010年的评估中,涉及正常语音努力的测试条件将与2008年的测试条件基本相同。
Conditions for interview speech in certain channels will also be quite similar.
某些渠道的采访条件也会相当相似。
Thus it will be possible to make fairly direct comparisons between 2010 and 2008 for these conditions.
因此,我们有可能对2010年和2008年的情况进行相当直接的比较。
Comparisons may also be made with the results of earlier evaluations for conditions most similar to those in this evaluation.
也可与较早前对与本评价最相似的条件的评价结果进行比较。
While the test conditions will match those used previously, the test data will be different.
虽然测试条件将与以前使用的条件匹配,但是测试数据将不同。
The 2010 target speakers will include some used in the earlier evaluations, but most will not have appeared previously.
2010年的目标发言者将包括一些在早期评估中使用的发言者,但大多数人以前没有出现过。
The question always arises of to what extent are the performance differences due to random differences in the test data sets.
由于测试数据集中的随机差异所导致的性能差异在多大程度上一直是一个问题。
For example, are the new target speakers in the current evaluation easier, or harder, on the average to recognize?
例如,平均而言,当前评估中的新目标演讲者是更容易识别,还是更难识别?
To help address this question, sites participating in the 2010 evaluation that also participated in 2008 are strongly encouraged to submit to NIST results for their (unmodified) 2008 (or earlier year) systems run on the 2010 data for the same test conditions as previously.
为了帮助解决这个问题,我们强烈建议参与2010年评估的网站,也参与了2008年的评估,向NIST提交他们的(未修改的)2008年(或更早一年)系统的结果,这些系统在2010年的数据上运行,测试条件与之前相同。
Such results will not count against the limit of three submissions per test condition (see section 7). Sites are also encouraged to “mothball” their 2010 systems for use in similar comparisons in future evaluations.
这样的结果将不计入每个测试条件的三个提交的限制(见第7节)。网站也被鼓励“封存”其2010年的系统,以便在未来的评估中进行类似的比较。
5 DEVELOPMENT DATA
5 dev数据
All of the previous NIST SRE evaluation data, covering evaluation years 1996-2008 may be used as development data for 2010.
所有以前的NIST SRE评估数据,包括1996-2008年的评估年份,都可以作为2010年的dev数据。
This includes the additional interview speech used in the follow-up evaluation to the main 2008 evaluation.
这包括在2008年主要评估的后续评估中使用的附加采访演讲。
All of this data, or just the 2008 data not already received, will be sent to prospective evaluation participants by the Linguistic Data Consortium on a hard drive (or DVD’s for the 2008 follow-up data only), provided the required license agreement is signed and submitted to the LDC.7
所有这些数据,或者只是尚未收到的2008年数据,将由语言数据联盟通过硬盘(或DVD的2008年后续数据)发送给预期的评估参与者,前提是需要签署许可协议并提交给LDC.
A very limited amount of development data representing the high and low vocal effort telephone speech that is new for 2010 will also be made available.
此外,还将提供数量非常有限的dev数据,这些数据代表了2010年新出现的高声和低声声努力电话讲话。
This will include three phone conversations for each of five speakers, one high vocal effort conversation, one low vocal effort conversation, and one normal vocal effort conversation.
这将包括5位演讲者中的每一位进行3次电话交谈,一次高声努力交谈,一次低声努力交谈,以及一次正常的声努力交谈。
This data will be made available, by the end January of 2010, on a single CD-ROM to all registered sites that have submitted the LDC license agreement described above.
到2010年1月底,这些数据将以单一光盘的形式提供给所有提交了上述LDC许可协议的注册网站。
Participating sites may use other speech corpora to which they have access for development.
参与网站可使用其拥有的其他语音语料库进行开发。
Such corpora should be described in the site’s system description (section 10).
此类语料库应在网站的系统描述(第10节)中进行描述。
6 EVALUATION DATA
6 测试数据
Both the target speaker training data and the test segment data, including the interview data, will have been collected by the Linguistic Data Consortium (LDC) as part of the various phases of its Mixer project8 or of its earlier conversational telephone collection projects.
目标说话者培训数据和测试部分数据,包括访谈数据,将由语言数据联盟(LDC)收集,作为其混合项目8或其早期会话电话收集项目的各个阶段的一部分。
The conversational telephone collections have invited participating speakers to take part in numerous conversations on specified topics with strangers.
会话电话系列已经邀请参与的演讲者与陌生人就特定的话题进行多次对话。
The platforms used to collect the data either automatically initiated calls to selected pairs of speakers, or allowed participating speakers to initiate calls themselves, with the collection system contacting other speakers for them to converse with.
用于收集数据的平台可以自动向选定的发言者发起呼叫,也可以允许参与的发言者主动发起呼叫,收集系统将与其他发言者联系,以便他们进行交谈。
Speakers were generally encouraged to use different telephone instruments for their initiated calls.
发言人一般被鼓励使用不同的电话工具来发起呼叫。
The speech data for this evaluation (other than that for the HASR test, described in section 11) will be distributed to evaluation participants by NIST on a firewire drive.
此评估的语音数据(第11节中描述的HASR测试的语音数据除外)将由NIST通过火线驱动器分发给评估参与者。
The LDC license agreement described in section 5, which non-member sites must sign to participate in the evaluation, will govern the use of this data for the evaluation.
第5节中描述的LDC许可协议(非会员站点必须签署该协议才能参与评估)将对评估中使用的数据进行管理。
The ASR transcript data and any other auxiliary data which may be supplied will be made available by NIST in electronic form to all registered participants.
ASR记录数据和任何其他可能提供的辅助数据将由NIST以电子形式提供给所有注册的参与者。
Since both channels of all telephone conversational data are provided, this data will not be processed through echo canceling software.
由于提供了所有电话会话数据的两个通道,因此这些数据不会通过回声消除软件进行处理。
Participants may choose to do such processing on their own.9
9 .参加者可选择自行处理
All training and test segments will be stored as 8-bit -law speech signals in separate SPHERE10 files.
所有的训练和测试片段将以8位法律语音信号的形式存储在单独的SPHERE10文件中。
The SPHERE header of each such file will contain some auxiliary information as well as the standard SPHERE header fields.
每个这样的文件的球面标头将包含一些辅助信息以及标准的球面标头字段。
This auxiliary information will include whether or not the data was recorded over a telephone line, and whether or not the data is from an interview session.
这些辅助信息将包括数据是否记录在电话线上,以及数据是否来自采访。
The header will not contain information on the type of telephone transmission channel or the type of telephone instrument involved.
头部将不包含有关电话传输通道类型或所涉及电话仪器类型的信息。
Nor will the room microphone type be identified for the interview data.
房间麦克风的类型也不会因采访数据而被识别。
The 10-second two-channel excerpts to be used as training data or as test segments will be continuous segments from single conversations that are estimated to contain approximately 10 seconds of actual speech in the channel of interest.
10秒的两通道摘录将被用作训练数据或测试片段,它将是单个会话的连续片段,估计在感兴趣的通道中包含大约10秒的实际讲话。
The two- channel conversational telephone excerpts, both training and test, will all be approximately five minutes in duration.
两个通道的对话电话摘录,包括培训和测试,将持续大约5分钟。
The interview segments, however, will be of varying duration between three and fifteen minutes.
然而,面试的时间长短各不相同,从3分钟到15分钟不等。
The primary channel of interest will be specified, and this will always be the A channel for interview segments.
感兴趣的主要渠道将被指定,这将始终是采访片段的A渠道。
The second, non-primary, channel will contain the interlocutor’s speech for telephone segments, and will contain the signal of the interviewer’s head mounted, close-talking microphone with some level of speech spectrum noise added for interview segments.
第二个非主要的通道将包含电话段的对话者的讲话,并将包含采访者的头戴的、近距离交谈的麦克风的信号,以及为采访段添加的某种程度的语音频谱噪声。
The header of each segment will indicate whether it comes from a telephone conversation or from an interview.
每个片段的标题将表明它是来自电话交谈还是来自采访。
The summed-channel conversational excerpts to be used as training data or as test segments will be approximately five minutes in duration
被用作训练数据或测试片段的总和通道会话摘录将持续大约5分钟
6.1 Numbers of Models
6.1 模型的数量
Table 4 provides estimated upper bounds on the numbers of models (target speakers) to be included in the evaluation for each training condition.
表4为每种训练条件的评估提供了模型(目标说话者)数量的估计上限。

6.2 Numbers of Test Segments
6.2 检测片段数量
Table 5 provides estimated upper bounds on the numbers of segments to be included in the evaluation for each test condition.
表5给出了每个测试条件的评估中包含的段数的估计上限。

6.3 Numbers of Trials
6.3 Trials的数量
The trials for each of the speaker detection tests offered will be specified in separate index files.
提供的每个说话人检测测试的试验将在单独的索引文件中指定。
These will be text files in which each record specifies the model and a test segment for a particular trial.
这些将是文本文件,其中每个记录指定特定试验的模型和测试段。
The number of trials for each test condition is expected not to exceed 750,000.
每个测试条件的试验次数预计不会超过75万次。
7 EVALUATION RULES
7、评估规则
Note that rules for HASR-only participants are specified in section 11.
注意,只有hasr参与者的规则在第11节中指定。
In order to participate in the 2008 speaker recognition evaluation a site must submit complete results for the core test condition as specified in section 2.2.3.11 Results for other tests are optional but strongly encouraged.
为了参加2008年演讲者识别评估,参赛者必须提交完整的核心测试结果,如2.2.3.11节所规定,其他测试的结果是可选的,但强烈鼓励。
Participating sites, particularly those with limited internal resources, may utilize publicly available software designed to support the development of speaker detection algorithms.
参赛者,特别是那些内部资源有限的网站,可以利用公共软件来支持说话人检测算法的开发。(One publicly available source is the Mistral software for biometric applications developed at the University of Avignon along with other European sites: http://mistral.univ-avignon.fr/en/)
The software used should be specified in the system description (section 10).
所使用的软件应在系统描述(第10节)中指定。
All participants must observe the following evaluation rules and restrictions in their processing of the evaluation data (modified rules for the HASR test are specified in section 11.2):
所有参与者在处理评估数据时必须遵守以下评估规则和限制(HASR测试的修改规则见第11.2节):
Each decision is to be based only upon the specified test segment and target speaker model.
每个决策只基于指定的测试段和目标说话人模型。
Use of information about other test segments and/or other target speakers is not allowed.(This means that the technology is viewed as being “application- ready”. Thus a system must be able to perform speaker detection simply by being trained on the training data for a specific target speaker and then performing the detection task on whatever speech segment is presented, without the (artificial) knowledge of other test data.)
不允许使用关于其他测试段和/或其他目标演讲者的信息。
For example:
例如:
Normalization over multiple test segments is
在多个测试段上的正交化是
not allowed.
不允许的。
Normalization over multiple target speakers is
在多个目标扬声器上进行单正规化
not allowed.
不允许的。
Use of evaluation data for impostor modeling is
对冒名顶替者建模的评价数据进行了分析
not allowed.
不允许的。
Speech data from past evaluations may be used for general algorithm development and for impostor modeling, but may not be used directly for modeling target speakers of the 2010 evaluation.
来自过去评估的Speech数据可以用于一般算法开发和视点替用特效建模,但不能直接用于2010年评估的目标扬声器建模。
The use of manually produced transcripts or other human-created information is not allowed.
不允许使用人工生成的文本或其他人工创建的信息。
Knowledge of the sex of the target speaker (implied by data set directory structure as indicated below) is allowed.
允许了解目标演讲者的性别(通过数据集目录结构表示,如下所示)。
Note that no cross-sex trials are planned, but that summed-channel segments may involve either same sex or opposite sex speakers.
请注意,没有跨性别试验计划,但总和渠道部分可能涉及同性或异性发言者。
Knowledge of whether or not a segment involves telephone channel transmission is allowed.
允许知道某个段是否涉及电话信道传输。
Knowledge of the telephone transmission channel type and of the telephone instrument type used in all segments is not allowed, except as determined by automatic means.
除非通过自动方式确定,否则不允许了解电话传输通道类型和所有段中使用的电话仪表类型。
Listening to the evaluation data, or any other human interaction with the data, is not allowed before all test results have been submitted.
在提交所有测试结果之前,不允许监听评估数据或任何其他与数据的人工交互。
This applies to training data as well as test segments.
这适用于培训数据和测试段。
Knowledge of any information available in the SPHERE header is allowed.
允许了解球体标头中可用的任何信息。
The following general rules about evaluation participation procedures will also apply for all participating sites:
下列关于参与评价程序的一般规则也适用于所有参赛者:
Access to past presentations – Each new participant that has signed up for, and thus committed itself to take part in, the upcoming evaluation and workshop will be able to receive, upon request, the CD of presentations that were presented at the preceding workshop.
访问过去的演示文稿——每个新参与者都已经注册,并因此承诺参加即将举行的评估和研讨会,根据要求,将能够收到在之前的研讨会上展示的演示文稿的CD。
Limitation on submissions – Each participating site may submit results for up to three different systems per evaluation condition for official scoring by NIST.
提交的限制-每个参赛者可以提交最多三个不同系统的结果,每个评估条件由NIST官方评分。
Results for earlier year systems run on 2010 data will not count against this limit.
在2010年数据上运行的早期系统的结果将不计入这一限制。
Note that the answer keys will be distributed to sites by NIST shortly after the submission deadline.
请注意,答案密钥将在提交截止日期后不久由NIST分发到各个站点。
Thus each site may score for itself as many additional systems and/or parameter settings as desired.
因此,每个站点可以根据自己的需要为自己设置许多额外的系统和/或参数设置。
Attendance at workshop – Each evaluation participant is required to have one or more representatives at the evaluation workshop who must present there a meaningful description of its system(s).
出席研讨会-每个评估参与者必须有一名或多名代表出席评估研讨会,他们必须对其系统进行有意义的描述。
Evaluation participants failing to do so will be excluded from future evaluation participation.
不这样做的评价参与者将被排除在今后的评价参与之外。
Dissemination of results
传播的结果
Participants may publish or otherwise disseminate their own results.
参与者可以发布或发布他们自己的结果。
NIST will generate and place on its web site charts of all system results for conditions of interest, but these charts will not contain the site names of the systems involved.
NIST将生成所有系统结果的图表并将其放在自己的网站上,但这些图表将不包含相关系统的网站名。
Participants may publish or otherwise disseminate these charts, unaltered and with appropriate reference to their source.
参加者可出版或以其他方式传播这些图表,但不得改动,并可适当参考其来源。
Participants may not publish or otherwise disseminate their own comparisons of their performance results with those of other participants without the explicit written permission of each such participant.
未经每个参与者的明确书面许可,参与者不得发表或以其他方式传播他们与其他参与者的绩效比较结果。
Furthermore, publicly claiming to “win” the evaluation is strictly prohibited.
此外,公开声称“赢得”评价是严格禁止的。
Participants violating this rule will be excluded from future evaluations.
违反这一规则的参与者将被排除在未来的评估之外。
8 EVALUATION DATA SET ORGANIZATION
8、评估数据集组织
This section describes the organization of the evaluation data other than the HASR data, which will be provided separately to those doing this test.
本节描述了HASR数据之外的评估数据的组织,这些数据将单独提供给那些做这个测试的人。
The organization of the evaluation data will be:
评价数据的组织如下:
A top level directory used as a unique label for the disk: “sp10-NN” where NN is a digit pair identifying the disk
用作磁盘唯一标签的顶级目录:“sp10-NN”,其中NN是标识磁盘的数字对
Under which there will be four sub-directories: “data”, “test”, “trials”, and “doc”
其中包括四个子目录:“data”、“test”、“trials”和“doc”
8.1 data Sub-directory
8.1 数据子目录
This directory will contain all of the speech data files to be used as model training or test segments.
此目录将包含用作模型训练或测试段的所有语音数据文件。
Its organization will not be explicitly described.
它的组织不会被明确地描述。
Rather the files in it referenced in other sub- directories will include path-names as well as file names.
相反,在其他子目录中引用的文件将包括路径名和文件名。
8.2 train Sub-directory
8.2 培训目录
The “train” directory will contain four training files that define the models for each of the four training conditions.
“训练”目录将包含四个训练文件,分别为这四个训练条件定义模型。
Each will have one record per line containing three or more fields.
每行将有一条记录,其中包含三个或多个字段。
The first field is the model identifier.
第一个字段是模型标识符。
The second field identifies the gender of the model, either “m” of “f”.
第二个字段标识模型的性别,可以是“f”中的“m”。
The remaining fields specify the speech files in the data directory to be used to train the model.
其余字段指定数据目录中用于训练模型的语音文件。
These each consist of the file path-name, specifying the subdirectories under the data directory, but not including “data/”, and the file name itself, including the “.
它们分别由文件路径名(指定data目录下的子目录,但不包括“data/”)和文件名本身(包括“”)组成。
sph” extension.
sph”扩展。
For the two channel training conditions, each list item also has appended a “:” and a character that specifies whether the target speaker’s speech is on the “A” or the “B” channel of the speech file.
对于两个通道训练条件,每个列表项还附加了一个“:”和一个字符,该字符指定目标说话者的讲话是在语音文件的“a”通道还是“B”通道上。
The four training files are named:
四个训练文件分别命名为:

This directory may not be included on the hard drives distributed to evaluation participants, but rather distributed electronically.
此目录可能不包括在分发给评估参与者的硬盘上,而是以电子方式分发。
8.3 trials Sub-directory
8.3 trials 子目录
The “trials” directory will contain 9 index files, one for each of the evaluation tests.
“试用”目录将包含9个索引文件,每个索引文件对应一个评估测试。
These index files define the various evaluation tests.
这些索引文件定义了各种评估测试。
The naming convention for these index files will be “TrainCondition-TestCondition.
这些索引文件的命名约定是“TrainCondition-TestCondition”。
ndx” where TrainCondition, refers to the training condition and whose models are defined in the corresponding training file.
其中训练条件是指训练条件,其模型定义在相应的训练文件中。
Possible values for TrainCondition are: 10sec, core, 8conv, and 8summed.
训练条件的可能值为:10sec, core, 8conv,和8sum。
“TestCondition” refers to the test segment condition.
“测试条件”是指测试段条件。
Possible values for TestCondition are: 10sec, core, and summed.
TestCondition的可能值是:10sec、core和sum。
Each record in a TrainCondition-TestCondition.
每个记录在一个训练条件-测试条件。
ndx file contains three fields and defines a single trial.
ndx文件包含三个字段并定义一个试验。
The first field is the model identifier.
第一个字段是模型标识符。
The second field identifies the gender of the model, either “m” or “f”.
第二个字段标识模型的性别,“m”或“f”。
The third field specifies the test segment under evaluation, located in the data directory.
第三个字段指定要计算的测试段,位于数据目录中。
It consists of the file path- name, specifying the subdirectories under the data directory, but not including “data/”, and the file name itself, including the “.
它由文件路径名(指定data目录下的子目录,但不包括“data/”)和文件名本身(包括“”)组成。
sph” extension.
sph”扩展。
This test segment name will not include the .sph extension.
此测试段名称将不包括.sph扩展名。
For the two channel test conditions this field also has appended a “:” and a character that specifies whether the speech of interest is on the “A” or the “B” channel of the speech file.
对于两个通道测试条件,该字段还附加了一个“:”和一个字符,该字符指定感兴趣的语音是在语音文件的“a”通道还是“B”通道上。
(This will always be “A” for interview test segments.)
(在面试测试环节,这一项永远都是“A”。)
Example records might look like:
示例记录可能如下所示:

This directory may not be included on the hard drives distributed to evaluation participants, but rather distributed electronically
此目录可能不包括在分发给评估参与者的硬盘上,而是以电子方式分发
8.4 doc Sub-directory
8.4 文档目录
This will contain text files that document the evaluation and the organization of the evaluation data.
这将包含记录评估和评估数据组织的文本文件。
This evaluation plan document will be included.
本评价计划文件将包括在内。
9 SUBMISSION OF RESULTS
9、结果的提交
This section does not apply to the HASR test, whose submission requirements are described separately (section 11.4).
本节不适用于HASR测试,其提交要求另行说明(第11.4节)。
Sites participating in one or more of the speaker detection evaluation tests must report results for each test in its entirety.
参与一个或多个演讲者检测评估测试的站点必须完整地报告每个测试的结果。
These results for each test condition (1 of the 9 test index files) must be provided to NIST in a separate file for each test condition using a standard ASCII format, with one record for each trial decision.
每个测试条件的结果(9个测试索引文件中的1个)必须使用标准的ASCII格式以单独的文件提供给NIST,每个测试决定有一个记录。
The file name should be intuitively mnemonic and should be constructed as |
文件名应该是直观的助记符,应该构造为|
“SSSsss_N_traincondition_testcondition_isprimary_isllr”, where SSSsss (3-6 characters) identifies the site
“SSSsss_N_traincondition_testcondition_isprimary_isllr”,其中SSSsss(3-6个字符)标识站点
N identifies the system.
N表示系统。
traincondition refers to the training condition and whose models are defined in the corresponding training file.
训练条件是指训练条件,其模型定义在相应的训练文件中。
Possible values for traincondition are: 10sec, core, 8conv, and 8summed.
训练条件的可能值为:10sec, core, 8conv,和8sum。
testcondition refers to the test segment condition.
testcondition是指测试段的条件。
Possible values for testcondition are: 10sec, core, and summed.
testcondition的可能值是:10sec、core和sum。
isprimary refers to the whether the submission is for the primary system in the test condition.
isprimary是指在测试条件下提交的是否是针对主系统的。
Possible values for isprimary are: primary and alternate.
isprimary的可能值是:primary和alternate。
isllr refers to whether the system scores can correctly be interpreted as log likelihood ratio values.
isllr是指系统得分是否可以正确解释为日志似然比值。
Possible values are: llr and other
可能的值是:llr和其他
9.1 Format for Results
9.1 格式的结果
Each file record must document its decision with the target model identification, test segment identification, and decision information.
每个文件记录必须用目标模型标识、测试段标识和决策信息来记录它的决策。
Each record must contain eight fields, separated by white space and in the following order:
每条记录必须包含8个字段,以空格分隔,按以下顺序排列:
1.
The training type of the test – 10sec, core, 8conv, or 8summed
考试的训练类型- 10秒,核心,8个conv,或8个求和
2.
The segment type of the test – 10sec, core, or summed
测试的段类型- 10sec, core,或sum
3.
The sex of the target speaker – m or f
目标说话者的性别- m或f
4.
The target model identifier
目标模型标识符
5.
The test segment identifier
测试段标识符
6.
The test segment channel of interest, either “a” or “b”
感兴趣的测试段通道,“a”或“b”
7.
The decision – t or f (whether or not the target speaker is judged to match the speaker in the test segment)
判定- t或f(判断目标说话人是否与测试段说话人匹配)
8.
The score (where larger scores indicate greater likelihood that the test segment contains speech from the target speaker)
分数(分数越大,表示测试片段包含目标说话者的讲话的可能性越大)
9.2 Means of Submission
9.2 提交的方法
Submissions may be made via email or via ftp.
提交可以通过电子邮件或通过ftp。
The appropriate addresses for submissions will be supplied to participants receiving evaluation data.
提交的适当地址将提供给收到评估数据的参与者。
10 SYSTEM DESCRIPTION
10、系统描述
A brief description of the system(s) (the algorithms) used to produce the results must be submitted along with the results, for each system evaluated.
对于每个被评估的系统,用于产生结果的系统(算法)的简要描述必须与结果一起提交。
A single site may submit the results for up to three separate systems for evaluation for each particular test, not counting results for earlier year systems run on the 2010 data.
单个站点最多可以提交三个独立系统的测试结果,以对每个特定的测试进行评估,而不包括根据2010年数据运行的前一年系统的结果。
If results for more than one system are submitted for a test, however, the site must identify one system as the “primary” system for the test as part of the submission.
但是,如果一个测试提交了多个系统的结果,那么站点必须在提交时将一个系统标识为测试的“主”系统。
Sites are welcome to present descriptions of and results for additional systems at the evaluation workshop.
欢迎各站点在评价讲习班上介绍其他系统的描述和结果。
For each system for which results are submitted, sites must report the CPU execution time that was required to process the evaluation data, as if the test were run on a single CPU.
对于提交结果的每个系统,站点必须报告处理评估数据所需的CPU执行时间,就像在单个CPU上运行测试一样。
This should be reported separately for creating models from the training data and for processing the test segments, and should be reported as a multiple of real-time for the data processed.
对于从训练数据中创建模型和处理测试片段,应该单独报告,对于处理的数据,应该以多个实时数据的形式报告。
This may be reported separately for each test.
这可能会在每个测试中单独报告。
Sites must also describe the CPU(s) utilized and the amounts of memory used.
站点还必须描述所使用的CPU和所使用的内存量。
11 HASR TEST
11 、hasr测试
The Human Assisted Speaker Recognition (HASR) test will contain a subset of the core test trials of SRE10 to be performed by systems involving, in part or in whole, human judgment to make trial decisions.
人类辅助说话人识别(HASR)测试将包含SRE10核心测试试验的一个子集,由部分或全部涉及人类判断的系统执行,以做出试验决定。
The systems doing this test may include large amounts of automatic processing, with human involvement in certain key aspects, or may be solely based on human listening.
做这个测试的系统可能包括大量的自动处理,在某些关键方面有人类的参与,或者可能仅仅基于人类的倾听。
The humans involved in a system’s decisions may be a single person or a panel or team of people.
参与系统决策的人员可能是一个人,也可能是一个小组或一组人。
These people may be professionals or experts in any type of speech or audio processing, or they may be simply “naïve” listeners.
这些人可能是任何类型的演讲或音频处理的专业人士或专家,也可能只是“天真的”听众。
The required system descriptions (section 11.4) must include a description of the system’s human element.
所需的系统描述(第11.4节)必须包括对系统的人员元素的描述。
Forensic applications are among the applications that the HASR test serves to inform, but the HASR test should not be considered to be a true or representative “forensic” test.
法医应用程序是HASR测试提供信息的应用程序之一,但HASR测试不应被视为真实或具有代表性的“法医”测试。
This is because many of the factors that influence speaker recognition performance and that are at play in forensic applications are controlled in the HASR test data, which are collected by the LDC following their collection protocols.
这是因为许多影响说话人识别性能的因素以及在取证应用中起作用的因素都受到HASR测试数据的控制,而这些数据是由LDC按照收集协议收集的。
While fully automatic systems are expected to run the full core test (section 2.2.3), they may, if desired, also be run on the HASR trials in accordance with the procedures given here.
虽然全自动系统有望运行完整的核心测试(第2.2.3节),但如果需要,它们也可以按照这里给出的程序在HASR试验中运行。
While the HASR trials are a subset of the core trials, note the scoring procedure (see section 11.3 below) will be different (and simpler) in HASR than in the core test.
虽然HASR试验是核心试验的一个子集,但请注意,HASR中的评分过程(参见下面第11.3节)与核心试验中的不同(且更简单)。
HASR is clearly a new type of test for NIST evaluations, and accordingly it should be viewed as a pilot test.
HASR显然是NIST评估的一种新型测试,因此它应该被视为一种试点测试。
If response to it in 2010 is favorable, it will be continued, and refined, in future evaluations.
如果在2010年对它的反应是积极的,它将在未来的评估中继续和完善。
11.1 Trials and Data
11.1 试验和数据
To accommodate different interests and levels of effort, two test sets will be offered, one with 15 trials (HASR1), and one with 150 trials (HASR2).
为了适应不同的兴趣和工作级别,将提供两个测试集,一个包含15个试验(HASR1),另一个包含150个试验(HASR2)。
HASR participants may choose to perform either test.
HASR参与者可以选择执行任何一个测试。
Because of the small numbers of trials in the HASR test set, the difficulty of the test will be increased by selection of difficult trials.
由于HASR测试集中的试验数量较少,因此选择困难的试验将增加测试的难度。
Objective criteria will be used to select dissimilar test conditions for target trials and similar speakers for non-target trials.
将使用客观标准为目标试验选择不同的试验条件,为非目标试验选择相似的扬声器。
11.2 Rules
11.2 规则
The rules on data interaction as specified in section 7 not allowing human listening or transcript generation or other interaction with the data, do not apply, but the requirement for processing each trial separately and making decisions independently for each trial remains in effect.
第7节中规定的关于数据交互的规则不允许人类聆听、生成转录本或与数据进行其他交互,但对每个试验分别处理和独立决策的要求仍然有效。
Specifically:
具体地说:
Each decision is to be based only upon the specified test segment and target speaker model.
每个决策只基于指定的测试段和目标说话人模型。
Use of information about other test segments and/or other target speakers is not allowed.
不允许使用关于其他测试段和/或其他目标演讲者的信息。
This presents a dilemma for human interactions, however, because humans inherently carry forward information from prior experience.
然而,这给人类的互动带来了一个难题,因为人类天生就会从先前的经验中获取信息。
To help minimize the impact of this prior exposure on human judgments, the trials will be released sequentially via an online automatic procedure.
为了尽量减少这种先前接触对人类判断的影响,试验将通过在线自动程序依次发布。
The protocol for this sequential testing will be specified in greater detail in early 2010, but will basically work as follows:
后续测试的协议将在2010年初更详细地规定,但基本工作如下:
NIST will release the first trial for download to each participant.
NIST将发布第一个试用版供每个参与者下载。
The participant will process that trial and submit the result to NIST in the format specified in section 11.4.
参与者将按照第11.4节中规定的格式处理该试验并将结果提交给NIST。
NIST will verify the submission format, and then make the next trial available for download to the participant.
NIST将验证提交的格式,然后将下一个试用版提供给参与者下载。
The training and test speech data for each trial may be listened to by the human(s) involved in the processing as many times and in any order as may be desired.
每个试验的训练和测试语音数据可由参与处理的人员按所需的次数和顺序听多次。
The human processing time involved must be reported in the system descriptions (see section 11.4 below).
所涉及的人工处理时间必须在系统描述中报告(参见下面的11.4节)。
The rules on dissemination of results as specified in section 7 will apply to HASR participants,
第7条规定的成果传播规则将适用于HASR参与者,
System descriptions are required as specified in section 10.
系统描述需要在第10节中指定。
They may be sent to NIST at any time during the processing of the HASR trials, or shortly after the final trial is processed.
在HASR试验过程中的任何时候,或者在最终试验结束后不久,都可以将它们发送给NIST。
They should also describe the human(s) involved in the processing, how human expertise was applied, what automatic processing algorithms (if any) were included, and how human and automatic processing were merged to reach decisions.
它们还应该描述处理过程中涉及的人员、如何应用人员的专门知识、包括哪些自动处理算法(如果有的话)、以及如何将人工处理和自动处理合并以达成决策。
Execution time should be reported separately for human effort and for machine processing (if relevant).
执行时间应该分别报告人工工作和机器处理(如果相关)。
Because HASR is a pilot evaluation with an unknown level of participation, participating sites will not in general be expected to be represented at the SRE10 workshop.
由于HASR是一项试验性评价,参与程度未知,因此一般不希望参与地点出席SRE10讲习班。
NIST will review the submissions, and most particularly the system descriptions, and will then invite representatives from those systems that appear to be of particular interest to the speaker recognition research community to attend the workshop and offer a presentation on their system and results.
NIST将审查提交的内容,尤其是系统描述,然后邀请那些系统的代表参加研讨会,并就他们的系统和结果进行介绍。
One workshop session will be devoted to the HASR test and to comparison with automatic system results on the HASR trials.
一个专题讨论会将专门讨论HASR测试,并与HASR试验的自动系统结果进行比较。
HASR is open to all individuals and organizations who wish to participate in accordance with these rules.
HASR对所有希望按照这些规则参与的个人和组织开放。
11.3 Scoring
11.3 打分
Scoring for HASR will be very simple.
HASR的得分将非常简单。
Trial decisions (“true” or “false”) will be required as in the automatic system evaluation.
试验决定(“正确”或“错误”)将需要在自动系统评估。
In light of the limited numbers of trials involved in HASR, we will simply report for each system the overall number of correct detections (Ncorrect detections on Ntarget trials) and the overall number of correct rejections (Ncorrect rejections on Nnon-target trials).
鉴于HASR涉及的试验数量有限,我们将简单地报告每个系统的正确检测的总体数量(Ntarget试验的错误检测)和正确拒绝的总体数量(Nnon-target试验的错误拒绝)。
Scores for each trial will be required as in the automatic system evaluation, with higher scores indicating greater confidence that the test speaker is the target speaker.
与自动系统评估一样,每个测试的分数都是必需的,分数越高,表示测试者越有信心认为测试者就是目标说话者。
It is recognized, however, that when human judgments are involved there may only be a discrete and limited set of possible score values.
然而,人们认识到,当涉及到人类判断时,可能只有一组离散的、有限的可能的评分值。
In the extreme, there might only be two;
在极端情况下,可能只有两个;
e.g., 1.0 corresponding to “true” decisions and -1.0 corresponding to “false” decisions.
例如,1.0对应“正确”决策,-1.0对应“错误”决策。
This is acceptable.
这是可以接受的。
DET curves, or a discrete set of DET points will be generated, and compared with the performance of automatic systems on the same trial set.
将生成的DET曲线或一组离散的DET点,并与自动系统在同一试验集上的性能进行比较。
For each submission, the system description (section 11.4) should specify how scores were determined.
对于每个提交,系统描述(第11.4节)应指定如何确定分数。
Where this is a discrete set, the meaning of each possible score should be explained.
如果这是一个离散集,则应该解释每个可能的分数的含义。
It should also be indicated whether the scores may be interpreted as log likelihood ratios.
还应指出这些分数是否可以解释为对数似然比。
11.4 Submissions
11.4 提交
HASR trial submissions should use the following record format, which is a somewhat shortened version of that specified in section 9.1:
HASR试验提交应使用以下记录格式,这是9.1节中规定的记录格式的简化版:
1.
The test condition – “HASR1” or “HASR2”
测试条件—“HASR1”或“HASR2”
2.
The target model identifier
目标模型标识符
3.
The test segment identifier
测试段标识符
4.
The test segment channel of interest, either “a” or “b”
感兴趣的测试段通道,“a”或“b”
5.
The decision as specified above in section 11.3
上述第11.3条规定的决定
6.
The score
分数
12、SCHEDULE
12、 时间表
The deadline for signing up to participate in the evaluation is March 1, 2010.
报名参加评估的截止日期为2010年3月1日。
The HASR data set will become available for sequential distribution of trial data to registered participants in this test beginning on February 15, 2010
从2010年2月15日开始,HASR数据集将可用于将试验数据按顺序分发给本试验的注册参与者
The evaluation data (other than the HASR data) set will be distributed by NIST so as to arrive at participating sites on March 29, 2010.
评估数据(HASR数据除外)集将由NIST分发,以便于2010年3月29日到达参与站点。
The deadline for submission of evaluation results (including all HASR trial results) to NIST is April 29, 2010 at 11:59 PM, Washington, DC time (EDT or GMT-4).
向NIST提交评估结果(包括所有HASR试验结果)的截止日期为2010年4月29日,华盛顿时间晚上11:59 (EDT或GMT-4)。
Initial evaluation results will be released to each site by NIST on May 14, 2010.
初步评估结果将于2010年5月14日由NIST公布。
The deadline for site workshop presentations to be supplied to NIST in electronic form for inclusion in the workshop CD-ROM is (a date to be determined).
现场研讨会报告以电子形式提供给NIST,并纳入研讨会CD-ROM的截止日期为(日期待定)。
Registration and room reservations for the workshop must be received by (a date to be determined).
必须在(日期待定)之前收到车间的登记和房间预订。
The follow-up workshop will be held June 24-26, 2010 in Brno, the Czech Republic.
后续研讨会将于2010年6月24日至26日在捷克共和国布尔诺举行。
This workshop will precede the Odyssey 2010 international workshop at this location.
这个研讨会将在奥德赛2010国际研讨会之前在这里举行。
All sites participating in the main evaluation (core test) must have one or more representatives in attendance to discuss their systems and results.
所有参与主评估(核心测试)的站点必须有一个或多个代表出席,以讨论他们的系统和结果。
13 GLOSSARY
13、词汇表
Test – A collection of trials constituting an evaluation component.
测试-组成评估部分的一组试验。
Trial – The individual evaluation unit involving a test segment and a hypothesized speaker.
试验-个人评估单位,包括一个测试部分和一个假设的演讲者。
Target (model) speaker – The hypothesized speaker of a test segment, one for whom a model has been created from training data.
目标(模型)说话者——测试部分假设的说话者,根据训练数据为其创建了一个模型。
Non-target (impostor) speaker – A hypothesized speaker of a test segment who is in fact not the actual speaker.
非目标(冒名顶替者)说话者-一个假想的测试部分的说话者,实际上不是真正的说话者。
Segment speaker – The actual speaker in a test segment.
段说话人-测试段中的实际说话人。
Target (true speaker) trial – A trial in which the actual speaker of the test segment is in fact the target (hypothesized) speaker of the test segment.
目标(真正的说话者)试验——测试部分的实际说话者实际上是测试部分的目标(假设)说话者的试验。
Non-target (impostor) trial – A trial in which the actual speaker of the test segment is in fact not the target (hypothesized) speaker of the test segment.
非目标(冒名顶替者)试验-测试部分的实际说话者实际上不是测试部分的目标(假设)说话者的试验。
Turn – The interval in a conversation during which one participant speaks while the other remains silent.
轮流——谈话中一方说话而另一方保持沉默的时间间隔。
这篇关于The NIST Year 2010 Speaker Recognition Evaluation Plan的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






