本文主要是介绍知识推理的VQA小结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
知识推理的VQA小结
论文1. Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
参考链接
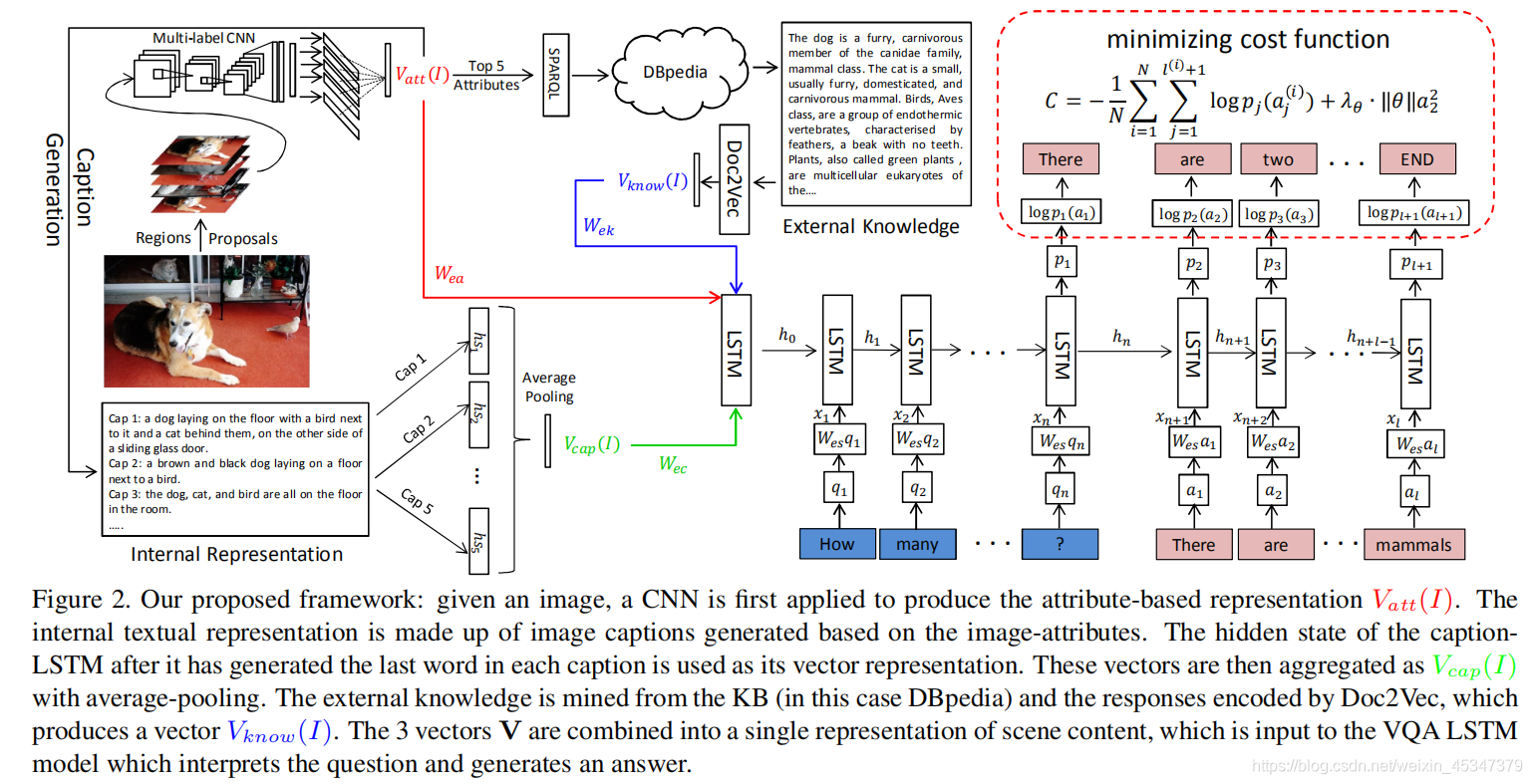
内容:
总体上看大致分为这样几个步骤:
1,先从图像中提取前五的属性.
2,提取的属性分为三部分:一方面用来直接生成关于图像的描述,另一方面用来从知识库中提取相关外部知识,当然,自身也会被重新用到。
3,将第二步中的图像的三个结果作为一个视觉信息的整体输入到LSTM的编码结构中,问题的每个单词也作为输入输入到LSTM的编码结构中。然后在LSTM的解码结构中,生成每个答案单词的分布概率。
4,最终得到一个多个单词标签的答案。
缺点:
这篇文章缺点在于仅仅从数据集中提取离散的文本描述,忽略了结构化的表达,也就是说,没有办法进行关系推理,没有说明为什么是这个外部知识,从数据库中找到仅仅是相关的描述。
值得思考和借鉴的地方:
1,提取图像中的属性:后面的论文也将属性称为视觉概念,不同的是这篇论文中只用一种相似度找出和图像相关排名前五的属性。而后面的论文将属性(视觉概念)分为三类提取(对象,场景,动作),提取到的图像信息更加全面。
2,使用从图像中提取的属性生成相关的自然语言描述(方法beam search),在论文5中也用到了生成描述,不过使用的方法是dense caption.
3,其他的技术,比如相关提取事实,预测答案,后面的
这篇关于知识推理的VQA小结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



