本文主要是介绍论文解读之VQA视觉问答,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
VQA:Visual Question Answering
声明:借助翻译软件翻译 可能存在翻译错误,或者理解错误,希望批评指正一起学习。
Abstract 摘要
本文提出了以自由形式和开放式的视觉问答任务。给定图像和关于图像的自然语言问题,这个任务会给出一个精确的自然语言答案。视觉问题是有选择性的在图片不同区域包括背景细节或者基础上下文。与产生通用图片标题的系统相比,VQA上成功的系统通常需要对图像和复杂的推理有更详细的了解。此外,VQA易于进行自动评估,因为许多开放式答案内容仅仅需要几个单词或者是在多选题中提供的一组相近的答案,本文提供的数据集包括25万张图片,约76万个问题和1000万个答案。提供很多基准和方法与人类表现进行比较。
1 Introduction 引言
-
多学科人工智能研究问题出现热潮,特别是用于研究一张图片和视频字幕的计算机视觉、自然语言处理和知识表达与推理结合的研究在过去一年内高涨。我们认为如果让人工智能完成任务成为现实,AI算法必须具备两点:
- 多模态知识而不是单个子领域
- 能够很好的跟踪进度的定量评估指标
对于一些任务例如图像标题和自动评估仍然是一个困难开放的研究问题。
-
在本文中,我们介绍了自由形式和开放式的视觉问答任务,一个VQA系统将图像和关于该图像的开放式自然语言问题作为输入,产生一个自然语言答案作为输出。
开放式的问题需要潜在的大量的AI功能来回答-细粒度识别(披萨上有哪种奶酪?)、目标检测(有多少辆自行车?)、活动识别(这个男的在哭吗?)、知识库推理(这是素食披萨吗?)、常识推理(此人期望相伴吗?),VQA也适用于自动定量评估,从而有效的跟踪任务进度。虽然有些问题用"Yes’ or"NO"就可以轻松解答但确定正确答案的过程并不是简单的事,而且有关该图的问题通常倾向于寻求特定的信息,所以可能简单的1-3个单词就能够解答很多问题。此情况下,我们就根据正确回答的问题数量来评估提出的算法。本文中我们提出了两个任务:- 开放式答题任务
- 多项选择任务
与开放式不同,多项选择任务仅需从预定的答案列表中进行选择。
-
我们的数据集是来自MSCOCO数据集的204721张图片和新创建的50000张抽象场景图片,MSCOCO数据集具有各种复杂场景的图像,可以有效地引出各种令人信服的问题。我们收集了一个新的“真实”抽象场景数据集,使研究仅关注VQA的高级推理忽略掉解析真实图像的需要。对于每个图像或者场景我们收集了三个问题,每个问题都由10名志愿者带着他们的自信去回答。因此数据集将包含76万个问题大约1000万个答案。我们分析提出的问题类型和答案类型,还探讨了问题及其答案的信息内容与图像标题之间的区别。对于基线,我们还提供了几种结合文本和最新视觉功能的方法。
2 Related Work 相关工作
本节将介绍与VQA相关的工作
- VQA Efforts : 与最近的几篇受数据集限制的论文不同,他们仅考虑问题的答案是来自16种基本颜色或894个对象类别的预定义的封闭式答案,或者有些还考虑了从固定对象、属性、对象之间的关系等固定词汇表中生成问题。相反,我们提出的任务涉及人类提供固定开放式、自由行式的问题和答案。我们的目标是增加知识的多样性和提供正确答案的所需的各种推理。因此,我们的数据集要比他们大两个数量级。
- Text-based Q&A:基于文本的问答是经过充分研究的,这些方法为VQA提供了灵感,文本中一个关键问题是问题的基础。例如综合文本描述和QA对这些基于固定位置的参与者与对象的模拟,而VQA是基于图像-需要理解问题和视觉,我们的问题是由人提出的,这使得对常识和复杂推理要求高。
- Describing Visual Content:与VQA相关的图像标记、图像标题、视频字幕的任务,这些任务会生成单词或句子来描述视觉内容。虽然这些任务需要视觉和语义知识,但字幕通常可以是非特定的,VQA中的问题需要有关图像的详细特定信息,而这些在通用图像标题中很少使用。
- Other Vision+Language Tasks:由几篇论文在视觉和语言的交汇处探索了比图像字幕更易于评估的任务,例如共同参照分辨率或为特定对象生成参照表达。
3 VQA Dataset Collection VQA数据集收集
本节将介绍VQA数据集的获取,包括问题和答案的收集
VQA数据集分为真实图像和抽象场景,真实图像是来自MSCOCO数据集,抽象场景是新创建的,我们用这两种图像来收集问题及其答案。
-
真实图像:我们将MSCOCO的数据集分为123287作为训练集和验证集,81434作为测试集,
-
抽象场景:由于具有真实图像的VAQ任务需要带有复杂且噪声的视觉识别器,为了仅探索VQA的高级推理忽略掉噪声,我们创建了5万个抽象场景,数据集中包含20种纸娃娃人类模型,这种模型包括性别、年龄、种族等8种不同的描述。肢体可协调,姿势可变化,剪切画可描述室内室外场景,该场景包括100多种物体31种动物。
-
数据集拆分:真实图像遵循MSCOCO数据集相同拆分策略,对于抽象场景我们将数据集拆分成2:1:2的比例分为训练/验证/测试。
-
标题:MSCOCO对于所有真实图像已经包含5个单句标题,我们可以使用同样的用户接口创建我们的抽象图像的5个单句标题。
-
问题:我们要收集有趣多样且恰当的问题,许多简单的问题可能只需要简单的计算机视觉知识,但是我们还需要一些有关场景的常识问题,重要的是,问题还应该要求图像能够正确回答而不仅仅是靠常识解答。对于问题的收集抽象场景和真实图像使用相同的用户界面。每个问题/场景共收集三个问题且来自同一个志愿者。且每提一个问题时展示先前提出的问题以增加问题多样性。
-
答案:对于开放式问题会导致各种各样的答案,许多问题可能只需要简单的yes和no就足够回答,但是其他问题可能需要简单的短语,一些问题的答案也可能多样。因此,我们从特定的人员中为每个问题收集10个答案,同时还要确保回答问题的人没有提出该问题。我们要求人员提供的答案时简短的短语而不是完整的句子,而且还要询问受试者是否正确回答了问题来获取受试者的信息值,我们提供两种回答问题方式:
1:开放式
对于开放式的任务我们评估生成的答案使用以下方法来计算准确度
a c c = m i n ( 提 供 准 确 答 案 的 人 数 / 3 , 1 ) acc = min(提供准确答案的人数/3,1) acc=min(提供准确答案的人数/3,1)
即如果至少3名人员提供正确答案,则该答案被认为是100%准确,
2:选择题
对于多项选择任务每个问题都会创建18个候选答案,答案准确度与开放式计算方法一样。我们从四种答案中生成正确和不正确答案:①正确 ②合理③热门④随机…
4 VQA Dataset Analysis VQA数据集分析
本节我们将进一步分析VQA的数据集,主要针对数据集中的问题和答案进行分析,并将问题类型和答案分别进行可视化。我们探讨了仅使用常识就能回答问题的频率,最后分析图像标题中包含的信息是否足以回答问题。
4.1 问题
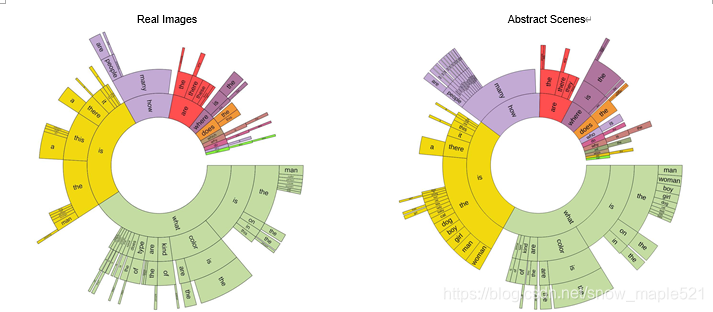
- 问题类型:给定以英语生成的问题结构,我们可根据引发问题的单词将问题分为不同的类型(图1.基于问题的前四个单词的问题分布 左:真实图像,右:抽象场景)
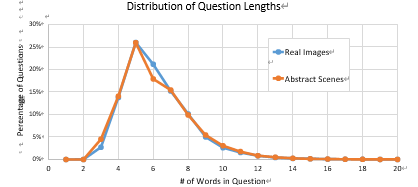
问题的长度分布,发现大多数问题集中在4-6之间
4.2 答案
-
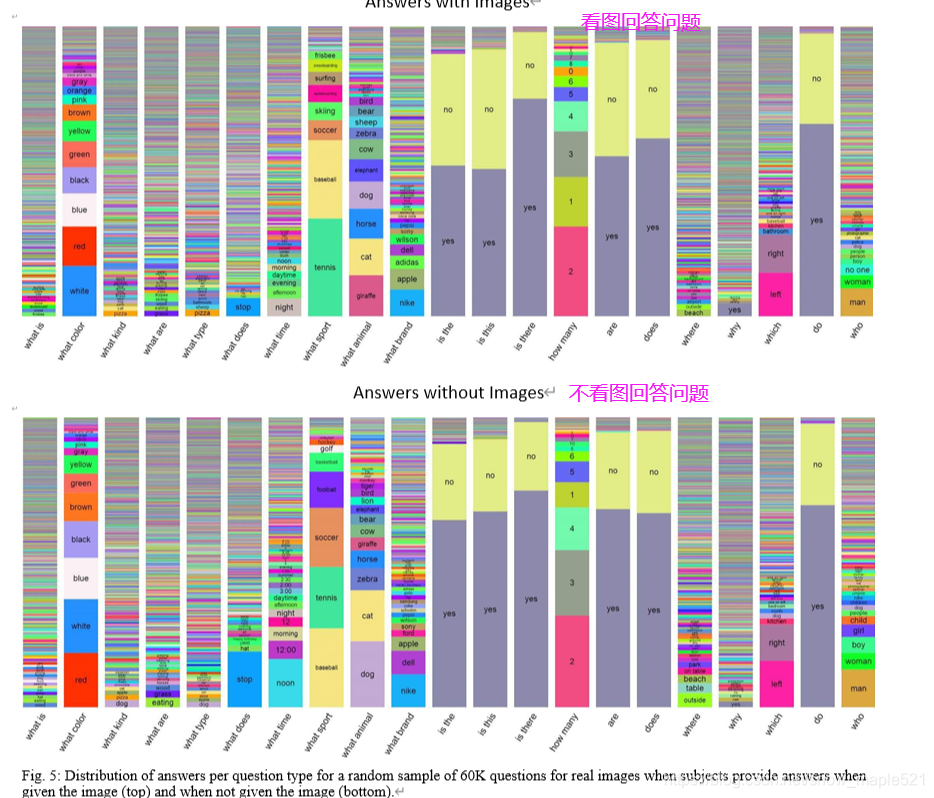
典型答案:
-
答案长度
大部分答案长度都是1,2,3个单词分别占比:89.32,6.91,2.74在真实图中, -
yes/no和数字的答案:
-
受试者信心:
-
受试者之间的一致性:
5 VQA BaseLines And Methods VQA基准和方法
5.1 Baselines
以baselines为基准来评估方法的好坏
- 随机:我们从VQA的训练和验证集上的top1000的答案列表中随机选择一个答案
- 先验(“yes”):对于开放式和多选我们始终选择最受欢迎的“yes”。注意“yes”始终是多项选择中的一个选项
- 每个问题先验:对于开放式任务我们为每个问题选择最流行的答案,对于多项选择我们采用word2vec特征空间的余弦相似性,从提供的选项中选择与开放式任务选择的答案最相似的答案。
- 最近邻:给定测试图像-问题对时,我们首先从训练集中找到k个最近邻问题和相关图像,对于开放式任务我们从最近的邻居问题中选择最常见的答案。类似每个问题先验,对于多项选择,我们也是采用余弦求最相近的答案。
5.2 Methods
对于方法,我们开发了两个通道一个时视觉(图像)通道,一个是语言(问题)通道,最终会以softmax方法输出K个可能的答案。我们选择前K=1000个最常见答案作为可能的输出这涵盖了训练验证答案数据集的82.67
-
Image Channel: 提供了图像嵌入,有两种图像嵌入:
①I:VGGNet的最后一个隐藏层的激活被用作4096维图像的嵌入
②norm I:VGGNet的最后一个隐藏层l2标准化激活 -
Ouestion Channel:此通道提供问题嵌入,尝试三种嵌入方式
①Bag-of-Words Question(BoW Q)词袋问题:问题数据集中的前1000个单词用于创建词袋,由于问题答案之间的相关性,我们找到前10个问题的第一个第二个第三个单词并创建一个30维的词袋表示法,将这些特征串联起来组成1030维的问题嵌入。
②LSTM Q长短期记忆网络 问题:带有一个隐藏层的LSTM来获取1024维问题的嵌入,每个问题词都通过全连接层+tanh非线性激活进行300维嵌入,然后送入LSTM模型中。嵌入层的输入词汇表包含在训练数据集中看到的所有疑问词。
③deeper LSTM Q:具有两个隐藏层的LSTM用于该问题获得2048维嵌入,然后是一个全连接层和一个tanh非线性激活将2048维像素转换成1024维, -
MLP多层感知机:将问题和图像的嵌入相结合后获得单个嵌入
①BoW Q + I :简单的将BoW Q对问题的嵌入和 I 对图像的嵌入连接起来
②LSTM Q + I and Deeper LSTM Q + norm I : 首先图像嵌入是通过全连接层+tanh非线性将图像转换为1024维,以匹配问题的LSTM嵌入,然后将变换后的图像和LSTM问题嵌入(在公共空间中)通过逐元素乘法融合。
然后将合并后的图像+问题嵌入传递到MLP(一个具有2个隐藏层和1000个隐藏单元的全连接神经网络分类器)每一层都有tanh非线性激活,然后是softmax层输出K个类型答案的分布。整个模型通过交叉熵损失来端对端学习。
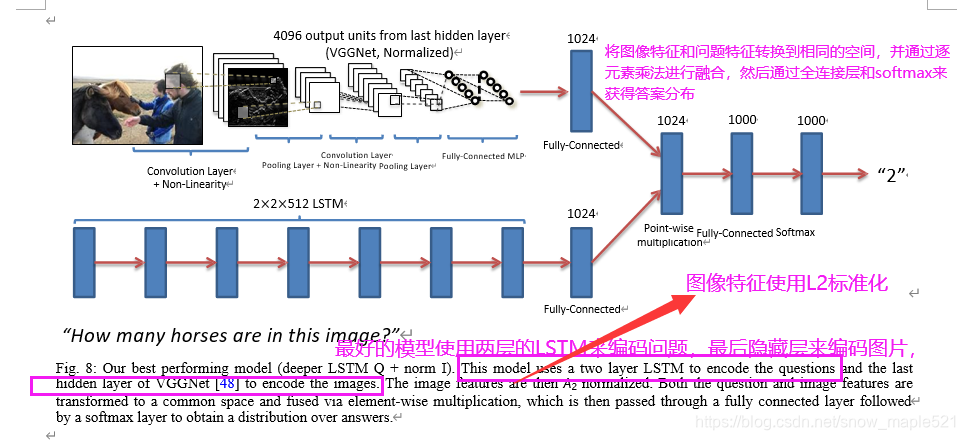
为了测试,我们提供两个不同任务结果:对于开放式我们从所有可能的K个答案中选择激活度最高的,对于多选我们从潜在答案中选择激活度最高的。整个 Deeper LSTM Q + norm I模型工作如下:
5.3 Result结果
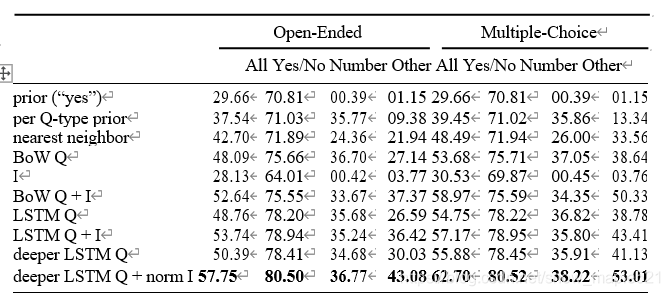
从结果中可发现deeper LSTM Q + norm I(采用VGGNet最后一层的l2归一化处理) 的模型效果最好。
注:加l2正则化和不加的区别是带正则化的损失为J = L + s(正则化项) 不加是J= L
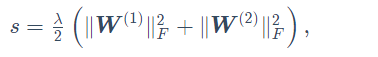
其中矩阵的Frobenius范数等价于将矩阵变平为向量后计算L2范数
6 VQA Challenge And Wordshop 研究与挑战
省略
7 Conclusion And Discussion 总结与讨论
省略
Appendix Overview 参考文献
省略
这篇关于论文解读之VQA视觉问答的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








