本文主要是介绍Image Fine-grained Inpainting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Motivation
- 传统方法不能生成新的内容;
- 现有的基于深度学习的方法会产生不合理的结构和模糊。
2. Approach
2.1 Network Architecture


生成器:每个“convolution + norm”都有一个激活函数,最后一层的激活函数是Tanh,其他层的函数都是ReLU。生成器的中间部分包含DMFB(dense multi-scale fusion block),结构如上图所示。
判别器:两个branch,一个负责全局特征,一个负责局部特征,之后将feature concat,整体判别真假。
2.2 Loss function
- Self-guided regression loss:

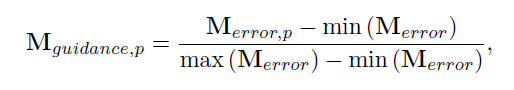
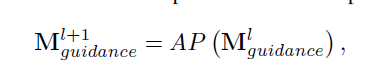
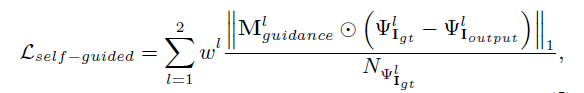
mask让缺失区域的值为1,会将缺失区域或包含缺失区域的像素或特征mask的值变大,而未缺失区域的mask值较小,对缺失区域的惩罚力度更大,这一点也很好理解,模型只需要填充缺失区域,已知区域可以复制,所以我们希望对缺失区域要求更高,而一直区域要求较低,这边只使用了前两层的feature,对应的是底层的特征。
- Geometrical alignment constraint:


几何对齐损失,对于feature maps,他有多个通道,这篇文章设想每个通道有一个中心,对于生成的图像和真实图像而言,这个几何中心要尽可能的接近。
- Adversarial loss:
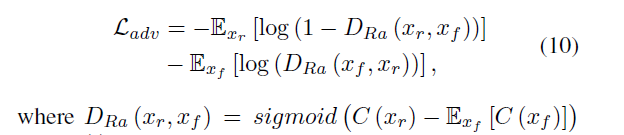
ESRGAN【1】的相对平均判别器,C这个函数表示最后一层,激活函数sigmod前的网络。
- Final objective:
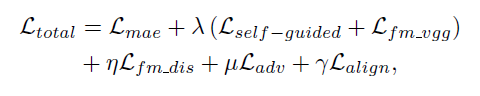
3. Discussion
我认为这篇文章创新点有以下几个:
- Dense multi-scale fusion block的设计,更好的提取特征;
- Self-guided regression loss的设计,加大了对缺失区域的惩罚力度;
- Geometrical alignment constraint,要求feature maps的中心对齐。
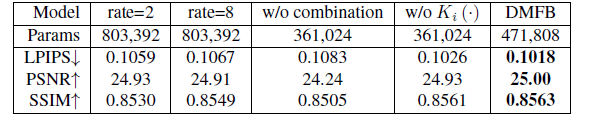
这篇文章并不是像partial convolution那样一个很强的创新点,而是多个小的创新点组合。从作者给出的结果,这些小的创新点对模型的精度都有贡献。

源代码作者现在还没放出来,不过作者说之后会放出来:https://github.com/Zheng222/DMFN
4. References
【1】Wang, Xintao, et al. "Esrgan: Enhanced super-resolution generative adversarial networks." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
【2】Hui, Zheng, et al. "Image fine-grained inpainting." arXiv preprint arXiv:2002.02609 (2020).
这篇关于Image Fine-grained Inpainting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









