本文主要是介绍查出来这个表中evaluation_num字段中以2023开头的最大的尾数是几,instr用法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
查出来这个表中evaluation_num字段中以2023开头的最大的尾数是几,
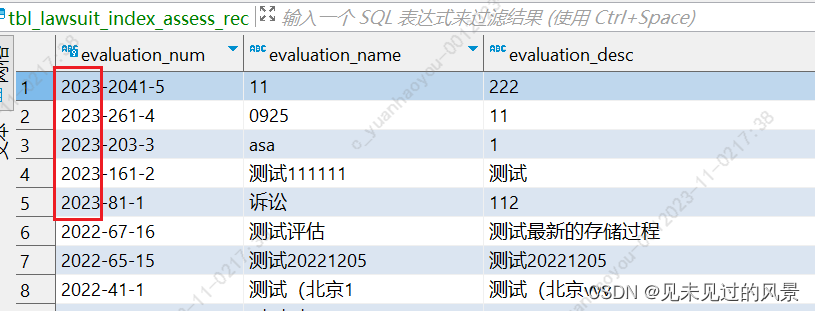
sql如下:
select max(to_number(substr(evaluation_num,instr(evaluation_num,'-',1,2)+1))) evaluation_num
from tbl_lawsuit_index_assess_rec
where to_char(create_time,'yyyy')='2023'
我的数据表中存的有时间,如果表中没有存可以换成
select max(to_number(substr(evaluation_num,instr(evaluation_num,'-',1,2)+1))) evaluation_num
from tbl_lawsuit_index_assess_rec
where to_char(create_time,'yyyy') like ='2023%'
查询结果:
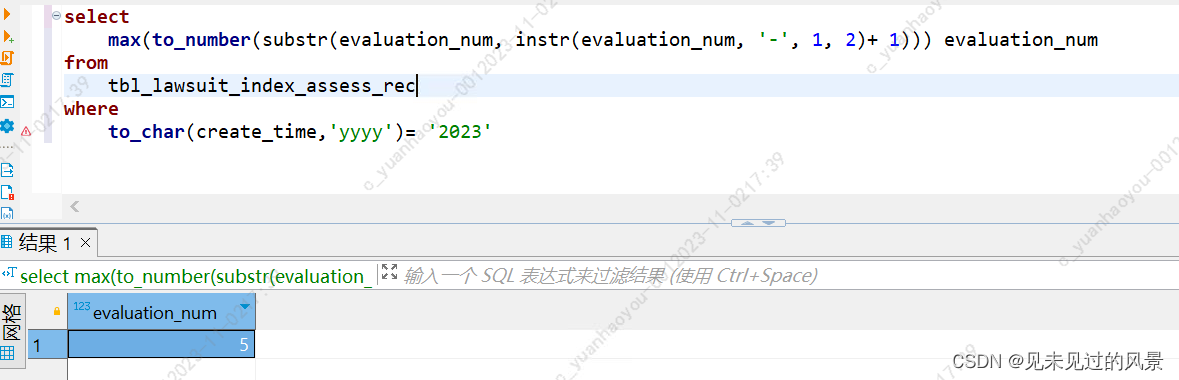
上面的sql中用到了instr函数
INSTRB(string, substring [, start_position [, nth_appearance]])
参数:
string:要搜索的字符串。
substring:要查找的子字符串。
start_position(可选):指定搜索的起始位置,默认为1。
nth_appearance(可选):指定子字符串在目标字符串中的第几次出现,默认为1。
返回值:
子字符串在目标字符串中的位置(以字节为单位)。如果未找到,则返回0。
示例:
假设有一个名为"table_name"的表,其中包含一个名为"column_name"的列,该列包含字符串数据。以下是一个使用"INSTRB"函数的示例:
SELECT INSTR('Hello World', 'World') AS position
FROM dual;
输出:
POSITION
-------- 7
在上面的示例中,函数返回的结果是7,因为子字符串"World"在目标字符串"Hello World"中的位置是第7个字节。
请注意,"INSTR"函数是按字节计算的,而不是按字符位置计算的。这意味着在处理多字节字符集(如UTF-8)时,它返回的位置可能不同于按字符位置计算的函数。
这篇关于查出来这个表中evaluation_num字段中以2023开头的最大的尾数是几,instr用法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






