grained专题

Fine-Grained Egocentric Hand-Object(中文翻译)
精细化自我中心手-物体分割: 数据集、模型(model)与应用 灵芝张1, 盛昊周1, 西蒙·斯滕特 $ {}^{2} $, 和健博·石 $ {}^{1} $ 摘要。 自我中心视频提供了高保真度建模人类行为的细粒度信息。手和交互对象是理解观众行为和意图的一个关键方面。我们提供了一个标注数据集,包含11,243个自我中心图像,并具有在各种日常活动中与手和对象互动的逐像素分割标签。我们的数据集是

论文笔记|Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension
作者:迪 单位:燕山大学 论文地址 代码地址 论文来源:ACL2020 前言 由于最近的工作想要利用图结构解决问题,因此分享此文的目的是想与大家探讨如何使用图结构表达文章信息。 概述 机器阅读理解是模型在理解文本后,根据相应的问题找出对应的答案。NQ(Natural Questions)是一项新的机器阅读理解任务,它包括长答案(通常是一段话)与短答案(长答案
![[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images](https://img-blog.csdnimg.cn/20190103195855504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=,size_16,color_FFFFFF,t_70)
[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
[ACM MM 15] Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images Chen Sun, Sanketh Shettyy, Rahul Sukthankary and Ram Nevatia from USC & Google paper link Moti

Efficient object detection and segmentation forfine-grained recognition
用于细粒度识别的高效物体检测和分割 摘要 我们提出一种用于细粒度识别的检测和分割算法。该算法首先检测可能包含物体的低级区域然后通过传播分割出整个物体。除了分割物体外,我们也可以缩放物体,如将其移动到图像中心,缩放归一化,从而降低背景的影响。随后,我们证明了联合该方法和最先进的分类算法能够明显改善分类效果,尤其实在那些公认为很难识别的数据集上,比如鸟群。 该算法比已知的类似情景的算法[4,21

FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing...
原文: FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
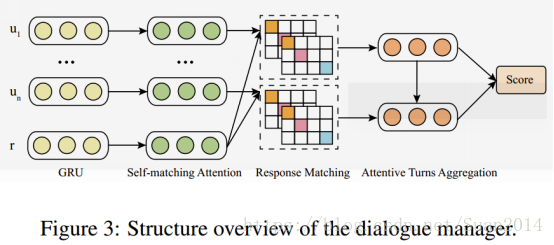
Lingke: A Fine-grained Multi-turn Chatbot for Customer Service
最近做问答系统领域,要求自己每天读一篇论文,为帮助自己理解和记忆,将要点记录在博客上 摘要 机器人类型:信息检索型机器人(给一段资料回答问题)特色功能:1)基于给定的产品说明书回答问题;2)能够应对多轮对话 方案流程

【论文解读 IJCAI 2019 | PP-GCN】Fine-grained Event Categorization with Heterogeneous GCN
论文链接:https://arxiv.org/abs/1906.04580 代码链接:https://github.com/RingBDStack/PPGCN 来源:IJCAI 2019 关键词:HIN,细粒度事件分类,hyper-edge,GCN 文章目录 1 摘要2 介绍2.1 社交事件(social event)2.2 挑战2.3 已有的工作2.4 作者提出2.5
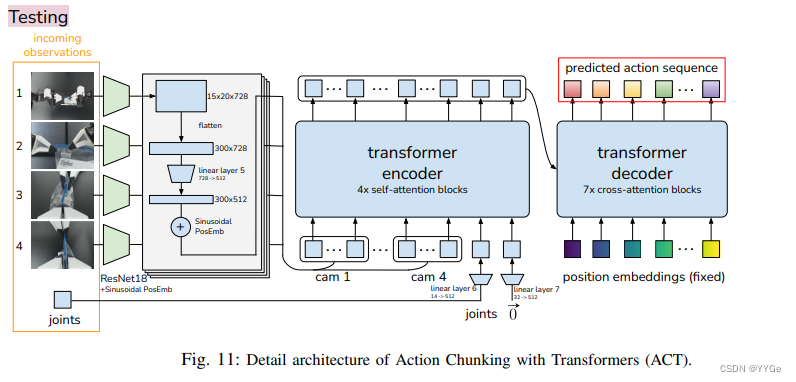
ALOHA论文翻译:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware 学习用低成本硬件进行精细双手操作 这是ALOHA 翻译,别搞混了。 Mobile ALOHA 论文翻译,请移步:Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperatio
【Oracle】设置FGA(Fine-Grained Audit)细粒度审计
文章目录 【Oracle】设置FGA(Fine-Grained Audit)细粒度审计参考 【声明】文章仅供学习交流,观点代表个人,与任何公司无关。 编辑|SQL和数据库技术(ID:SQLplusDB) 收集Oracle数据库内存相关的信息 【Oracle】ORA-32017和ORA-00384错误处理 【Oracle】设置FGA(Fine-Grained Audit)细粒度

ValseWebinar : Fine-Grained Image Analysis and Beyond
20181226魏秀参:Fine-Grained Image Analysis and Beyond SCDA(con’t) 深度描述子 同一channel 对不同物体的激活部位不同 保留最大的激活部分 pre-trained 模型 VLAD:基于一阶 Fisher:基于二阶 avg和max pool进行级连 物体协同定位
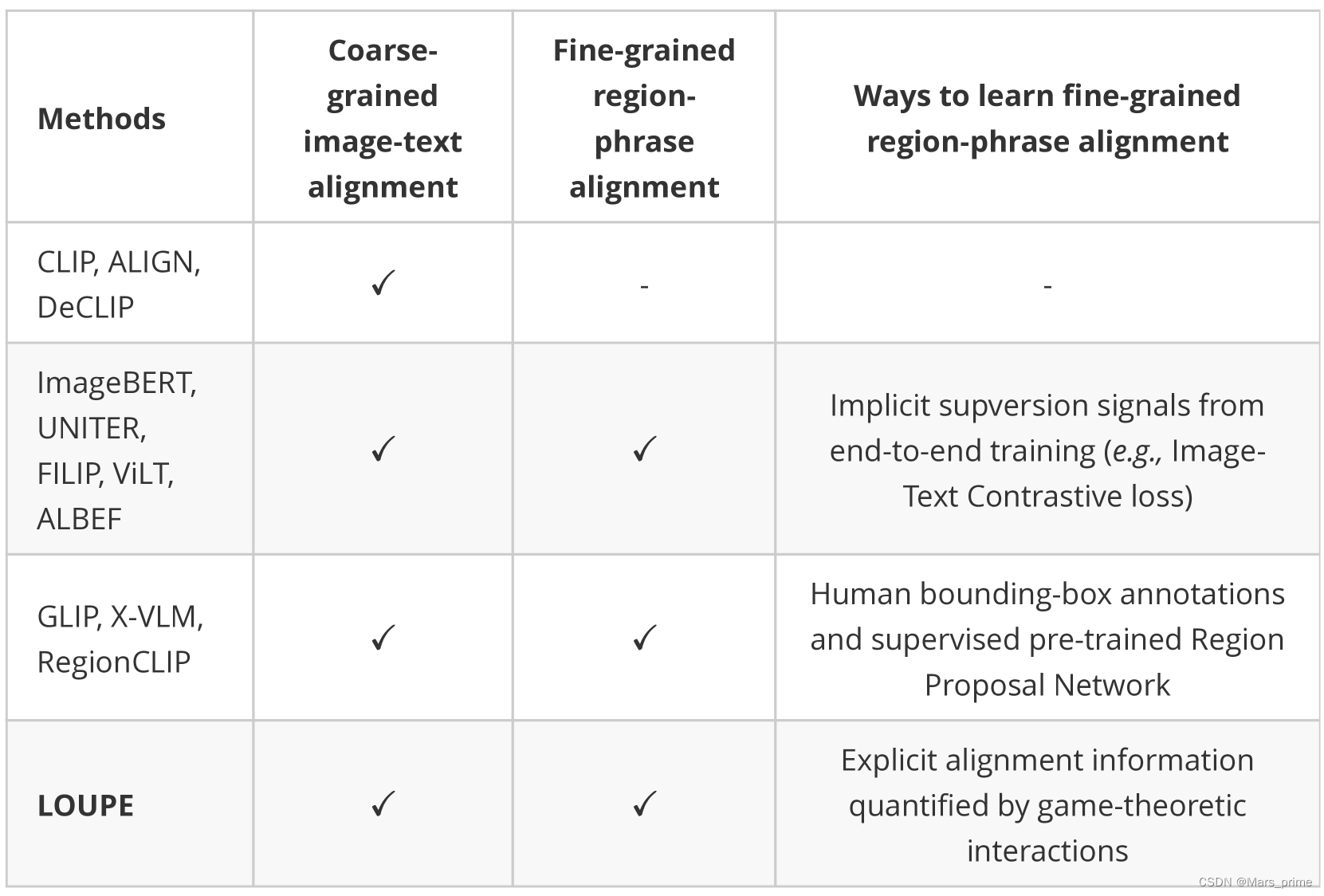
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练
abstract 大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的
论文笔记:Fine-Grained Visual Classification via PMG Training of Jigsaw Patches
Fine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches 文章目录 Fine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches
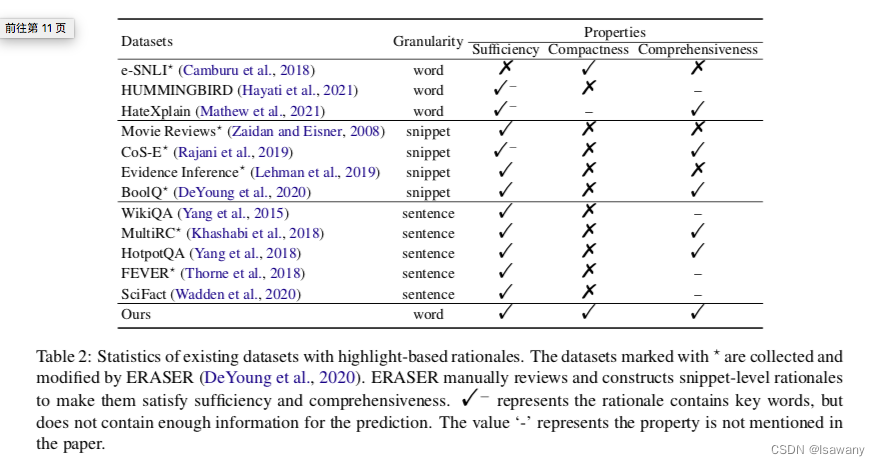
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP 1. 文章简介2. 文章概括3 文章重点技术3.1 数据收集3.2 数据扰动3.3 迭代标注和检查根因3.4 度量3.4.1 Token F1-score3.4.2 MAP(Mean Average Precision) 4. 文章亮点5. 原

CVPR 2023 精选论文学习笔记:Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR
我们给出以下四个分类标准: 1. 检索方法 监督式: 检索过程依赖于标记的训练数据来学习草图和图像之间的映射。这意味着系统在草图和它们对应的图像对上进行训练,使其能够学习视觉特征和语义概念之间的关系。监督式 SBIR 方法的例子包括支持向量机 (SVM) 和卷积神经网络 (CNN) ([1, 20, 31, 61, 66, 69])。半监督式: 半监督式方法利用标记和未标记数据来增强学习过程。
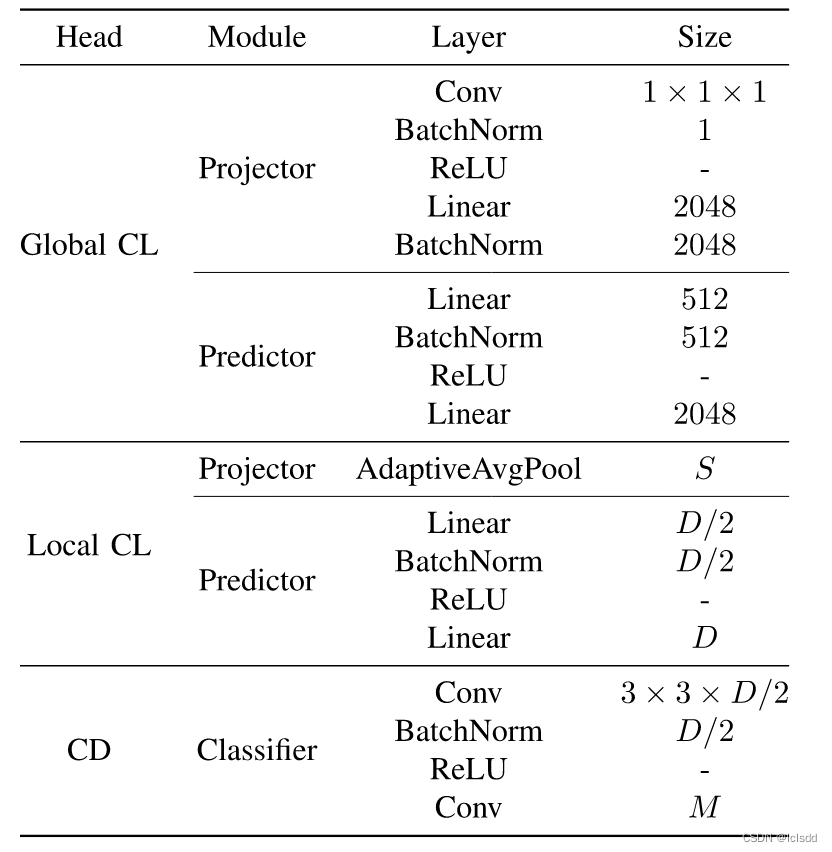
Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Image
Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Image 摘要:目前大多数的对比学习方法主要是像素级别的任务,但是对于像细粒度的变化检测任务需要的是像素级别的判别分析。图像级的CL特征表示可能对FCD的影响有限。为了解决这个问题作者提出了一种全局和局部的对比学习

多标签分类(六):Fine-Grained Lesion Annotation in CT Images with Knowledge Mined From Radiology Reports
细粒病灶注释在CT图像与知识挖掘从放射学报告 文章来自2019年CVPR 摘要 在放射科医师的日常工作中,一个主要的任务是阅读医学图像,例如CT扫描,发现重要的病变,并在放射学报告中写下句子来描述它们,在本文中,我们研究了在计算机辅助诊断(CAD)中,病灶描述或标注问题的一个重要步骤。给定一幅病变图像,我们的目标是预测多个相关标签,如损伤的身体部位、类型和属性。为了解决这个问
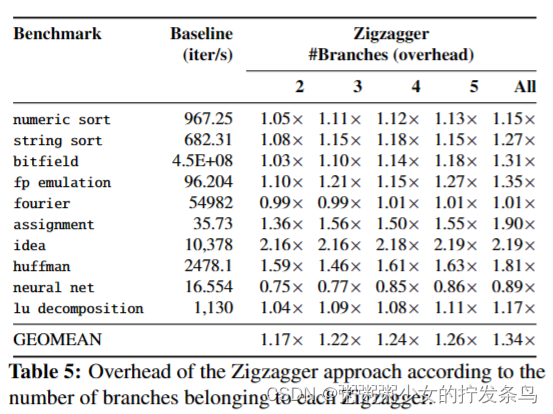
Inferring fine-grained control flow inside SGX enclaves with branch shadowing【分支预测】
目录 笔记摘要引言贡献 背景英特尔SGX分支预测历史分支记录 Branch Shadowing Attacks威胁模型概述条件分支阴影无条件分支阴影间接分支阴影频繁中断和探测虚拟地址操纵攻击同步受害者隔离 评估攻击RSA指数个案研究 防御Flushing Branch State混淆分支 讨论局限性高级攻击 相关工作总结 作者:S. Lee, M.-W. Shih, P. Gera,

更细粒度的不实信息检测|FineFact:Towards Fine-Grained Reasoning for Fake News Detection
文本推理(FinerFact) 更细粒度的不实信息检测2022 社交媒体中的不实信息(misinformation)是指通过社交网络平台传播的错误的、不准确的信息。现阶段的不实信息检测可从3个方面进行实施:(1)假新闻检测(fake news detection),即对较长文本新闻内容的真实性判别,通常以相关评论意见作为辅助;(2)谣言检测(rumor detection),多是对社交平台短文

Progressive Co-Attention Network for Fine-grained Visual Classification
一、动机 细粒度的视觉分类旨在识别属于同一类别中多个子类别的图像。由于高度混淆的类别之间存在固有的细微差异,因此这是一项具有挑战性的任务。大多数现有方法仅将单个图像作为输入,这可能会限制模型识别来自不同图像的对比线索的能力。在本文中,我们提出了一种有效的方法,称为渐进式共同注意力网络(PCA-Net)来解决这个问题。具体来说,我们通过鼓励同类别图像对内的特征通道之间的互动来计算通道的相似性,以捕

Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification 论文学习
论文地址:https://arxiv.org/pdf/2108.08728.pdf Github地址:https://github.com/raoyongming/CAL Abstract 注意力机制在细粒度视觉分类任务上非常有效。本文介绍了一个反事实的注意力学习方法,基于因果推理来学习更加有效的注意力。现有的方法都基于传统的概率来学习注意力,本文作者提出利用反事实因果关系来学习注意力,为评价

Text to image论文精读 AttnGAN: Fine-Grained TexttoImage Generation with Attention(带有注意的生成对抗网络细化文本到图像生成)
AttnGAN: Fine-Grained TexttoImage Generation with Attention(带有注意的生成对抗网络细化文本到图像生成) 一、摘要二、关键词三、为什么提出AttnGAN?四、主要原理4.1、两大核心组成4.2 、损失函数 五、框架分析六、生成网络中的注意力机制6.1、生成网络注意力框架6.2、实现细节2.1、第一步6.2、第二步6.3、第三步 七、

Image Fine-grained Inpainting
1. Motivation 传统方法不能生成新的内容;现有的基于深度学习的方法会产生不合理的结构和模糊。 2. Approach 2.1 Network Architecture 生成器:每个“convolution + norm”都有一个激活函数,最后一层的激活函数是Tanh,其他层的函数都是ReLU。生成器的中间部分包含DMFB(dense multi-scale fusion

Fine-grained Cross-modal Alignment Networkfor Text-Video Retrieval--文献阅读翻译
题目:Fine-grained Cross-modal Alignment Networkfor Text-Video Retrieval 作者:Ning Han Hunan University ninghan@hnu.edu.cn Jingjing Chen∗ Fudan University chenjingjing@fudan.edu.cn