evaluation专题

MS COCO数据集目标检测评估(Detection Evaluation)
MS COCO (Microsoft Common Objects in Context) 是一个广泛应用于计算机视觉领域的数据集和评估平台,尤其是在目标检测、分割和人体关键点检测等任务中。COCO数据集和其评估方法被广泛用于学术研究和工业应用。以下是对MS COCO数据集目标检测评估、人体关键点评估、输出数据的结果格式以及如何参加比赛的详细阐述和总结。 1. MS COCO数据集目标检测评估(

论文阅读:《BLEU: a Method for Automatic Evaluation of Machine Translation》
https://blog.csdn.net/qq_21190081/article/details/53115580 论文地址:http://xueshu.baidu.com/s?wd=paperuri%3A%2888a98dec5bea94cca9f474db30c36319%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=

【IDE】com.intellij.debugger.engine.evaluation.EvaluateException
目录标题 报错重现代码分析解决方式 报错重现 Error during generated code invocation com.intellij.debugger.engine.evaluation.EvaluateException: Method threw 'java.lang.NullPointerException' exception. 代码分析 //

CVPR 2024 - Rethinking the Evaluation Protocol of Domain Generalization
CVPR 2024 - Rethinking the Evaluation Protocol of Domain Generalization 论文:https://arxiv.org/abs/2305.15253原始文档:https://github.com/lartpang/blog/issues/8 这篇文章主要讨论了领域泛化评估协议的重新思考,特别是如何处理可能存在的测试数据信息泄
Codeforces 1210 D Konrad and Company Evaluation —— 暴力
This way 题意: 现在有n个人,第i个人的工资一开始是i,现在有一些人相互讨厌,然后如果第x个人和第y个人相互讨厌,并且x的工资比y高,那么x就会向y炫耀。 x,y,z这三个人的组合是危险的,当x会向y炫耀,y会向z炫耀。 每次修改一个人的工资为大于所有人,并且询问你此时有多少种三人组合是危险的 题解: 那么这道题就有一个很暴力的做法,我们通过样例解释可以发现,其实就是一张有向图

#LLM入门|Prompt#2.10_评估、自动化测试效果(下)——当不存在一个简单的正确答案时 Evaluation Part2
上一章我们探索了如何评估 LLM 模型在 有明确正确答案 的情况下的性能,并且我们学会了编写一个函数来验证 LLM 是否正确地进行了分类列出产品。 在使用LLM生成文本的场景下,评估其回答准确率可以是一个挑战。由于LLM是基于大规模的训练数据进行训练的,因此无法像传统的分类问题那样使用准确率来评估其性能。 一、运行问答系统获得一个复杂回答 我们首先运行在之前章节搭建的问答系统来获得一个复杂的、
KITTI 3D Object Detection Evaluation 结果评估程序
KITTI 3D Object Detection Evaluation 结果评估程序 KITTI 3D Object Detection结果评估程序下载程序(工具包)对预测结果进行评估1.预测结果存放格式2.标签和预测结果存放目录3.如何使用评估文件 KITTI 3D Object Detection结果评估程序 下载程序(工具包) 在对KITTI数据集进行预测得到结果后
jmete软件Error invoking bsh method: eval In file: inline evaluation of: “File file = new File()“
jmeter BeanShell 取样器执行后报错 ERROR o.a.j.u.BeanShellInterpreter: Error invoking bsh method: eval In file: inline evaluation of: ``File file = new File(“D:/workspace/jmeterwok/session.txt”) //在内存中新建一个file
【More Effective C++】条款17:考虑使用lazy evaluation
含义:将计算拖延到必须计算的时候,以下为4个场景 优点:避免不必要的计算,节省成本 缺点: 管理复杂性:可能会增加代码复杂性,特别是在多线程环境中需要正确处理同步和并发问题。性能开销:如果没有正确地实现,可能会导致性能问题,例如,频繁的延迟加载操作可能会导致多次不必要的数据库查询或资源请求 reference counting eager evaluation:调用拷贝构造函数,分配内存

Artificial Intelligence in Evaluation, Validation, Testing and Certification
Everybody seems to jump on the AI bandwagon these days, “enhancing” their products and services with “AI.” It sounds, however, a bit like the IoT hype from the last decade when your coffee machine des

论文 | 信息检索结果Ranking的评价指标《RankDCG: Rank-Ordering Evaluation Measure》
未经允许,不得转载,谢谢~~ 一 文章简介 为什么要提出这个新的评价算法? 我们都知道ranking过程对于信息检索的结果是非常重要的,那么我们就需要有一些算法能评价ranking的结果到底如何。现有用来评价ranking的常用算法有:Kendall's τ, Average Precision(AP) , Mean Average Precision(MAP),Discounted Cumul

《Two Dozen Short Lessons in Haskell》学习(十四)- Truncating Sequences and Lazy Evaluation
《Two Dozen Short Lessons in Haskell》(Copyright © 1995, 1996, 1997 by Rex Page,有人翻译为Haskell二十四学时教程,该书如果不用于赢利,可以任意发布,但需要保留他们的copyright)这本书是学习 Haskell的一套练习册,共有2本,一本是问题,一本是答案,分为24个章节。在这个站点有PDF文件。几年前刚开始学习

GAN笔记_李弘毅教程(十)Evaluation Concluding Remarks
文章目录 EvaluationLikelihoodInception Score Mode DroppingGAN产生的distribution不够大之solutionUnroll GANMini-batch DiscriminationOptimal Transport GAN(OTGAN) Concluding Remarks Evaluation Likelihood
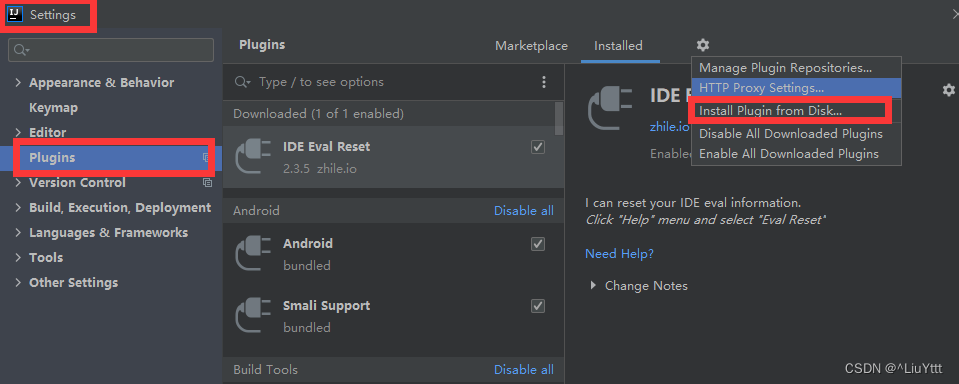
IDEA | Your idea evaluation has expired. Your session will be limited to 30 minutes
Your idea evaluation has expired. Your session will be limited to 30 minutes 您的idea评估已过期。您的会话将被限制在 30 分钟。解决方法如下, 在idea中安装插件idea eval Reset即可.
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP 1. 文章简介2. 文章概括3 文章重点技术3.1 数据收集3.2 数据扰动3.3 迭代标注和检查根因3.4 度量3.4.1 Token F1-score3.4.2 MAP(Mean Average Precision) 4. 文章亮点5. 原
Metric evaluation error start - Target {oracle_database.orcl} is broken: Dynamic Category property e
今天在oracle 13c OEM创建oracle 11g 监控的时候,发现如下报错信息 Metric evaluation error start - Target {oracle_database.orcl} is broken: Dynamic Category property error,Get dynamic property error,No such metadata -

【隐私计算】VOLE (Vector Oblivious Linear Evaluation)学习笔记
近年来,VOLE(向量不经意线性评估)被用于构造各种高效安全多方计算协议,具有较低的通信复杂度。最近的CipherGPT则是基于VOLE对线性层进行计算。 1 VOLE总体设计 VOLE的功能如下,VOLE发送 Δ \Delta Δ和 b b b给sender,发送 a a a和 c c c给receiver,并且 c , a , b c, a, b c,a,b满足线性关系: c = Δ ⋅
uvalive 6697 - Homework Evaluation - dp
题意:给出两个字符串,用第二个字符串去匹配第一个字符串,可以对第二个字符串进行删除或插入操作,一位匹配成功得8分失败-5分,如果插入或删除,对于连续插入或删除m个数减(4+m * 3)分。求最终得分的最大值。 用dp[i][j]表示第二个串的第i位和第一个串的第j位匹配得分的最大值,dp[i][j]可以是dp[i - 1][j - 1]继续匹配也可能是dp[i - 1][k]通过插入一段串得到或
Policy Evaluation的收敛性是怎么一回事
完美的学习算法 昨天和同学在群里讨论DRL里bad case的问题。突然有同学提出观点:“bad case其实并不存在,因为一些算法已经理论证明了具有唯一极值点,再加上一些平滑技巧指导优化器,就必然可以收敛。” 当听到这个观点时,我是一时语塞。因为当前深度学习研究的最大问题就是,花了很大资源训练的千万参数神经网络根本不work,一切都白白浪费。因此才有NAS之类方法尝试根据一些训练初期的动力学
Policy Evaluation的收敛性是怎么一回事
完美的学习算法 昨天和同学在群里讨论DRL里bad case的问题。突然有同学提出观点:“bad case其实并不存在,因为一些算法已经理论证明了具有唯一极值点,再加上一些平滑技巧指导优化器,就必然可以收敛。” 当听到这个观点时,我是一时语塞。因为当前深度学习研究的最大问题就是,花了很大资源训练的千万参数神经网络根本不work,一切都白白浪费。因此才有NAS之类方法尝试根据一些训练初期的动力学

Spar(k)ql:SPARQL evaluation method on spark GraphX
abstract: 由于灵活和简易,RDF变的越来越受欢迎的框架。查询大量的RDF数据也是面临的巨大的挑战。in this paper ,我们研究如何评估分布式系统中的sparql查询。我们提出了一中利用graphx图形分析工具对sparql查询评估的新方法。通过此工具,我们成功利用RDF语句的类图结构。 introduction: P:查询大量的数据集变成严峻的挑战。s

RUL论文阅读—— A Novel Evaluation Framework for Unsupervised Domain Adaption on Remaining Useful Lifetime
RUL论文阅读 ——A Novel Evaluation Framework for Unsupervised Domain Adaption on Remaining Useful Lifetime link : article code 一、 Introduction 由PMD(Predictive Maintenance) 提出 RUL DNN(require large amoun

【NLP+医学】Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence
Paper From:Nature Medicine 2019 Paper URL:https://www.nature.com/articles/s41591-018-0335-9 主要内容 提出了一套「疾病确认」的计算框架,用于对儿科疾病进行自动化分类。如上图: EHRs: 数据源EHRs(电子健康记录)包括「主属、现病史、各种检验检查报告」;knowledge-based tex

论文翻译(13)--CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation
CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation CASME II:一个改进的自发微表达数据库及基线评估 论文地址:链接:https://pan.baidu.com/s/1k6AY4W2zU1aENtTo5BZ3Mg 提取码:a042 摘要 一个健壮的自动微表情识别系
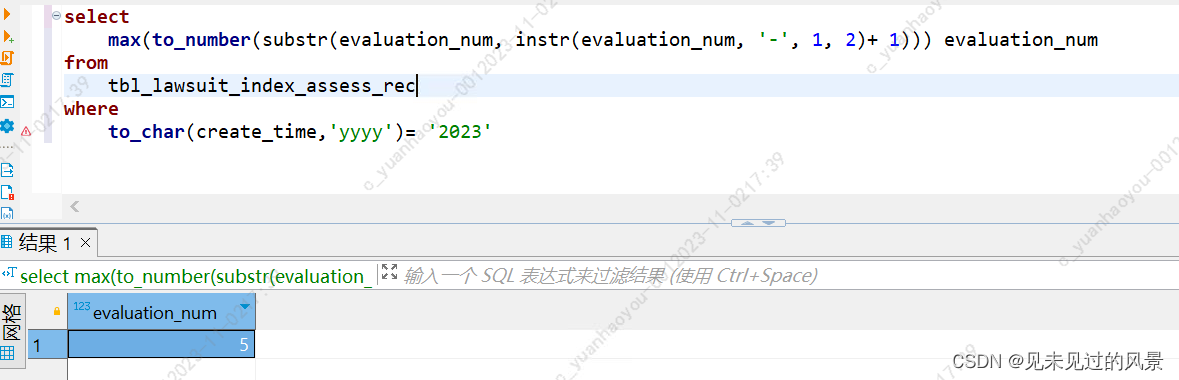
查出来这个表中evaluation_num字段中以2023开头的最大的尾数是几,instr用法
查出来这个表中evaluation_num字段中以2023开头的最大的尾数是几, sql如下: select max(to_number(substr(evaluation_num,instr(evaluation_num,'-',1,2)+1))) evaluation_numfrom tbl_lawsuit_index_assess_rec where to_char(create_t
Evaluation Metrics in the Era of GPT-4
本文是LLM系列文章,针对《Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks》的翻译。 GPT-4时代的评估度量:在序列到序列的任务中可靠地评估大型语言模型 摘要1 引言2 实验设置3 评估指标4 结果和讨论5 结论局限