本文主要是介绍VQA 之 Multimodal Compact Bilinear Pooling,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
涉及论文
[1]Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
https://www.arxiv.org/pdf/1606.01847.pdf
[2]Compact Bilinear Pooling
https://arxiv.org/pdf/1511.06062.pdf
[3]Bilinear CNN Models for Fine-grained Visual Recognition
https://arxiv.org/pdf/1504.07889.pdf
1 introduction
这里主要涉及三篇文章,首先是做fine-grained的bilinear cnn models[3],但是bilinear cnn会引起参数维度过大,于是作者提出了compact bilinear pooling[2],然后在此基础上做VQA任务[1],并取得了2016年的冠军 http://visualqa.org/roe.html
VQA =Visual Question Answering, 主要任务是给定一幅图片,并提出几个问题,模型负责回答该问题
2 Multimodal Compact Bilinear Pooling for Visual Question Answering
做VQA的基本方法如下:

简单来说,就是CNN来的图像特征与RNN来的自然语音特征,进过融合之后,将特征放入分类器或者RNN用来生成问题的答案。
改进以上结构的方法有许多,如下图:

可以选择改进CNN或者RNN,也可以选择 改变两种特征的融合方式,或者加入attention,
本文就属于改变两种特征融合方式的一种。

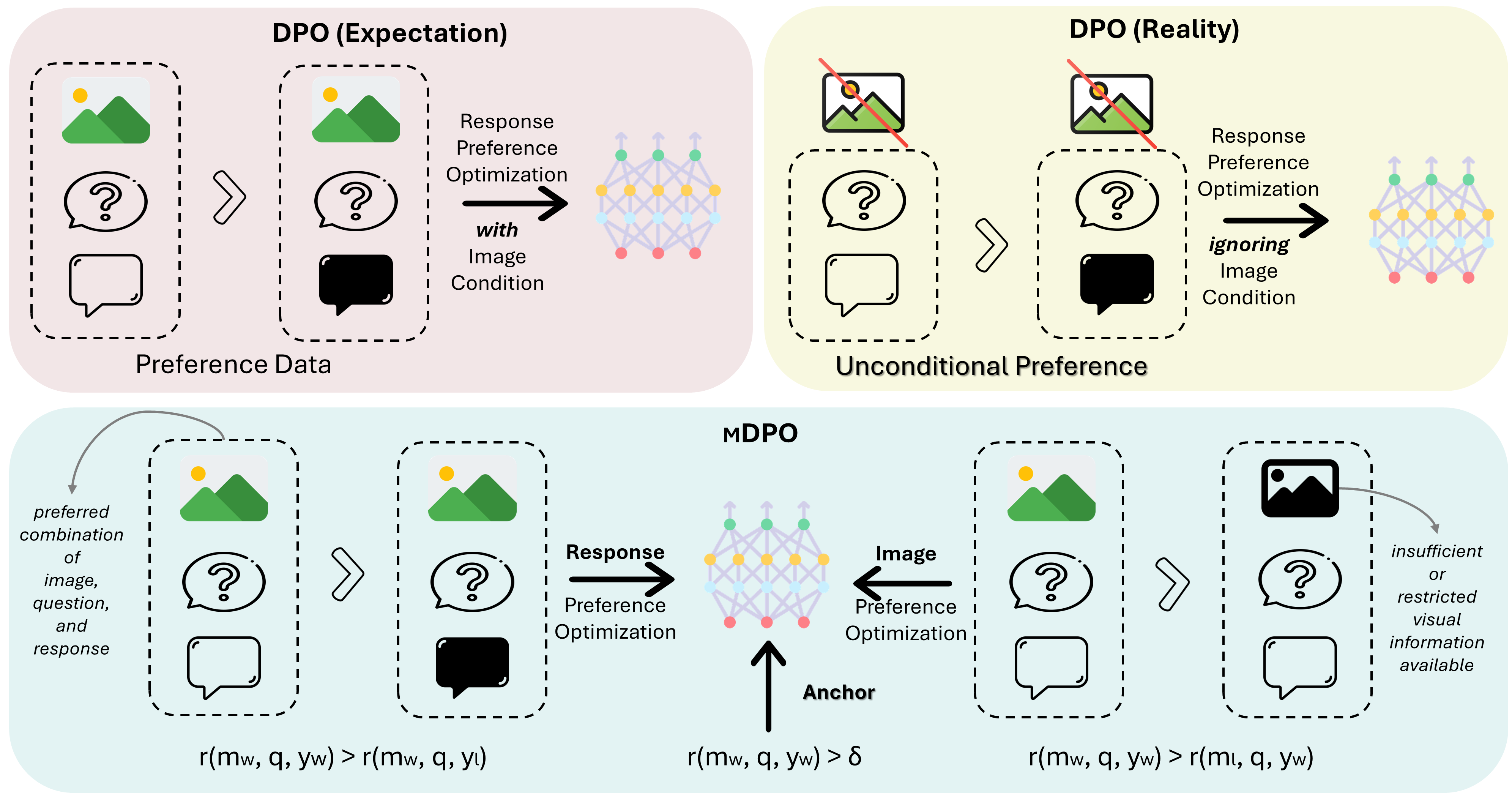
如上图,本文采取的方法是所谓的MCB,简单来说就是一种可以简化的bilinear pooling,
所以下面先从bilinear pooling 说起
3 Bilinear CNN Models
两种特征连接或者说融合在一起的方法有许多种,比如相加,concatenate,等等,后来提出的bilinear cnn 是利用了两个特征的外积来融合,效果很不错,如下:


下面我们具体来说下如何操作:

对于图片I,会生成两个 feature map, fa,fb, 假设在fa和fb都为h \times w \times D维,在某一个位置l上会有D维特征, 双线性层就是将这两个D维数据按如上公式进行运算,即求outer product。 然后会被拉直为DxD维向量,
outer product的定义:

blinear pooling就是在每个位置如上计算,随后求sum,

有一些解释为由于bilinear 考虑了两个特征间每个元素的interaction,所以效果会更好
说道这里我们可以讨论一下,为什么bilinear pooling 可以提高效果
4 Multimodel compact bilinear pooling
从上面可以看出经过bilinear之后,维度变为原来的平方倍,后面的层会增加很多参数,为了使该过程更高效,这里加了降维的措施
具体的处理手段是使用count sketch的方法降维求外积:

其中的星号*,代表卷积操作,

[Pham and Pagh2013] Ninh Pham and Rasmus Pagh. 2013. Fast and scalable polynomial kernels via explicit feature maps. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’13, pages 239–247, New York, NY, USA. ACM.
计算过程 
之后可能会专门写一篇关于类似的计算,这里就偷下懒了⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄

加入attention之后的框架,

这篇关于VQA 之 Multimodal Compact Bilinear Pooling的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)