本文主要是介绍Inferring fine-grained control flow inside SGX enclaves with branch shadowing【分支预测】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 笔记
- 摘要
- 引言
- 贡献
- 背景
- 英特尔SGX
- 分支预测
- 历史分支记录
- Branch Shadowing Attacks
- 威胁模型
- 概述
- 条件分支阴影
- 无条件分支阴影
- 间接分支阴影
- 频繁中断和探测
- 虚拟地址操纵
- 攻击同步
- 受害者隔离
- 评估
- 攻击RSA指数
- 个案研究
- 防御
- Flushing Branch State
- 混淆分支
- 讨论
- 局限性
- 高级攻击
- 相关工作
- 总结
作者:S. Lee, M.-W. Shih, P. Gera, T. Kim, H. Kim, and M. Peinado. Inferring
发布:USENIX Security Symposium(计算机安全顶会)
时间:2017
笔记
BranchShadowing
1、动机
(1)与之前的侧通道(如缓存定时通道)不同,页面故障侧通道是确定性的;也就是说,它没有测量噪声,但它只揭示粗粒度的页面级访问模式
(2)此外,研究人员最近提出了对抗页面攻击的对策,如基于平衡执行的设计[50]和用户空间页面故障检测[10,49,50]。然而,这些方法只能防止页面级攻击;因此,细粒度的侧通道攻击(如果存在)将很容易绕过它们。
(3)一个关键的观察结果是Intel SGX在飞地模式切换期间未清除分支历史记录
2、攻击原理
(1)BTB
①SGX在从飞地模式切换到非命名模式时没有清除分支历史,留下了细粒度的痕迹供外界观察,从而产生了分支预测侧通道
②攻击者可以通过定位映射到与目标分支指令相同的BTB条目的影子分支指令(§6.2)来引入集合冲突
③之后,攻击者可以通过执行影子分支指令来探测共享BTB条目,并根据执行时间确定目标分支指令是否已被执行
(2)威胁模型
①攻击者知道目标飞地程序的可能控制流(即分支序列指令及其目标)
②不可观察的代码(例如,自修改代码和来自远程服务器的代码)不在我们的攻击范围内
③攻击者可以将目标飞地程序映射到特定的内存地址,以指定每个分支指令的位置及其目标地址
④飞地内的自分页[22]和地址空间布局的实时重新随机化[15]不在我们的攻击范围内
(3)防御
①修改硬件或更新微码来清除包围区内生成的所有分支状态
1)由于BTB和BPU受益于局部和全局分支执行历史记录,如果这些状态刷新得太频繁,将导致性能损失
②分支状态刷新
③移除分支[39]或使用最先进的ORAM技术Raccoon[44]
1)特定于算法的,即不适用于一般应用
2)性能开销很高
④Zigzaggar
1)它将一组分支指令混淆为单个间接分支,因为推断间接分支的状态比推断条件和无条件分支的状态更困难(§3.5)
2)引入一系列非条件跳转指令来代替每个分支
3)它将所有有条件和无条件分支转换为无条件分支
(4)局限性
①它不能区分未执行的条件分支和未执行的有条件分支,因为在这两种情况下,BTB都不存储信息
②它无法区分下一条指令的间接分支和未执行的间接分支,因为它们的预测分支目标相同。由此,攻击者必须探测多个相关分支(例如,无条件分支不包含if或case块)来克服这些限制
③需要重复以提高攻击精度,这可以通过状态连续性解决方案来禁止
④需要持久性存储,例如由可信平台模块(TPM)提供的存储
⑤在条件分支和间接分支的情况下,盲探测需要同时考虑分支指令及其目标,这样搜索空间将是巨大的
⑥如果受害者飞地进程具有自修改代码或使用远程代码加载,则此攻击是必要的,尽管这超出了我们的威胁模型(§3.1)的范围
摘要
英特尔推出了一种基于硬件的可信执行环境“英特尔软件保护扩展”(SGX),它为用户程序提供了一个安全、独立的执行环境或飞地,而不信任任何底层软件(如操作系统)或固件。研究人员已经证明SGX很容易受到基于页面错误的攻击。然而,该攻击只揭示了飞地内的页面级内存访问。
在本文中,我们探索了一种新的但关键的侧通道攻击,分支阴影,它揭示了飞地中的细粒度控制流(分支粒度)。这种攻击的根本原因是SGX在从飞地模式切换到非命名模式时没有清除分支历史,留下了细粒度的痕迹供外界观察,从而产生了分支预测侧通道。然而,在实践中利用这个通道是具有挑战性的,因为1)测量分支执行时间对于区分细粒度的控制流变化来说过于嘈杂,2)在飞地执行了我们目标的代码块之后立即暂停飞地需要复杂的控制。为了克服这些挑战,我们开发了两种新的开发技术:1)基于最后分支记录(LBR)的历史推断技术和2)基于高级可编程中断控制器(APIC)的技术,以细粒度的方式控制飞地的执行。针对RSA的评估表明,我们的攻击推断每个私钥比特的准确率为99.8%。最后,我们深入研究了基于硬件的解决方案(即分支历史刷新)的可行性,并提出了一种基于软件的方法来缓解攻击。
引言
建立可信执行环境(TEE)是最重要的安全要求之一,尤其是在公共云或可能受损的操作系统(OS)等恶意计算平台中。当我们想在公共云中运行安全敏感的应用程序(例如处理财务或健康数据)时,我们需要完全信任运营商,这是有问题的[16],或者在将所有数据上传到云之前对其进行加密,并直接对加密的数据进行计算。后者可以基于仍然较慢的全同态加密[42],也可以基于较弱的属性保留加密[17,38,43]。即使当我们使用私有云或个人工作站时,也存在类似的问题,因为考虑到其庞大的代码库和高复杂性,没有人能够确保底层操作系统对攻击具有鲁棒性[2,18,23,28,36,54]。由于操作系统原则上是计算平台可信计算基础的一部分,因此攻击者可以通过对其进行破坏来完全控制平台上运行的任何应用程序。
业界一直在积极提出基于硬件的技术,如支持TEE的可信平台模块(TPM)[56]、ARM TrustZone[4]和英特尔软件保护扩展(SGX)[24]。具体而言,英特尔SGX因其最近的可用性和适用性而备受关注。所有Intel Skylake和Kaby Lake CPU都支持Intel SGX,由Intel SGX保护的进程(即在飞地内运行的进程)几乎可以无限制地使用每一条无特权的CPU指令。在某种程度上,我们可以信任硬件供应商(即,如果不存在硬件后门[61]),则认为基于硬件的TEE是安全的。
不幸的是,最近的研究[50,60]表明,英特尔SGX有一个无噪声的侧信道——一种受控信道攻击。SGX允许操作系统完全控制飞地进程的页面表;也就是说,OS可以映射或取消映射飞地的任意存储器页。这种功能使恶意操作系统能够通过监视页面故障来准确地知道受害者飞地试图访问哪些内存页面。与之前的侧通道(如缓存定时通道)不同,页面故障侧通道是确定性的;也就是说,它没有测量噪声。
受控通道攻击有一个局限性:它只揭示粗粒度的页面级访问模式。此外,研究人员最近提出了对抗攻击的对策,如基于平衡执行的设计[50]和用户空间页面故障检测[10,49,50]。然而,这些方法只能防止页面级攻击;因此,细粒度的侧通道攻击(如果存在)将很容易绕过它们。
我们已经彻底检查了英特尔SGX,以确定它是否有一个关键的侧通道,可以显示细粒度的信息(即,比页面级别的粒度更细),并且对噪声具有鲁棒性。一个关键的观察结果是Intel SGX在飞地模式切换期间未清除分支历史记录。了解分支历史(即已执行或未执行的分支)至关重要,因为它可以根据基本块揭示流程的细粒度执行痕迹。为了避免此类问题,Intel SGX将所有与性能相关的事件(例如,分支历史记录和缓存命中/未命中)隐藏在硬件性能计数器的飞地内,包括基于事件的精确采样(PEBS)、最后一个分支记录(LBR)和Intel处理器跟踪(PT),即所谓的抗侧信道干扰(ASCI)[24]。因此,操作系统无法直接监控和操作飞地进程的分支历史。然而,由于Intel SGX不清除分支历史记录,控制操作系统的攻击者可以通过分支预测侧通道推断飞地的细粒度执行轨迹[3,12,13]。
分支预测侧通道攻击旨在识别目标分支指令的历史是否存储在CPU内部分支预测缓冲器中,即分支目标缓冲器(BTB)中。BTB在飞地和其底层操作系统之间共享。利用BTB仅使用最低31个地址位的事实(§2.2),攻击者可以通过定位映射到与目标分支指令相同的BTB条目的影子分支指令(§6.2)来引入集合冲突。之后,攻击者可以通过执行影子分支指令来探测共享BTB条目,并根据执行时间确定目标分支指令是否已被执行(§3)。一些研究人员利用这个侧通道来推断密钥[3],创建一个隐蔽通道[12],并打破地址空间布局随机化(ASLR)[13]。
然而,由于以下原因,这种攻击在实践中很难进行。首先,由于ASLR,攻击者无法轻易猜测分支指令的地址并操纵其分支目标的地址。其次,由于BTB的容量有限,在攻击者探测到条目之前,条目很容易被其他分支指令覆盖。第三,分支预测失误惩罚的定时测量受到高噪声水平的影响(§3.3)。总之,攻击者应该有1)自由访问或操纵虚拟地址空间的权限,2)在BTB之前的任何时间访问BTB以及3)识别具有可忽略(或无)噪声的分支预测失误的方法。
在本文中,我们提出了一种新的分支预测侧通道攻击,即分支阴影,它可以准确地推断出没有噪声(用于识别条件分支和间接分支)或噪声可忽略(用于识别无条件分支)的包围区的细粒度控制流。恶意操作系统可以很容易地操纵飞地进程的虚拟地址空间,因此很容易在飞地中创建与目标分支指令冲突的影子分支指令。为了最大限度地减少测量噪声,我们确定了比使用RDTSC更精确的替代方法,包括Intel PT和LBR(§3.3)。更重要的是,我们发现Skylake CPU中的LBR使我们能够获得分支阴影的最准确信息,因为它报告每个条件或间接分支指令是正确预测还是预测错误。也就是说,我们可以准确地知道条件分支和间接分支的预测和预测失误(§3.3,§3.5)。此外,Skylake CPU中的LBR报告了LBR条目更新之间经过的核心周期,根据我们的测量结果,这些核心周期非常稳定(§3.3)。通过使用这些信息,我们可以精确地推断无条件分支的执行情况(§3.4)。
精确的执行控制和频繁的分支历史探测是分支阴影的其他重要要求。为了实现这些目标,我们尽可能频繁地操作本地高级可编程中断控制器(APIC)定时器的频率,并使定时器中断代码执行分支阴影。此外,当需要更精确的攻击时,我们会选择性地禁用CPU缓存(§3.6)。
我们针对mbed TLS中的RSA实现评估了分支阴影(§4)。在攻击滑动窗口RSA-1024解密时,我们成功地推断出RSA私钥的每个比特,准确率为99.8%。此外,与现有的缓存定时攻击不同,该攻击只运行一次解密,就恢复了66%的私钥位[20,35,65],而现有的缓存时间攻击通常需要数百到数万次迭代。
最后,我们提出了针对分支阴影的基于硬件和软件的对策,分别在包围区模式切换期间刷新分支状态并利用具有多个目标的间接分支(§5)。
贡献
细粒度攻击。我们证明了分支阴影可以成功地根据基本块识别飞地内的细粒度控制流信息,而不像最先进的受控通道攻击那样只显示页面级访问。
精准攻击。我们通过1)利用Intel PT和LBR来正确识别分支历史,2)调整本地APIC定时器,以精确控制包围区内的执行。我们可以确定地知道,对于条件分支和间接分支,是否在没有噪声的情况下获取目标分支,而对于无条件分支,是否可以忽略噪声。
对策。我们设计了基于概念验证的硬件和软件对抗攻击的对策,并对其进行了评估。
背景
我们解释了与我们的攻击密切相关的Intel SGX和其他两个处理器功能,分支预测和LBR。
英特尔SGX
Intel CPU通过安全扩展Intel SGX支持基于硬件的TEE。SGX提供了一组指令,允许应用程序实例化一个飞地,该飞地针对特权软件(如操作系统或系统管理程序、硬件固件,甚至CPU以外的硬件单元)保护代码和数据。为了提供这样的保护,SGX强制执行了一种严格的内存访问机制:只允许飞地代码访问同一飞地的内存。此外,SGX利用片上存储器加密引擎,在将包围区内容写入物理存储器之前对其进行加密,并仅在包围区执行或包围区模式期间当加密内容进入CPU包时对其进行解密。
Enclave上下文开关。为了支持飞地和非飞地模式之间的上下文切换,SGX提供了诸如EENTER和EEXIT之类的指令,EENTER启动飞地执行,EEXIT终止飞地执行。此外,ERESUME在异步飞地退出(AEX)发生后恢复飞地执行。AEX的原因包括异常和中断。在上下文切换期间,SGX进行一系列检查和操作以确保安全性,例如,刷新translation lookaside buffer(TLB)。然而,我们观察到SGX并没有清除所有缓存的系统状态,例如分支历史记录(§3)。
分支预测
分支预测是现代流水线处理器最重要的特性之一。在高层,指令管道由四个主要阶段组成:获取、解码、执行和写回。在任何给定的时间,都有许多指令在执行中。处理器利用指令级并行性和无序执行来最大限度地提高吞吐量,同时仍然保持指令的有序退役。分支指令会严重降低指令吞吐量,因为处理器在确定分支的目标和结果。除非得到缓解,否则分支将导致管道停滞,也称为泡沫。因此,现代处理器使用分支预测单元(BPU)来预测分支结果和分支目标。虽然BPU通常会提高吞吐量,但值得注意的是,在预测错误的情况下,会有相当高的惩罚,因为处理器需要清除管道并回滚任何推测性执行结果。这就是英特尔提供专用硬件功能(LBR)来评测分支执行的原因(§2.3)。
分支和分支目标预测。分支预测是一种通过猜测是否执行条件分支来预测下一条指令的过程。分支目标预测是在执行分支之前预测和获取分支的目标指令的过程。对于分支目标预测,现代处理器具有BTB来存储所获取的分支指令的计算目标地址,并在相应的分支指令被预测为已获取时获取这些地址。
BTB结构和部分标记命中。BTB是一种类似于缓存的关联结构。地址位用于计算集合索引和标记字段。用于设置索引的位数由BTB的大小决定。与使用标签的所有剩余地址位的高速缓存不同,BTB使用标签的剩余位的子集(即,部分标签)。例如,在64位地址空间中,如果ADDR[11:0]被用于索引,而不是将ADDR[63:12]用于标签,则只有部分比特数(例如ADDR[31:12])被用作标签。这种选择的原因如下:首先,与数据缓存相比,BTB的大小非常小,完整标签的开销可能非常高。其次,在一个程序中,高阶比特通常是相同的。第三,与缓存不同,缓存需要保持准确的微体系结构状态,BTB只是一个预测因子。即使部分标签命中导致错误的BTB命中,也会在执行阶段计算正确的目标,如果预测错误(即,它只影响性能,而不影响正确性),则管道将回滚。
静态和动态分支预测。静态分支预测是一种默认规则,用于在没有历史记录的情况下预测分支指令之后的下一条指令[25]。首先,处理器预测前向条件分支——一个目标地址高于其自身的条件分支——将不会被采用,这意味着下一条指令将被直接获取(即,一条直通路径)。其次,处理器预测将采用向后条件分支——目标地址低于其自身的条件分支;也就是说,将提取指定的目标。第三,处理器预测不会采用间接分支,类似于前向条件分支的情况。第四,处理器预测将采用无条件分支,类似于后向条件分支的情况。相反,当分支在BTB中有历史时,处理器将根据历史预测下一条指令。此过程称为动态分支预测。
在本文中,我们利用这两种条件分支行为来推断英特尔SGX内部运行的受害进程的控制流(§3)。
历史分支记录
LBR是Intel CPU中的一项新功能,它记录有关最近执行的分支的信息(即,省略有关未执行分支的信息),而不会降低任何性能,因为它与指令管道分离[26,32,33]。在Skylake CPU中,LBR存储多达32个最近分支的信息,包括分支指令的地址(from)、目标地址(to)、分支方向或分支目标是否预测错误(它不会独立报告这两个预测错误),以及LBR条目更新之间经过的核心周期(也称为定时LBR)。在没有过滤的情况下,LBR记录所有类型的分支,包括函数调用、函数返回、间接分支和条件分支。此外,LBR可以选择性地记录在用户空间、内核空间或两者中进行的分支。
由于LBR揭示了最近采取的分支的详细信息,如果攻击者可以直接使用LBR来对付飞地进程,则攻击者可能能够知道飞地进程的细粒度控制流,尽管他或她仍然需要处理未采取的分支和LBR的有限容量的机制。对攻击者来说不幸的是,对受害者来说幸运的是,飞地不会向LBR报告其分支执行,除非它处于调试模式[24]以防止此类攻击。然而,在§3中,我们展示了攻击者如何在处理未采取的分支并克服LBR容量限制的同时,对飞地进程间接使用LBR。
Branch Shadowing Attacks
我们解释了分支阴影攻击,它可以推断飞地的细粒度控制流信息。我们首先介绍了我们的威胁模型,并描述了我们如何攻击三种类型的分支:条件分支、无条件分支和间接分支。然后,我们根据执行时间和内存地址空间来描述我们同步受害者和攻击代码的方法。
威胁模型
我们解释了我们的威胁模型,该模型基于Intel SGX的原始威胁模型和受控通道攻击[60]:攻击者破坏了操作系统,并利用它攻击目标飞地程序。
首先,攻击者知道目标飞地程序的可能控制流(即分支序列指令及其目标)。这与在飞地内运行未修改的遗留代码的重要用例一致[5,6,51,57]。不可观察的代码(例如,自修改代码和来自远程服务器的代码)不在我们的攻击范围内。此外,攻击者可以将目标飞地程序映射到特定的内存地址,以指定每个分支指令的位置及其目标地址。飞地内的自分页[22]和地址空间布局的实时重新随机化[15]不在我们的攻击范围内。
其次,攻击者通过可观察的事件推断目标飞地运行的代码的哪一部分,例如,调用飞地外的函数和页面错误。攻击者使用此信息将目标代码的执行与分支影子代码同步(§3.8)。
第三,攻击者尽可能频繁地中断目标飞地的执行,以运行分支影子代码。这可以通过操作本地APIC计时器和/或禁用CPU缓存来完成(§3.6)。
第四,攻击者通过监控硬件性能计数器(例如LBR)或测量分支预测失误惩罚来识别影子代码的分支预测和预测失误[3,12,13]。
最后,攻击者阻止目标飞地访问可靠、高分辨率的时间源,以避免由于速度减慢而检测到攻击。为每个中断或页面故障探测目标飞地会减慢飞地的速度,因此攻击者需要隐藏它。SGX版本1已经满足了这样的要求,因为它不允许RDTSC。对于SGX版本2(尚未发布),攻击者可能需要操纵特定型号寄存器(MSR)来挂接RDTSC。尽管目标飞地可能依赖于外部时间源,但由于网络延迟和开销,它也不可靠。此外,攻击者可以故意丢弃或延迟此类数据包。
概述
分支阴影攻击的目的是通过1)知道分支指令是否已被占用和2)推断所占用分支的目标地址来获得飞地程序的细粒度控制流。为了实现这一目标,攻击者首先需要分析受害者飞地程序的源代码和/或二进制代码,以找到所有分支及其目标地址。接下来,攻击者为一组分支编写影子代码,以探测其分支历史,这类似于Evtyushkin等人使用BTB[13]的攻击。由于单独使用BTB和BPU会受到显著噪声的影响,分支阴影利用了LBR,这使攻击者能够准确识别所有分支类型的状态(§3.3、§3.4、§3.5)。由于BTB、BPU和LBR的大小限制,分支阴影攻击必须在执行时间和内存地址空间方面同步受害者代码和阴影代码的执行。我们操纵本地APIC定时器和CPU缓存(§3.6),以频繁中断飞地进程执行进行同步,调整虚拟地址空间(§3.7),并运行影子代码,以查找飞地进程当前正在运行或刚刚完成运行的函数(§3.8)。
条件分支阴影
我们解释了攻击者如何通过跟踪分支历史来知道飞地内的目标条件分支是否已被占用。对于条件分支,我们专注于识别分支预测是否正确,因为它揭示了if语句或循环的条件求值结果。请注意,在本节和后面的章节中,我们主要关注将被预测为不被静态分支预测规则采用的前向条件分支(§2.2)。攻击后向条件分支基本上是一样的,因此我们在本文中跳过对它的解释。

通过时间推断(RDTSC)。首先,我们解释了如何使用RDTSC推断分支预测失误。图1显示了一个受害者代码及其影子代码的示例。受害者代码的执行取决于a的值:如果a不为零,则不会执行分支,从而执行if块;否则,将执行该分支,从而执行else块。相反,我们使影子代码的分支总是被执行(即,else块总是被执行)。在没有分支历史的情况下,由于静态分支预测规则(§2.2),该分支总是预测错误。为了产生BTB条目冲突[13],我们将影子代码地址(分支指令及其目标地址)的低31位与受害代码的地址对齐。
当在执行影子代码之前已经执行了受害代码时,影子代码的分支预测或预测错误取决于受害代码的执行。如果受害者代码的条件分支已被采用,即如果a为零,则BPU预测影子代码也将采用条件分支,这是正确的预测,从而不会发生回滚。如果受害者代码的条件分支没有被执行,即,如果a不是零,或者还没有执行,则BPU预测影子代码将不会执行条件分支。但是,这是一个错误的预测,因此会发生回滚。
以前的分支定时攻击试图用RDTSC或RDTSCP指令测量这样的回滚惩罚。然而,我们的实验表明(表 1)分支错误预测时间非常嘈杂。因此,很难在正确预测和错误预测之间设置明确的边界。这是因为在给定最新 Intel CPU(例如,乱序执行)的高度复杂的内部结构的情况下,由于分支错误预测而被错误地执行的指令数量很难预测。因此,我们认为基于rdtc的推理在实践中很难使用,因此我们的目标是使用LBR来实现精确的攻击,因为它让我们知道分支错误预测信息,其经过的循环特征几乎没有噪声(表1)。
从执行跟踪推断(英特尔PT)。我们可以使用Intel PT来测量目标分支的预测失误惩罚,而不是使用RDTSC,因为它提供了每个PT数据包之间精确的运行周期(称为CYC数据包)。但是,CYC数据包不能立即用于我们的目的,因为Intel PT将一系列有条件和无条件分支聚合为一个数据包作为优化。为了避免这个问题,我们有意在目标分支之后插入一个间接分支,使所有分支在单独的CYC数据包中正确记录它们的运行时间。与基于RDTSCP的测量相比,Intel PT关于分支预测失误的定时信息的方差要小得多(表1)。
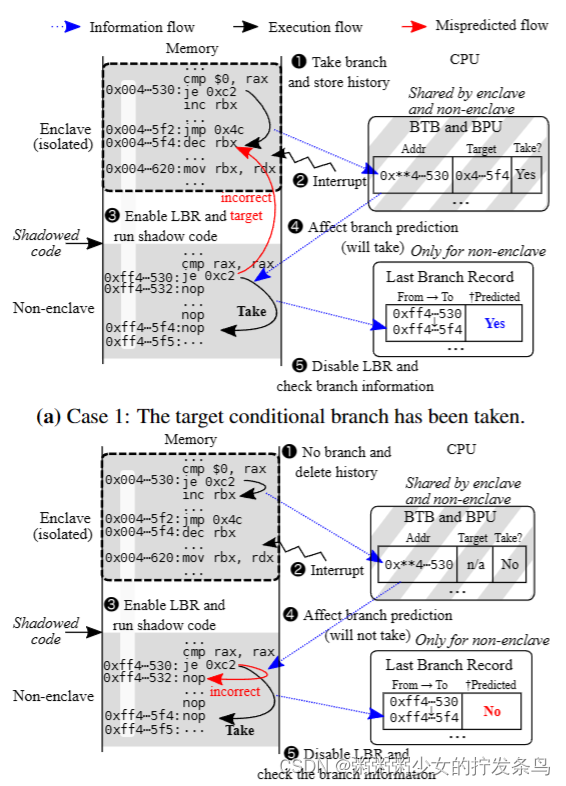

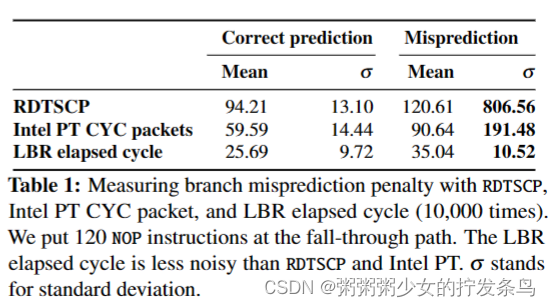
精确泄漏(LBR)。图2显示了使用BTB、BPU和LBR进行条件分支遮蔽的过程。我们首先解释一个条件分支被取下的情况(情况1)。(1)获取受害者代码的条件分支,并将相应的信息存储到BTB和BPU中。此分支发生在包围区内,因此除非我们在调试模式下运行包围区进程,否则LBR不会报告此信息。(2)飞地执行中断OS进行控制。我们在§3.6中解释了恶意操作系统如何频繁中断飞地进程。(3)操作系统启用LBR,然后执行影子代码。(4) BPU正确地预测将采用阴影条件分支。此时,分支目标预测将失败,因为BTB将目标地址存储在包围区内。然而,这种目标预测失误与分支预测的结果正交,尽管它会在CPU周期中引入惩罚(§3.4)。(5)最后,通过禁用和检索LBR,我们了解到阴影条件分支已被正确预测——它已被视为已预测。我们认为这个正确的预测是关于分支预测的,因为两个分支指令的目标地址不同;也就是说,目标预测可能失败。请注意,默认情况下,LBR报告用户和内核空间中发生的所有分支(包括函数调用)。由于我们的影子代码没有函数调用,并且是在内核中执行的,所以我们使用LBR的过滤忽略用户空间中的每个函数调用和所有分支的机制。
接下来,我们解释其中没有采取条件分支的情况(情况2)。(1)受害者代码的条件分支没有被采用,因此BTB和BPU中没有存储任何信息,或者相应的旧信息可能会被删除(如果同一BTB集合中遗漏了冲突)(2) Enclave执行被中断,OS获得控制权。(3)操作系统启用LBR,然后执行影子代码。(4) BPU错误地预测阴影条件分支不会被执行,因此执行被回滚以执行该分支。(5)最后,通过禁用和检索LBR,我们了解到阴影条件分支被预测错误——它与分支预测不同。
正在初始化分支状态。当预测一个条件分支时,现代BPU利用该分支以前的几次执行来提高预测精度。例如,如果一个分支被执行了几次,而不是只执行了一次,那么BPU就会预测它的下一次执行会被执行。这将使影子分支在多次执行目标分支(例如,在循环内)后错误地推断目标分支的执行。为了解决这个问题,在每次攻击迭代的最后一步之后,我们额外地多次运行影子代码,同时改变条件(即交错已执行和未执行的分支)来初始化分支状态。
无条件分支阴影
我们解释了攻击者如何通过跟踪分支历史来知道飞地内的目标无条件分支是否已被执行。这给了我们两种信息。首先,攻击者可以推断飞地内的指令指针(IP)当前指向的位置。其次,攻击者可以推断if-else语句的条件求值结果,因为if块的最后一条指令是跳过相应else块的无条件分支。
与条件分支不同,总是采用无条件分支;即不需要分支预测。因此,为了识别其行为,我们需要转移其目标地址以观察分支目标预测失误,而不是分支预测失误。有趣的是,我们发现LBR不会报告无条件分支的分支目标预测错误;它总是说,每个采取的无条件分支都是正确预测的。因此,我们使用LBR报告的分支的运行周期来识别分支目标预测失误惩罚,该惩罚比RDTSC噪声更小(表1)。
攻击程序。图3显示了无条件分支阴影的过程。与条件分支遮蔽不同,我们使遮蔽的无条件分支的目标与受害者的目标不同以识别分支目标预测失误。我们首先解释执行无条件分支的情况(情况3)。(1)执行受害者代码的无条件分支,并将相应的信息存储到BTB和BPU中。(2) Enclave执行被中断,操作系统获得控制权。(3)操作系统启用LBR,然后执行影子代码。(4)由于分支历史不匹配,BPU错误预测了阴影无条件分支的分支目标,因此执行回滚到正确的目标。(5)影子代码执行一个额外的分支,以测量预测错误的分支所经过的周期。(6)最后,通过禁用和检索LBR,我们了解到由于经过了大量的周期,导致了分支目标预测失误。
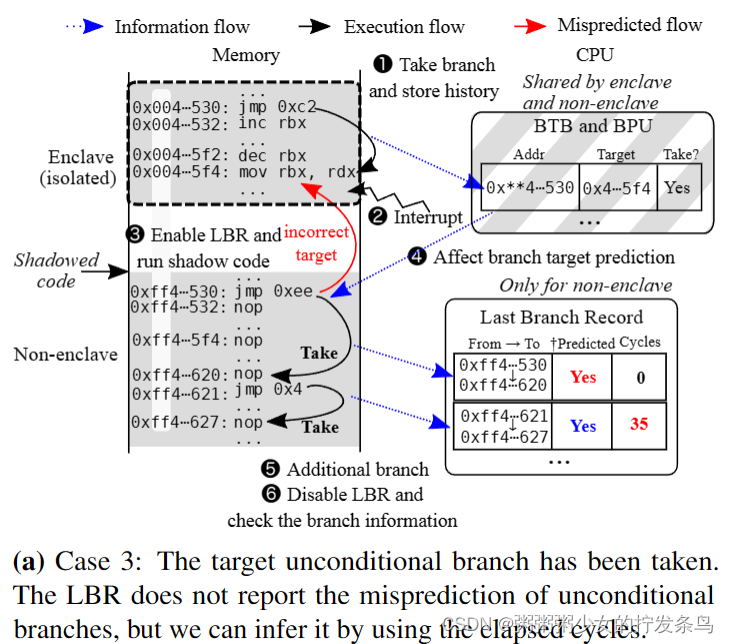

接下来,我们解释没有采取无条件分支的情况(情况4)。(1)飞地尚未执行受害者代码中的无条件分支,因此BTB没有关于该分支的信息。(2) Enclave执行被中断,操作系统获得控制权。(3)操作系统启用LBR,然后执行影子代码。(4) BPU正确地预测了阴影无条件分支的目标,因为目标无条件分支从未执行过。(5)影子代码执行一个额外的分支来测量经过的周期。(6)通过禁用和检索LBR,我们了解到由于经过的周期数量较少,没有发生分支目标预测错误。
无条件分支没有预测错误。我们发现,LBR总是报告每一个执行的无条件分支都已被预测,而不管它是否预测错误了目标(未记录的行为)。我们认为这是因为无条件分支的目标是固定的,因此通常不应该发生目标预测错误。此外,LBR用于促进分支分析,以减少优化预测失误。然而,程序员没有办法处理由于内核或另一个进程的执行而导致的预测错误的无条件分支——也就是说,这无助于程序员改进他们的程序,只是揭示了侧通道信息。我们相信这就是LBR将每个无条件分支视为正确预测的原因。
间接分支阴影
我们解释了如何通过遮蔽分支历史来推断飞地内的目标间接分支是否已被执行。与无条件分支一样,执行间接分支时总是采用间接分支。但是,与无条件分支不同,间接分支没有固定的分支目标。如果没有历史记录,则BPU预测将执行间接分支指令之后的指令;这与未采取的间接分支相同。为了识别它的行为,我们使一个带阴影的间接分支跳转到紧随其后的指令,以监视由于历史而导致的分支目标预测错误。LBR报告间接分支的预测错误,这样我们就不需要依赖于经过的周期来攻击间接分支。
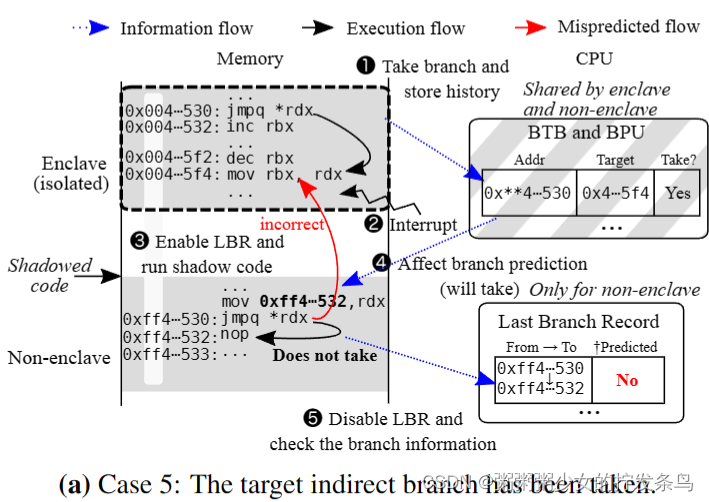
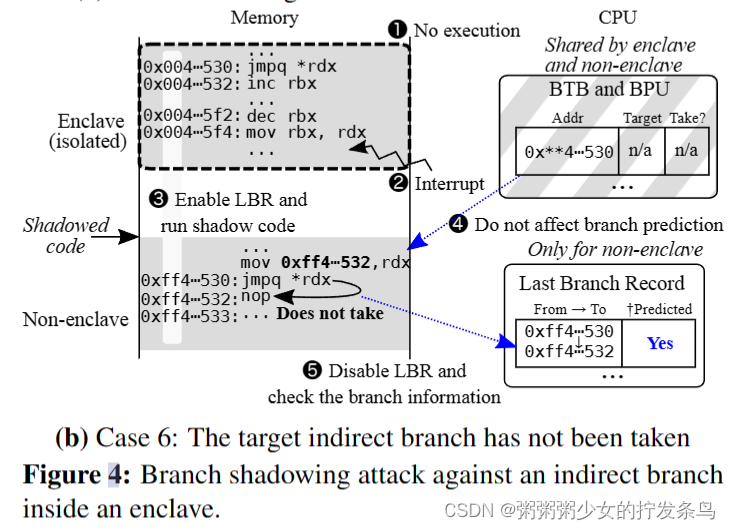
攻击程序。图4显示了间接分支阴影的过程。我们使带阴影的间接分支跳转到其下一条指令,以观察分支历史是否会导致分支预测错误。我们首先解释一个间接分支被执行的案例(案例5)。(1)执行受害者代码的间接分支,并将相应的信息存储到BTB和BPU中。(2) Enclave执行被中断,操作系统获得控制权。(3)操作系统启用LBR,然后执行影子代码。(4) BPU错误地预测阴影间接分支将被带到不正确的目标地址,因此执行被回滚为不带分支。(5)最后,通过禁用和检索LBR,我们了解到阴影代码的间接分支被错误地预测了——与分支预测不同,它并没有被执行。
接下来,我们解释没有采取间接分支的情况(情况6)。(1)飞地不执行受害者代码的间接分支,因此BTB没有关于该分支的信息。(2)Enclave执行被中断,操作系统获得控制权。(3)操作系统启用LBR,然后执行影子代码。(4)BPU正确地预测,由于没有分支历史,阴影间接分支将不会被采用。(5)最后,通过禁用和检索LBR,我们了解到影子代码的间接分支已经被正确预测——它没有像预测的那样被采用。
推断分支目标。与条件分支和无条件分支不同,间接分支可以有多个目标,因此仅知道它是否已被执行不足以知道受害者代码的执行情况。由于间接分支主要用于表示switch case语句,因此它也与许多无条件分支(即break)有关,就像anif-else语句一样。这意味着攻击者可以通过探测相应的无条件分支来识别执行了哪个case块。此外,如果攻击者可以用相同的输入重复执行受害者飞地程序,他或她可以测试相同的间接同时改变候选目标地址以通过观察正确的分支目标预测来最终知道真实目标地址。
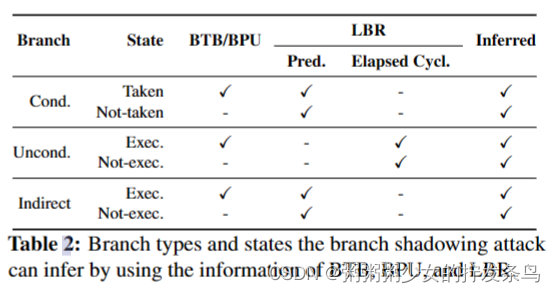
表2总结了我们的攻击可以推断的分支类型和状态以及必要的信息。
频繁中断和探测
分支跟踪攻击需要考虑更改(甚至删除)BTB条目的情况,因为它们会使攻击错过一些分支历史记录。首先,BTB的大小受到限制,使得BTB条目可以被另一个分支指令覆盖。我们根据经验确定,Skylake的BTB有4096个条目,其中方式的数量为4,集合的数量为1024(§5.1)。由于其精心设计的索引哈希算法,我们观察到位于不同地址的两个分支指令之间很少发生冲突。但是,不管怎样,在执行了4096条不同的分支指令后,BTB都会溢出,我们将丢失一些分支历史记录。其次,条件分支或间接分支的BTB条目可以因为循环或重新执行相同的函数而被删除或更改。
例如,一个条件分支在第一次运行时被执行,而在第二次运行时由于给定条件的更改而没有执行,从而删除了相应的BTB条目。间接分支的目标也可以根据条件进行更改,从而更改相应的BTB条目。如果分支阴影攻击在BTB条目更改之前无法检查该条目,则会丢失信息。
为了解决这个问题,我们尽可能频繁地中断飞地进程,并通过操作本地APIC计时器和CPU缓存来检查分支历史。这两种方法大大降低了目标飞地程序的执行速度,因此攻击者需要仔细使用它们(即选择性地)以避免被检测到。
操作本地APIC计时器。我们在最新版本的Linux中操作本地APIC定时器的频率(详细信息见附录a。)我们根据两个定时器中断之间可以执行的ADD指令数量来测量被操作的定时器中断的频率。平均而言,在两次定时器中断之间执行了约48.76条ADD指令(标准偏差:2.75)1。ADD在Skylake CPU[25]中只需要一个周期,因此我们的频繁计时器可以每约50个周期中断一个受害者包围区。
正在禁用缓存。如果我们必须在小于50个周期的短循环中攻击分支指令,那么频繁的定时器中断是不够的。为了更频繁地中断包围区进程,我们通过设置CR0控制寄存器的缓存禁用(CD)位,选择性地禁用运行受害包围区进程的CPU核心的L1和L2缓存。在频繁的定时器中断和禁用缓存的情况下,平均在两个定时器中断之间执行约4.71条ADD指令(标准偏差:1.96,迭代次数为10000次)。因此,我们可以达到的最高攻击频率大约是五个周期。
虚拟地址操纵
要执行分支阴影攻击,攻击者必须操纵受害者包围区进程的虚拟地址。由于攻击者已经破坏了操作系统,因此操纵页面表以更改虚拟地址是一项简单的任务。为了简单起见,我们假设攻击者禁用用户空间ASLR,并修改适用于Linux的Intel SGX驱动程序(vm_mmap)以更改飞地的基地址(附录B)。此外,攻击者在影子代码之前放入任意数量的NOP指令,以满足对齐要求。
攻击同步
尽管分支阴影在每次迭代中探测多个分支,但当受害者包围区程序很大时,这是不够的。克服这一限制的方法是在功能级别应用分支阴影攻击。也就是说,攻击者首先推断受害者包围区程序已经执行或当前正在执行的功能,然后探测属于这些功能的分支。如果这些函数包含可以从外部(通过EENTER)调用或依赖外部调用的入口点,则攻击者可以很容易地识别它们,因为操作系统可以控制和观察它们。
但是,攻击者需要另一种策略来推断未导出函数的执行情况。攻击者可以创建由目标函数的始终可到达分支(例如,位于函数序言处的分支)组成的特殊影子代码。通过定期执行此代码,攻击者可以查看哪些被监视的函数已被执行。此外,攻击者可以使用页面故障侧通道[60]来同步页面方面的攻击。
受害者隔离
为了最大限度地减少噪声,我们需要确保只有受害者飞地程序和影子代码将在隔离的物理核心中执行。每个物理核心都有由多个进程共享的BTB和BPU。因此,如果进程在核心运行的分支阴影攻击下,其执行会影响整体攻击结果。为了避免这个问题,我们使用isolcpus引导参数来指定一个孤立的核心,如果没有特定的请求,该核心将不会被调度。然后,我们使用taskset命令运行一个带有隔离核心的受害者飞地。
评估
在本节中,我们演示了针对RSA实现的分支阴影攻击,并描述了我们对各种库和应用程序的案例研究,这些库和应用软件容易受到我们的攻击,但大多可以安全地抵御受控通道攻击[60]。分支阴影攻击的目标不是克服针对分支预测侧信道攻击的对策,例如,隐藏指数值的指数盲法,而不是分支执行[34]。因此,我们不试图攻击没有分支预测侧信道的应用程序。
攻击RSA指数
我们对一个流行的TLS库mbed TLS(也称为PolarSSL)发起分支阴影攻击。mbed TLS由于其轻量级实现和可移植性,是SGX开发人员和研究人员的热门选择[47,49,62,63]。

图5显示了mbed TLS如何实现RSA操作所使用的滑动窗口求幂。此函数有两个标记为⋆的条件分支(jne),其执行取决于指数的每个位(ei)。只有当ei不在时,才会使用这些分支零(即一)。因此,通过跟踪它们并检查它们的状态,我们可以知道ei的值。请注意,无论滑动窗口有多大,这两个分支都会被执行。在我们的系统中,每个循环执行(第7-30行)大约需要800个周期,因此一个被操纵的本地APIC计时器就足以中断它。此外,为了区分每个循环执行,我们对跳回循环开始的无条件分支进行阴影处理。
我们通过使用mbed TLS提供的用于测试的默认密钥对攻击RSA-1024解密来评估分支阴影的准确性。默认情况下,mbed-TLS的RSA实现使用中国剩余定理(CRT)技术来加快计算速度。因此,我们观察到mbedtls_mpi_exp_mo的两次执行,每次迭代中有两个不同的512位CRT指数。滑动窗口的尺寸是五个。
平均而言,分支阴影攻击从受害者的单次运行中恢复了两个CRT指数中每一个的大约66%的比特(平均超过1000次执行)。剩余比特(34%)对应于循环迭代,其中两个阴影分支返回不同的结果(即预测与预测错误)。我们丢弃了这些测量值,因为它们受到平台噪声的影响,并将相应的比特标记为未知。其余66%的比特被正确推断,准确率为99.8%,其中标准偏差为0.003。
导致攻击错过大约34%的密钥位的事件似乎是随机发生的。不同的运行显示不同的关键位子集。在受害者最多跑10次之后,攻击几乎恢复了整个密钥。与现有的缓存定时攻击相比,这种运行次数较少,现有的缓存计时攻击需要数百到数万次运行才能可靠地恢复密钥[20,35,65]。
基于时间的分支阴影。我们没有使用LBR,而是测量了使用RDTSCP执行影子分支所需的时间,同时维护其他技术,包括修改的本地APIC计时器和受害者隔离。当选取两个目标分支时,阴影分支平均花费55.51个周期,其中标准偏差为48.21个周期(1000次迭代)。当不取两个目标分支时,阴影分支平均取93.89个循环,其中标准偏差为188.49个循环。由于方差高,找到一个好的决策边界很有挑战性,因此我们使用LIBSVM(具有RBF核和默认参数)构建了一个支持向量机分类器。它的准确度为0.947(10倍交叉验证)——也就是说,我们需要比基于LBR的攻击多运行至少两倍的攻击,才能达到相同的准确度。
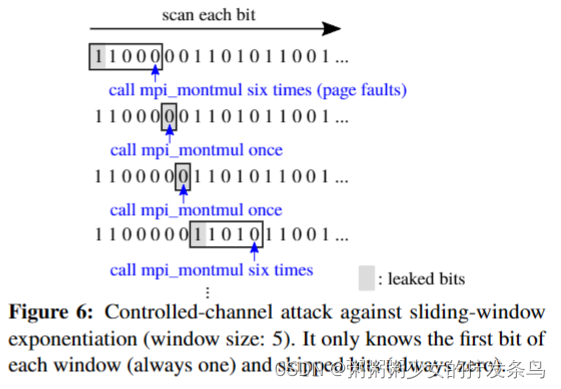
受控通道攻击。我们还根据图5评估了受控通道攻击。我们发现mbedtls_mpi_exp_mod有条件地调用mpi_montmul(标记为+),并且两个函数都位于不同的代码页上。因此,通过小心地取消映射这些页面,攻击者可以监视何时调用mpi_montmul。然而,如图6所示,由于滑动窗口技术,受控信道攻击无法识别每个比特,除非它知道SW[wbits]——即,该攻击只能知道每个窗口的第一个比特(总是一个)和跳过的比特(总是零)。可识别比特的数量完全取决于指数的比特的分布方式。针对mbed TLS的默认RSA-1024私钥,该攻击识别了334位(32.6%)。因此,我们得出结论,分支阴影攻击在获取细粒度信息方面优于受控通道攻击。
个案研究
我们还研究了分支阴影可能攻击的其他敏感应用程序。具体来说,我们关注的是受控通道攻击无法提取任何信息的示例,例如,单个页面内的控制流。我们又攻击了三个应用程序:1)Linux SGX SDK中的两个libc函数(strtol和vfprintf),2)移植到Intel SGX的LibSVM,以及3)移植到英特尔SGX的一些Apache模块。我们获得了有趣的结果,例如输入数字的长度(strtol)、输入格式字符串的样子(vfprintf)以及Apache服务器获得的HTTP请求类型(lookup_builtin_method),如表3所示。注意,受控信道攻击不能获得相同的信息,因为这些函数至少在目标基本块中不调用外部函数。源代码的详细分析见附录C。
防御
我们介绍了针对分支阴影攻击的基于硬件和基于软件的对策。
Flushing Branch State
针对分支阴影攻击的一个基本对策是通过修改硬件或更新微码来清除包围区内生成的所有分支状态。每当发生包围区上下文切换(通过EENTER、EEXIT或ERESUME指令或AEX)时,处理器都需要刷新BTB和BPU状态。由于BTB和BPU受益于局部和全局分支执行历史记录,如果这些状态刷新得太频繁,将导致性能损失。

我们使用循环级无序微体系结构模拟器MacSim[30]来估计我们的对策在不同飞地上下文切换频率下的性能开销。为了模拟每个飞地上下文切换的分支历史刷新,我们修改了MacSim,使其每1亿到1000万个周期刷新BTB和BPU;这类似于每1亿到1000万个周期的包围区上下文切换。表4列出了我们的模拟参数的详细信息。BTB是以英特尔Skylake处理器中的BTB为模型的。我们使用了类似于[158]中的方法来对BTB参数进行逆向工程。从我们的实验中,我们发现BTB被组织为一个4向集合关联结构,共有4096个条目。我们为模拟建立了一个简单的分支预测器gshare[37]。我们使用这些指令距离SPEC06基准套件有2亿条指令长,用于模拟痕迹。
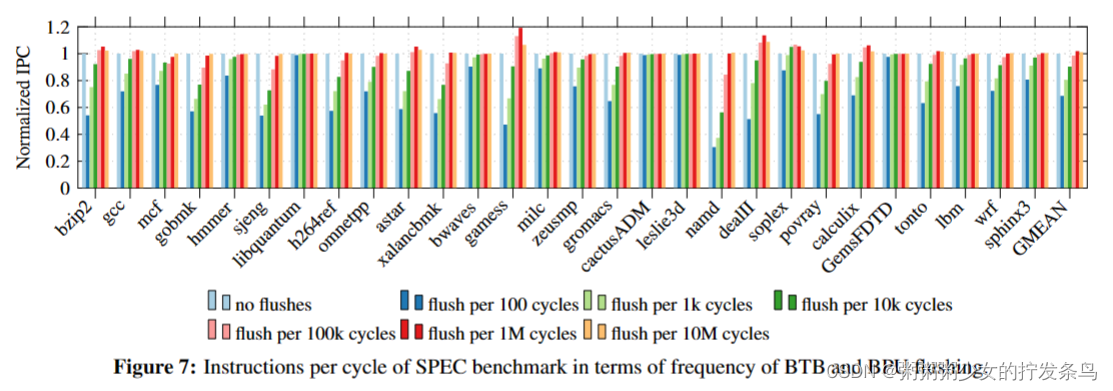
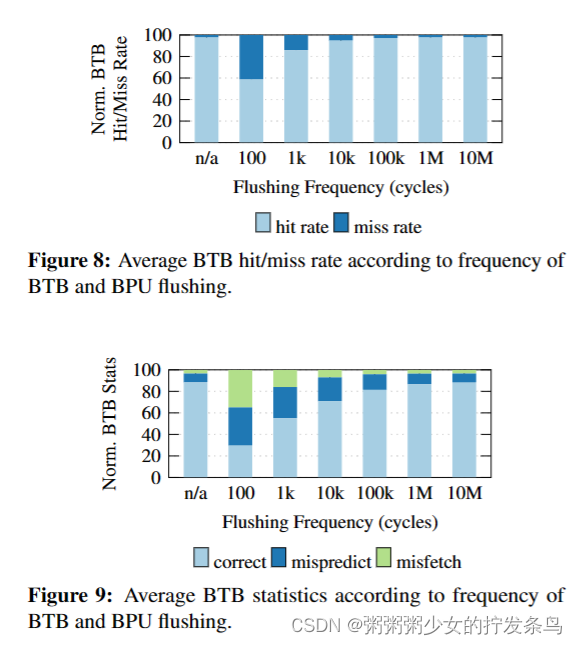
图7显示了不同冲洗频率的每个周期(IPC)的规范化指令。我们发现,如果刷新频率高于100k周期,则其性能开销可以忽略不计。在100k次循环的冲洗频率下,性能退化低于2%,在100万次循环时,性能退化可以忽略不计。图8显示了BTB命中率,而图9显示了BPU正确、不正确(方向预测错误)和不正确(目标预测错误)的百分比。BTB和BPU的统计数据在100k周期的刷新频率之外也几乎无法区分。
混淆分支
分支状态刷新可以有效地防止分支阴影攻击,但我们不能确定何时以及是否会实现这种硬件更改。特别是,如果微代码更新无法完成此类更改,我们就无法保护市场上已经部署的英特尔CPU。
针对分支阴影攻击的可能基于软件的对策是移除分支[39]或使用最先进的ORAM技术Raccoon[44]。数据遗忘机器学习算法等[39]通过使用条件移动指令CMOV消除所有分支。然而,他们的方法是特定于算法的,即不适用于一般应用。Raccoon[44]总是执行条件分支的两条路径,这样就不会泄露任何分支历史。但是,它的性能开销很高(21.8倍)。
Zigzaggar。我们提出了一种实用的、基于编译器的分支阴影缓解方法,称为Zigzagger。它将一组分支指令混淆为单个间接分支,因为推断间接分支的状态比推断条件和无条件分支的状态更困难(§3.5)。然而,在不依赖条件跳转的情况下计算每个分支的目标块并不简单,因为条件表达式可能会因为嵌套的分支而变得复杂。在Zigzagger中,我们通过使用CMOV指令[39,44]并引入一系列非条件跳转指令来代替每个分支来解决这个问题。
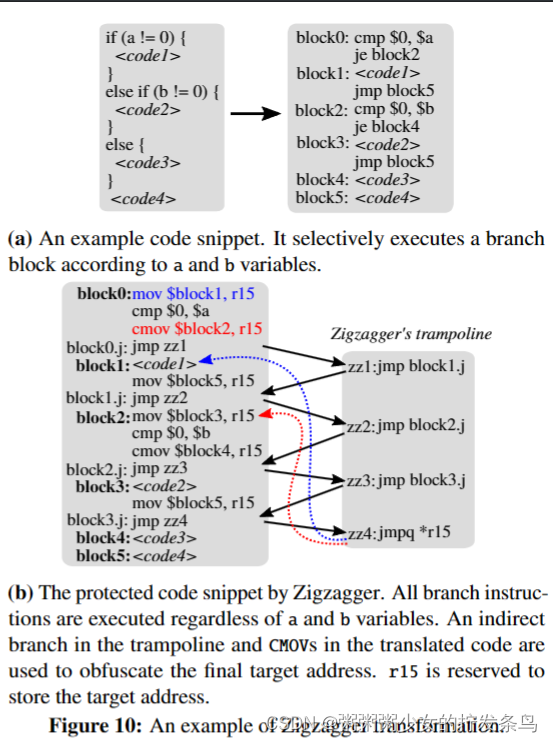
图10显示了Zigzagger如何转换具有if、else-if和else块的示例代码片段。它将所有有条件和无条件分支转换为无条件分支,目标是Zigzagger的trampoline,trampoline用转换后的分支来回跳跃。蹦床最终跳到存储在保留寄存器r15中的真实目标地址中。请注意,保留寄存器只是为了提高性能。当应用程序需要使用大量寄存器时,我们可以使用内存来存储目标地址。为了模拟条件执行,图10b中的CMOV指令仅在a或b为零时更新r15中的目标地址。否则,它们将被视为NOP指令。由于所有无条件分支几乎同时按顺序执行,因此很难识别当前指令指针。此外,由于trampoline现在有五个不同的目标地址,因此推断其中的真实目标并不简单。
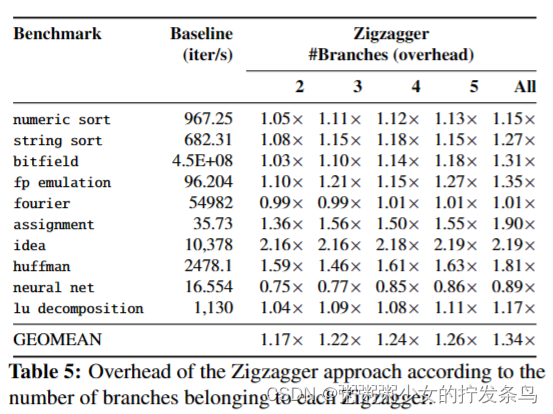
Zigzagger的方法有几个好处:1)安全性:它为飞地程序中的每个分支块提供了第一道保护线;2) 性能:其开销最多为2.19×(表5);3) 实用性:它的转换既不需要复杂的代码语义分析,也不需要大量的代码更改。然而,它并不能确保完美的安全性,因此我们仍然需要类似ORAM的技术来保护非常敏感的功能。
实施我们在LLVM 4.0中实现了Zigzagger,作为LLVM通行证,它转换每个函数中的分支并构建所需的trampoline。我们还修改LLVM后端保留一个寄存器。单个trampoline管理的分支数量会影响整体性能,因此我们的实现提供了一个旋钮来配置它,以换取安全性和性能。
我们的Zigzagger概念验证实现,合并了每个函数中的每个分支,在使用nbenchbenchmark套件进行评估时,增加了1.34倍的性能开销(表5)。通过优化(即,将≤3个分支合并为一个trampoline),平均开销变为≤1.22×。请注意,保留寄存器会使性能提高4%-50%。
讨论
在本节中,我们将解释分支阴影攻击的一些局限性,并讨论可能的高级攻击。
局限性
分支跟踪攻击有局限性。首先,它不能区分未执行的条件分支和未执行的有条件分支,因为在这两种情况下,BTB都不存储信息;应用静态分支预测规则。其次,它无法区分下一条指令的间接分支和未执行的间接分支,因为它们的预测分支目标相同。因此,攻击者必须探测多个相关分支(例如,无条件分支不包含if或case块)来克服这些限制。第三,与受控信道攻击一样,分支阴影攻击需要重复以提高攻击精度,这可以通过状态连续性解决方案来禁止[55]。然而,这需要持久性存储,例如由可信平台模块(TPM)提供的存储。
高级攻击
我们考虑如何改进分支阴影:超线程和盲方法。
超线程分支阴影。由于同时在同一物理核心中运行的两个超线程共享BTB和BPU,因此恶意超线程可能如果恶意操作系统将受害者的地址信息提供给受害者,则使用BTB条目冲突攻击受害者飞地超线程。我们观察到,具有相同低16位地址的分支指令被映射到相同的BTB集。因此,恶意超线程可以通过用四条分支指令填充BTB集来监视BTB集是否被驱逐(§5.1)。BTB刷新无法阻止此攻击,因为它不需要飞地模式切换,因此禁用超线程或阻止超线程共享BTB和BPU是必要的。
盲分支阴影。盲分支阴影攻击是指试图探测受害者包围区进程的整个或选定的内存区域,以检测任何未知的分支指令。如果受害者飞地进程具有自修改代码或使用远程代码加载,则此攻击是必要的,尽管这超出了我们的威胁模型(§3.1)的范围。在无条件分支的情况下,盲探测是简单有效的,因为它不需要推断目标地址。然而,在条件分支和间接分支的情况下,盲探测需要同时考虑分支指令及其目标,这样搜索空间将是巨大的。我们计划考虑一种有效的方法来最小化搜索空间,以了解这种攻击是否实用。
相关工作
英特尔SGX。SGX提供的强大安全保障引起了研究界的极大关注。提出了SGX的几种安全应用,包括安全和分布式数据分析[7,11,39,46,66]和安全网络服务[31,41,48]。此外,研究人员实现了SGX层[5,6,51,57],以在不进行任何修改的情况下在飞地内运行现有应用程序。SGX本身的安全特性也在深入研究中。例如,Sinha等人[52,53]开发了验证飞地程序机密性的工具。
然而,研究人员发现了针对英特尔SGX的安全攻击。Xu等人[60]和Shinde等人[50]通过利用SGX依赖操作系统进行内存资源管理的事实,展示了对SGX的第一次侧信道攻击。该攻击是通过故意操纵页面表来触发页面错误,并使用页面错误序列来推断飞地内的秘密来完成的。Weichbrodt等人[59]还展示了如何利用同步错误攻击SGX应用程序。此外,在我们工作的同时,Haëhnel等人[21]利用Windows中的频繁定时器,实现了针对Intel SGX模拟器的精确缓存侧通道攻击。
为了解决基于页面故障的侧通道攻击,Shinde等人[50]混淆了飞地的内存访问模式。Shih等人[49]提出了一种基于编译器的解决方案,使用Intel TSX来检测飞地内的可疑页面故障。此外,Costan等人[10]提出了一种新的飞地设计,以防止页面故障和缓存定时侧信道攻击。最后,Seo等人[47]在飞地程序上强制执行细粒度ASLR,这可以提高利用任何漏洞和用页面故障序列推断控制流的门槛。然而,所有这些解决方案都大量使用分支指令,并且不清除分支状态,因此它们很容易受到我们的攻击。
微体系侧信道。研究人员考虑了微结构侧通道的安全问题。最受欢迎和研究最深入的微体系结构侧通道是由[29,34,40]首次开发的CPU缓存定时通道,用于破解密码系统。该攻击进一步扩展到在公共云环境中进行,以识别虚拟机的共同驻留[45,64]。几位研究人员进一步改进了这种攻击,利用了最后一级缓存[27,35],并创建了一个低噪声缓存存储通道[19]。CPU缓存并不是微体系结构侧通道的唯一来源。例如,为了破坏内核ASLR,研究人员利用TLB定时通道[23]、Intel TSX指令[28]、PREFETCH指令[18]和BTB定时通道[13]。Ge等人[14]对微结构侧通道进行了全面调查。
总结
基于硬件的TEE(如Intel SGX)需要进行彻底的分析,以确保其在恶劣环境下的安全性。在本文中,我们提出并评估了分支阴影攻击,该攻击识别SGX包围区内的细粒度执行流。我们还提出了基于硬件的对策,在飞地模式切换期间清除分支历史,以及基于软件的缓解措施,使分支执行变得不经意。
这篇关于Inferring fine-grained control flow inside SGX enclaves with branch shadowing【分支预测】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






