vqa专题

视觉问答VQA知识资料全集
视觉问答(Visual Question Answering,VQA)专知荟萃 入门学习进阶论文 Attention-BasedKnowledge-basedMemory NetworkVideo QA综述TutorialDatasetCode领域专家 入门学习 基于深度学习的VQA(视觉问答)技术 [https://zhuanlan.zhihu.com/p/22530291]视觉问答全景概
YOLOV8注意力改进方法: CoTAttention(Visual Question Answering,VQA)附改进代码)
原论文地址:原论文下载地址 论文相关内容介绍: 论文摘要翻译: 具有自关注的Transformer导致了自然语言处理领域的革命,并且最近在许多计算机视觉任务中激发了具有竞争性结果的Transformer风格架构设计的出现。然而,大多数现有设计直接使用二维特征图上的自关注来获得基于每个空间位置上的孤立查询和键对的关注矩阵,而没有充分利用相邻键之间的丰富上下文。在这项工作中,我们设计了一个新颖的
视觉问答06day[综述]:一文带你了解视觉问答VQA
A Brief Introduction for Visual Question Answer Visual Question Answer (VQA) 是对视觉图像的自然语言问答,作为视觉理解 (Visual Understanding) 的一个研究方向,连接着视觉和语言,模型需要在理解图像的基础上,根据具体的问题然后做出回答。本文将简短的对VQA做一个调研,涉及一小部分论文,作为入门。

VQA-ReGat 项目运行遇到的错误
VQA-ReGat:关系感知图形注意网络用于VQA 项目地址 论文地址 1.torch报错:StopIteration: Caught StopIteration in replica 0 on device 0. 原因:多GPU运行此项目报错,可能是torch版本错误。 修改:按照别的博客将 weight = next(self.parameters()).data改为weight = t
论文解读之VQA视觉问答
VQA:Visual Question Answering 声明:借助翻译软件翻译 可能存在翻译错误,或者理解错误,希望批评指正一起学习。 Abstract 摘要 本文提出了以自由形式和开放式的视觉问答任务。给定图像和关于图像的自然语言问题,这个任务会给出一个精确的自然语言答案。视觉问题是有选择性的在图片不同区域包括背景细节或者基础上下文。与产生通用图片标题的系统相比,VQA上成功的系
VQA-object_counting代码项目分析
0. 写在前面 本文主要介绍《LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING》的代码项目,也就是别人的代码加上自己的注释。。。 博客地址:https://blog.csdn.net/snow_maple521/article/details/109190431 论文地址:https://gith

VQA论文2021CVPR
2021CVPR VQA2021论文主要分成几个方面: 1)语言先验,泛化能力:CFVQA;GQA-OOD;How transfer 2)鲁棒性评估:Perception Matters; 3)新设定: 4)其他:TextVQA,OKVQA 5)数据集:多是Video QA 6)预训练: Perception Matters: Detecting Perception Failures of V
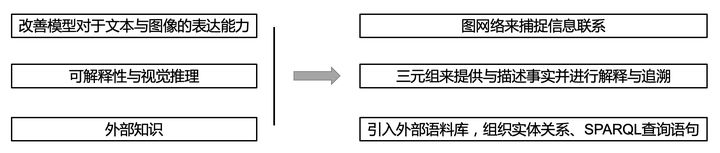
【论文小综】基于外部知识的VQA(视觉问答)
我们生活在一个多模态的世界中。视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知。作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题。从15年首次被提出[1]至今,其涉及的方法从最开始的联合编码,到双线性融合,注意力机制,组合模型,场景图,再到引入外部知识,进行知识推理,以及使用图网络,多模态预训练语言模型…近年来发展迅速。 传统的

VQA 之 Multimodal Compact Bilinear Pooling
涉及论文 [1]Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding https://www.arxiv.org/pdf/1606.01847.pdf [2]Compact Bilinear Pooling https://arxiv.org/pdf/1511.06062.pd
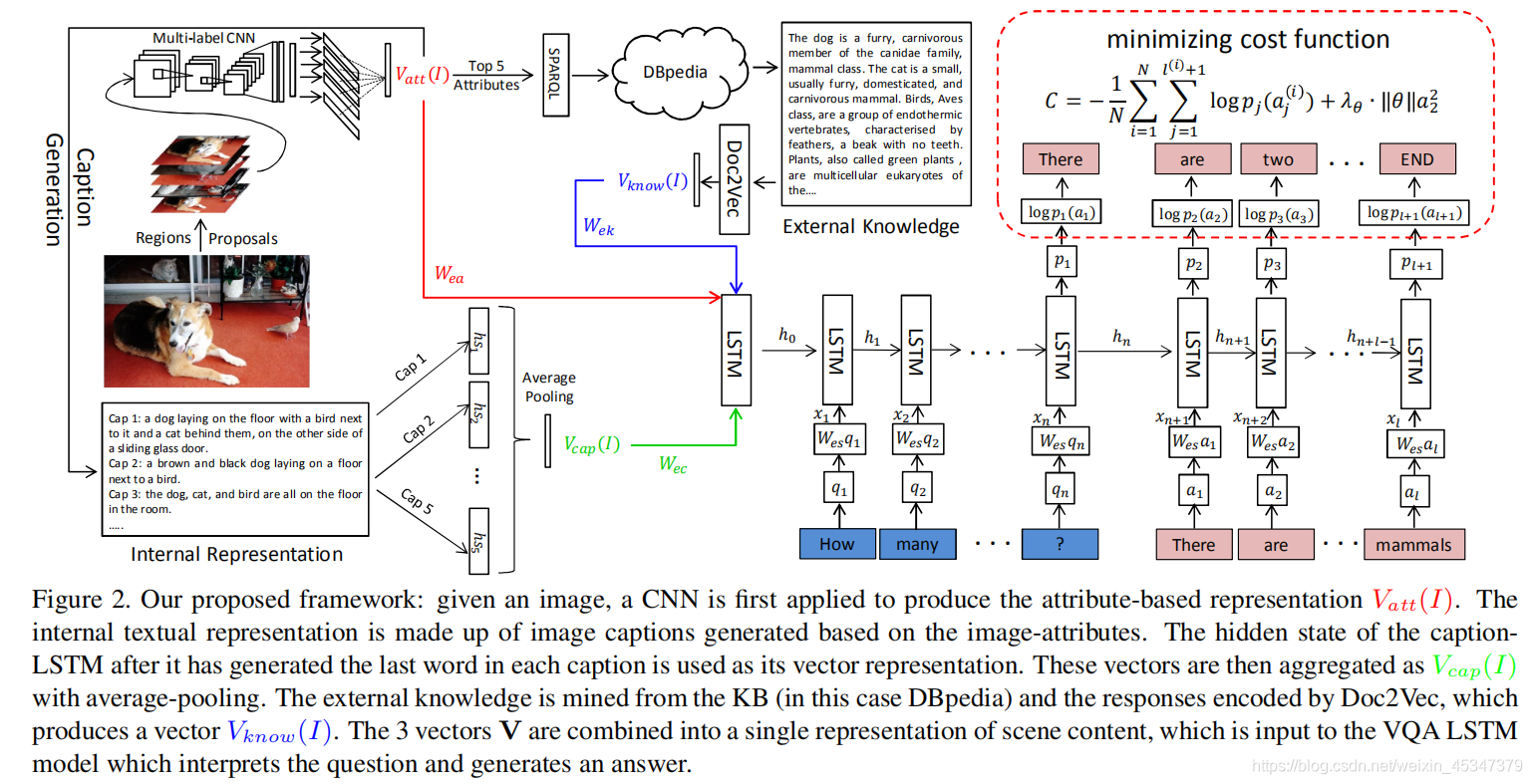
知识推理的VQA小结
知识推理的VQA小结 论文1. Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources 参考链接 内容: 总体上看大致分为这样几个步骤: 1,先从图像中提取前五的属性. 2,提取的属性分为三部分:一方面用来直接生成关于图像的描述,另一方面用来从知识库中提取相关

【VQA文献阅读】(CVPR2019)Answer Them All! Toward Universal Visual Question Answering Models ——直观了解最新VQA数据集
【VQA文献阅读】(CVPR2019)Answer Them All! Toward Universal Visual Question Answering Models ——直观了解最新VQA数据集 前言:有些文献虽然不是综述,但其中多多少少都有介绍数据集的情况,对目前公开的VQA数据集有了详细的介绍,可以起到类似综述的效果,让读者能更好的对现有数据集有更加直观的认识,其功用类似综述,该文章

【文献阅读】VQA入门——Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
本人在读研一,想要学习多模态这一块的工作。我在这里记录下我看的第一篇论文《Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge》的看后总结。若有不当之处,请斧正! 论文地址:https://arxiv.org/abs/1708.02711 在介绍论文之前,先给大家讲一下什么叫做VQA VQ