本文主要是介绍Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Image,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Image
摘要:目前大多数的对比学习方法主要是像素级别的任务,但是对于像细粒度的变化检测任务需要的是像素级别的判别分析。图像级的CL特征表示可能对FCD的影响有限。为了解决这个问题作者提出了一种全局和局部的对比学习框架,可以将实力识别扩展到像素级别。GLCL遵循当前的主流CL范式,总共由四部分都成:数据增强(生成不同的数据输入视图)特征提取,GL head 和 cl head,分别执行图像级和像素级的实例识别任务。
通过GLCL 可以将同一实例不同视角的特征拉近。不同实例特征外化。,这样可以增强全局和局部特征的判别表示性,从而促进下游FCD任务。此外,GLCL 对 FCD 进行了有针对性的结构适应,即编码器网络由 FCD 的公共主干网络进行,可以加速下游 FCD 任务的部署。在几个真实数据集上的实验结果表明,与其他参数初始化方法相比,GLCL 预训练的 FCD 模型可以获得更好的检测性能。
相关工作
相关工作里 主要的是针对图像级别的分类任务,更加关注的是补货全局信息,这可能不利于像素级别的识别任务。因此在文章中提出了一种基于自监督的GLCL框架结构,将实例的识别从图像级别扩展到了像素级别,更有利于FCD任务。结构主要由四部分构成:数据增强,特征提取,全局CL,局部CL。具体来说,首先使用一些增强来生成同一图像对的不同视图。编码网络提取这些图像的特征。为了促进下游 FCD 任务的部署,编码器可以由一些常见的 CD 骨干网络直接承担。最后编码器后面链接着全局CL头和局部CL头进行图像集和像素级的判别。两个headers都包含一个投影仪,用于将特征转换为特定的维度,以及一个预测器,用于预测另一个视图的输出。区别在在于,全局CL header 将整个图像视为一个区分的实例,而local cl header将像素视为一个实例。在local CLheader l里边,由于前边数据增强的变换,局部像素级别的特征不能在同一位置对应。其他视图的相应像素级实例可以通过相似性分析找到。但在实践中,考虑到计算性能的限制和相邻像素的相似性,可以将像素级特征聚合到这些区域级特征中进行区分。全局 CL head 和局部 CL head 同时训练,这可以使特征表示逐渐变得判别,从而促进不同对象的语义区分。训练完成后,可以分离训练有素的编码器,并将其视为 CD 主干网络的良好参数初始化。然后,微调后,这些 CD 主干网络的检测性能将提高。
文章的主要贡献:1.提出了一个GLCL的自监督框架,是基于SimSam的轻量级况加,并可以快速用到下游任务,提高性能
2.GLCL框架将实例识别扩展到了像素级别的,并在像素级别和图像级别执行实例识别任务,这样可以使得编码器更好的学习到判别的特征表示。
3。在几个真实的数据机上实验表明GLCL预训练的模型可以更好的进行特征表示,提高检测性能。
相关方法A. Global–Local Contrastive Learning Framework
对于FCD来说,直接处理大量场景图像是不切实际的,,因此通常需要将图片分成更小的patch image,进行批量处理,用D 表示在同一地理区域拍摄的双时相patch 图像的集合。然后用GLCL 只使用D提取有利于CD的特征表示,而不需要任何额外的数据注释。GLCLhi利用了simsamd的轻量级设计不需要负样本和memory bank.最大的创新就是 将GLCL用于FCD任务,是网络能够学习更多的像素级别的判别表示,更有利于FCD任务。
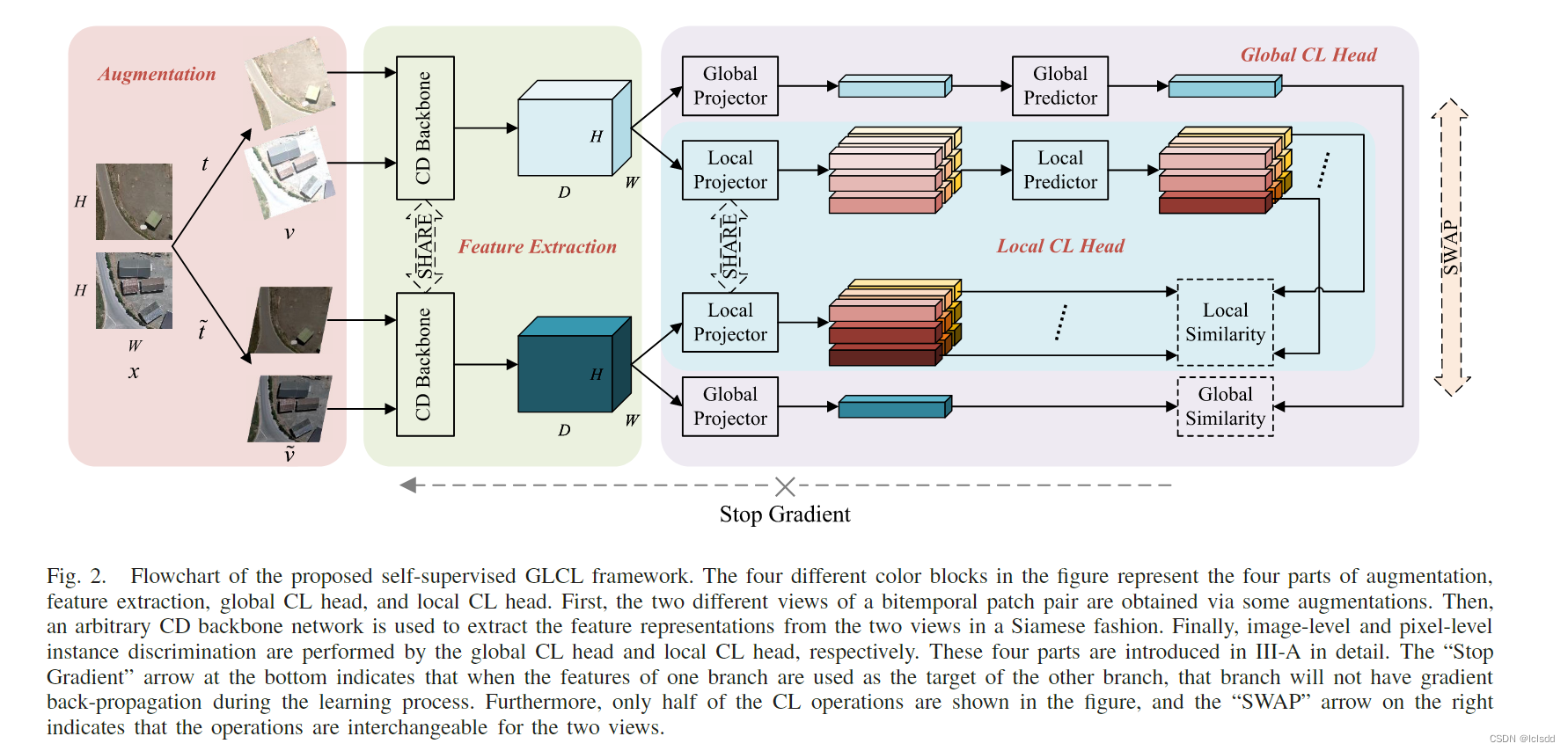
上图为GLCL的流程图,首先GLCL 通过增强的方法生成输入的patch对的两个视图。然后将增强后的图像输入到a Siamese CD 骨干网络里进行特征提取,然后将提取的特征送到全局CL 和局部CL,来形成图像级的和像素级的识别实例任务。在 CL 头中,projectors用于将特征转换为所需的特征形状,预测器用于从另一个视图预测输出。
1.数据增强 从D中随机选取patch pair,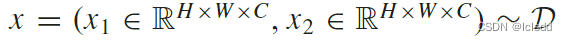 由于 CD 是输入图像对的联合分类问题,我们将 x 视为一个整体,并对两个图像使用相同的随机增强,x 的两个增强视图可以表示为
由于 CD 是输入图像对的联合分类问题,我们将 x 视为一个整体,并对两个图像使用相同的随机增强,x 的两个增强视图可以表示为
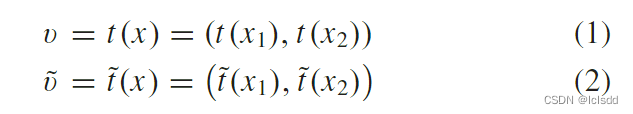
需要注意的是,选择的增强不应该导致图像内容的损失,这主要因为丢失的空间信息可能会干扰像素级别的实例区分。主要的增强方式有随机颜色抖动,随机灰度、随机高斯模糊和随机翻转,其随机概率设置与参考也一致。
特征提取: 到现在我们获取了单个patch 对的实例的不同视图,下边我们腰围后边的工作提取两个视图的特征。由于图像级别的的实例识别任务经常用于图像分类,主干网络经常采用ResNet,VGG等等来提取特征。
同样,在GLCL中,为了更快地适应下游CD任务,FCD中常用的CD骨干网可以作为特征提取器,提取两个输入patch的联合特征表示,如图2的绿色块所示。理论上,大多数 CD 模型都可以发挥这一作用,只要它们可以建立从图像对到特征的映射关系,无论它们联合特征哪个阶段,还是采用跳跃连接和注意力机制等模块,这使得 GLCL 更通用。 输入的图像经过CD网络后 生产大小为H×W×D的特征y和y1,然后送到GCL个LCL.
3) Global CL Head: GCL由两部分构成,1,全局的projector 将特征处理成所需要的形式hg,
2.一个用于预测另一个视图输出的全局预测器gg,由于全局CL头被设计为执行图像级实例识别任务。hgs首先是由几个卷积层和全连接层聚合来自于y和y1的特征并输出K维的全局特征向量,Zg 和Zg1.将其送入predictor,生成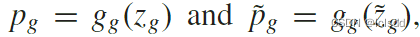
拟合另一个视图的输出,
**4) Local CL Head:**和全局CL相似,不同的是不同之处在于局部头部专注于更细粒度的特征的 CL,它将每个像素视为判别的单个实例,但是考虑到图像中的每个像素与其相邻像素具有较高的同质性,我们不能直接处理像素特征,而是聚合相邻像素区域的特征进行分析,在不影响学习效果太多的情况下,可以提高计算效率。为此,hl 采用自适应平均池化层来聚合两个视图的区域特征输出!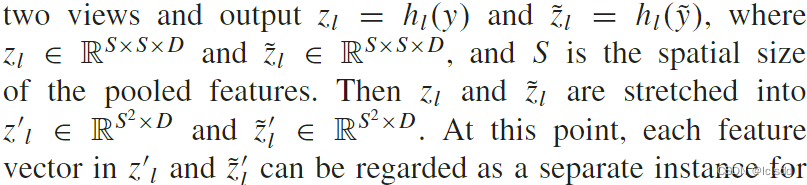
但是关键点是每个实例都需要在另一个视图中找到一个匹配实例,就像全局 CL 头所做的那样,为了解决这个问题,这里我们参考了图像配准中常用的相似性度量和匹配技术,将每个实例与其他相似度最高的视图的实例进行匹配。
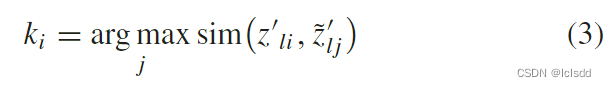
sim 是相似性度量函数,才赢余弦相似度
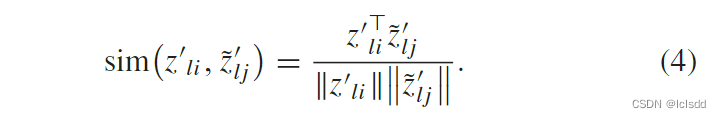

**B. 自监督对比学习
通过我们最终得到了四对预测目标,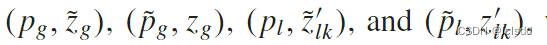 后续将用于自监督对比学习的训练。在这里,我们通过最小化负余弦相似度来优化框架。对于全局CL头损失函数为
后续将用于自监督对比学习的训练。在这里,我们通过最小化负余弦相似度来优化框架。对于全局CL头损失函数为
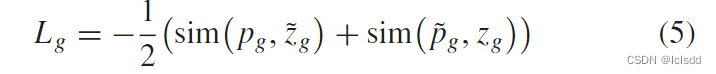
局部CL头损失函数为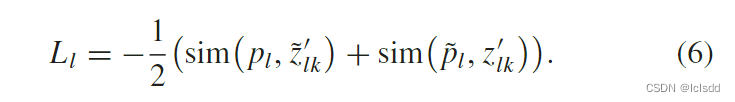
总的损失函数为

可以看出,在最终损失中考虑了全局和局部头部的贡献。通过最小化数据集 D 上的 Lon,我们可以促进前 CD 主干特征提取器来学习更具辨别力和高效的特征表示。但是需要注意的是,在优化过程中,目标分支的参数被冻结,即没有梯度反向传播,如图 2 中的底部箭头所示,这对于确保稳定的训练而不崩溃至关重要
C. Pretrained Model-Based CD
在自我监督对比训练后,作为特征提取器的 CD 主干能够提取有效的判别特征表示。此时,已经训练好的练的主干可以看作是 CD 网络的良好参数初始化状态。为了适应 CD 任务,我们只需将主干网络与 GLCL 分离,并为其后面的 CD 附加一个分类器头
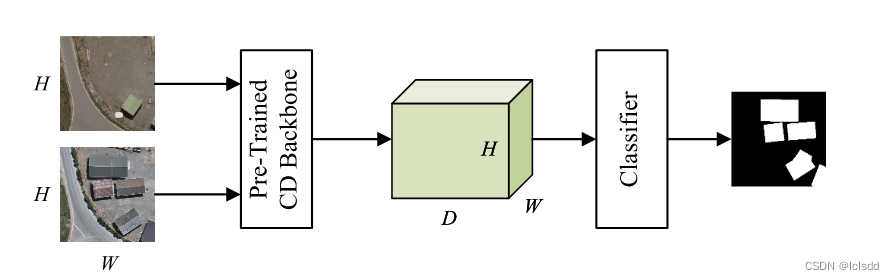
这个新集成的 CD 模型在某些带注释的训练样本 DTrain 上进行了微调,这里采用交叉熵作为训练损失函数,即
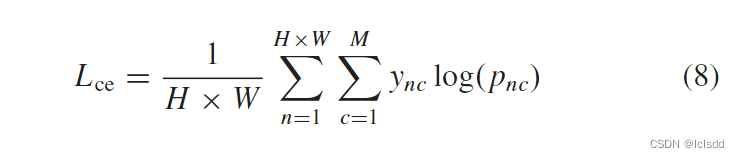
其中 H × W 是输入补丁的空间大小,M 是类别的总数,y nc ∈ {0, 1} 表示第 n 个像素是否属于第 c 个类别,p nc ∈ [0, 1] 是第 n 个像素属于类别 c 的预测概率,可以通过 Softmax 函数计算。训练后,训练好的CD模型最终可以直接用于预测未标记的样本
实验:
工采用了三个数据集 WHUCD, SECOND,SYSU,三个。实施细节:在实验中,所提出的GLCL是基于PyTorch框架[67]实现的,并在双Nvidia RTX 3090 GPU服务器上进行训练。在实现中,特征提取器由其他几个 CD 骨干网络提供服务,其结构与源论文的结构一致。因此,我们只设计了GLCL中全局和局部头部的投影器和预测器以及CD中的CD头部,其详细结构如表I所示。
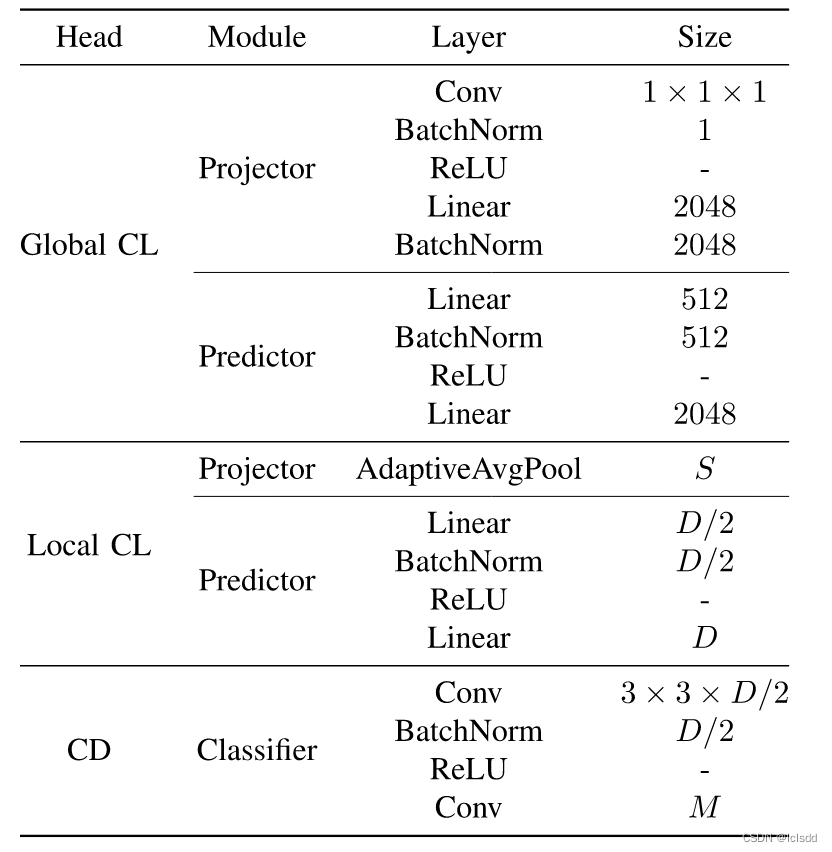
在训练期间,对于 GLCL,我们使用随机梯度下降 (SGD) 优化器,初始学习率设置为 0.001,,这与 SimSiam 中的设置一致。在下游CD任务中,我们使用了学习率为0.0001的Adam优化器。在所有阶段,采用小批量训练方式,批大小设置为4,主要考虑大数据和有限的内存大小。
3) 实验主干网络:
FC-EF,FC-Siam-Conc,FC-Siam-Diff ,SNU-Net,BIT, LGPNet
结论
提出了一种新的自监督GLCL框架,用于VHR图像中的FCD任务。整个框架设计为轻量级的,没有负样本和记忆库,大大降低了计算设备的计算能力要求,降低了下游CD任务部署的难度。在所提出的框架中,设计了两个 CL 头、全局和局部来执行图像级和像素级实例识别任务,使网络能够同时考虑全局和局部判别特征表示。基于几个代表性骨干网的两个真实数据集的实验结果表明,我们的框架具有一定的通用性、优越性和鲁棒性。在未来的工作中,我们将继续探索复杂数据条件下的学习理论和方法,以解决实际应用中困难的问题
这篇关于Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Image的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








