本文主要是介绍VQA-object_counting代码项目分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 写在前面
本文主要介绍《LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING》的代码项目,也就是别人的代码加上自己的注释。。。
博客地址:https://blog.csdn.net/snow_maple521/article/details/109190431
论文地址:https://github.com/Cyanogenoid/vqa-counting
项目地址:https://openreview.net/pdf?id=B12Js_yRb
1. 加载数据
由于仅仅介绍vqa2的部分,所以toy的实验,就不介绍了。
1.1 下载数据集
本节是项目数据集的下载,这些数据集需要提前下好,当然有Linux的环境可以直接命令行下载。
- 图像特征_trainval + 图像特征_test2015:采用的是自底向上的注意力提取的特征,它的论文在这,论文主要是用Visual Genome中对象和属性标注(关于Visual Genome介绍:知乎,CSDN)。这些预训练特征可直接在项目中下载,,不需要自己再重新训练。它分为每张图有10-100个自适应特征,还有一种是一张图中有36个固定特征,论文直接采用的是第二种(论文直接想利用注意力信息进行计数) 采用preprocess-features.py生成genome-trainval.h5文件存放图像特征相关数据。
- 问题特征:问题特征的提取,主要采用的是
self.embedding = nn.Embedding(embedding_tokens, embedding_features, padding_idx=0)
2. 加载数据集
加载数据集主要在train.py中,调用data.get_loader()
函数如下:
def get_loader(train=False, val=False, test=False):""" Returns a data loader for the desired split """#先是调用VQA类处理VQA数据集,图像特征调用的是preprocessed_trainval_path中的genome-trainval.h5文件split = VQA(utils.path_for(train=train, val=val, test=test, question=True),utils.path_for(train=train, val=val, test=test, answer=True),config.preprocessed_trainval_path if not test else config.preprocessed_test_path,answerable_only=train,dummy_answers=test,)#采用loader加载数据loader = torch.utils.data.DataLoader(split,batch_size=config.batch_size,shuffle=train, # only shuffle the data in trainingpin_memory=True,num_workers=config.data_workers,collate_fn=collate_fn,)return loader
图如下:数据集中已将答案表示和问题表示变成向量表示行式,红色注释部分,其中coco_id_to_index是将id变成索引方便再h5文件中获取相应特征。

具体变成向量表示的代码如下:
def _encode_question(self, question):""" Turn a question into a vector of indices and a question length """vec = torch.zeros(self.max_question_length).long()for i, token in enumerate(question):index = self.token_to_index.get(token, 0)vec[i] = indexreturn vec, len(question)def _encode_answers(self, answers):""" Turn an answer into a vector """# answer vec will be a vector of answer counts to determine which answers will contribute to the loss.# this should be multiplied with 0.1 * negative log-likelihoods that a model produces and then summed up# to get the loss that is weighted by how many humans gave that answeranswer_vec = torch.zeros(len(self.answer_to_index))for answer in answers:index = self.answer_to_index.get(answer)if index is not None:answer_vec[index] += 1return answer_vec
VQA类中的__getitem__(self,item)方法
在项目调用run(net, train_loader, optimizer, scheduler, tracker, train=True, prefix='train', epoch=i)函数时,模型就开始调用此__getitem__来获取单个条目的数据,
def __getitem__(self, item):if self.answerable_only:item = self.answerable[item]q, q_length = self.questions[item]if not self.dummy_answers:a = self.answers[item]else:# just return a dummy answer, it's not going to be used anywaya = 0image_id = self.coco_ids[item]v, b= self._load_image(image_id) #根据索引获取h5文件中相应的图像特征和边框# since batches are re-ordered for PackedSequence's, the original question order is lost# we return `item` so that the order of (v, q, a) triples can be restored if desired# without shuffling in the dataloader, these will be in the order that they appear in the q and a json's.return v, q, a, b, item, q_length
其中数据包括:v, b= self._load_image(image_id)注意此image_id真正图片id,
以下以item=28791为例
当item=28791,经过索引id获得图image_id=111864,问题对应三个:
{ “image_id”: 111864,
“question”: “What are the colors of the leaves?”, “question_id”: 111864000},
{“image_id”: 111864,
“question”: “Is anyone wearing a tie?”,
“question_id”: 111864001},
{“image_id”: 111864,
“question”: “Does the man on the right need to shave?”,
“question_id”: 111864002}
不懂:为啥同一个id多个问题时,只取了第一个问题后面的问题后来有没有被取到过???
例如此次传来的item是28791,image_id=111864,再将次传给load_image获取相应索引的h5文件中的图像和边框特征,传给v,b
def _load_image(self, image_id):""" Load an image """if not hasattr(self, 'features_file'):# Loading the h5 file has to be done here and not in __init__ because when the DataLoader# forks for multiple works, every child would use the same file object and fail# Having multiple readers using different file objects is fine though, so we just init in here.self.features_file = h5py.File(self.image_features_path, 'r')# if image_id not in self.coco_id_to_index:# return torch.from_numpy(np.zeros((1024,3,3))), torch.from_numpy(np.zeros((8))), torch.from_numpy(np.zeros((8)))index = self.coco_id_to_index[image_id]img = self.features_file['features'][index]boxes = self.features_file['boxes'][index]return torch.from_numpy(img).unsqueeze(1), torch.from_numpy(boxes)
函数中得到的boxes[4,100]的值如下,boxes的值36上就0了:

得到的img[1024,100]的值部分如下(72上就0了)
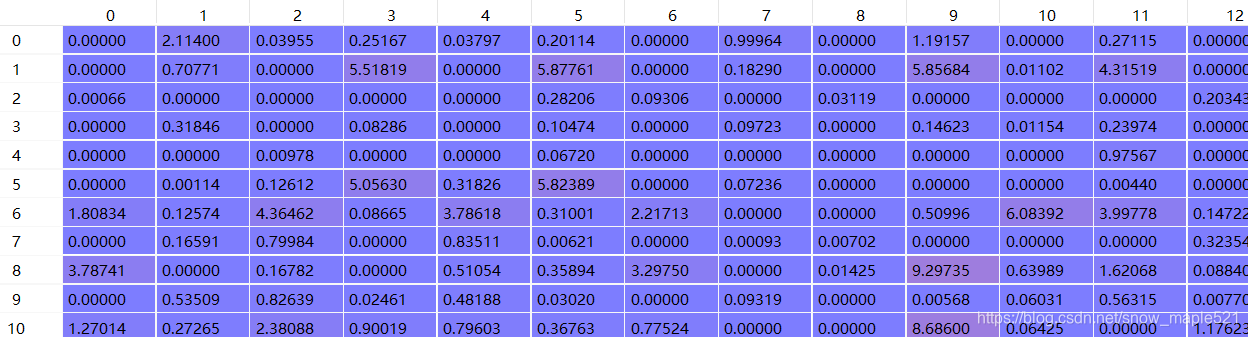
由于函数中返回值经过torch.from_numpy(img).unsqueeze(1)所有v的维度为【1024,1,100】b【4,100】,
至此,getitem返回值如下:
如下b:
v
q 返回的item=28791的问题向量= tensor([ 3, 4, 1, 128, 8, 1, 339, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
a 返回item= 28791的答案向量 = tensor([0., 0., 0., …, 0., 0., 0.])
q_length = 7
item = 28791

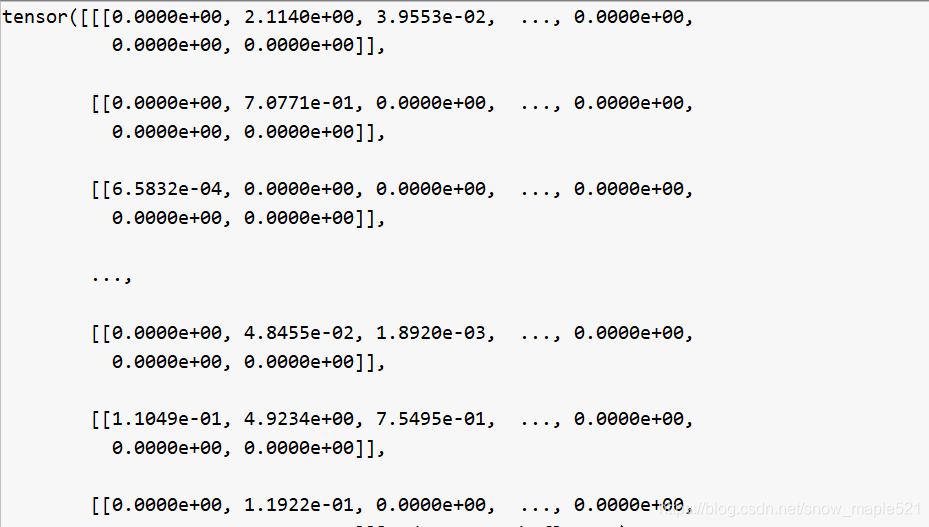
3.文本特征嵌入
此类主要是对问题向量进行词向量嵌入embedding,注意,此处只拿一个举,其实batch_size=5,传入的q维度应该为[5,23],embed应该是[5,23,300] 返回的应该是[5,1024]
传入的是q [23] = tensor([ 3, 4, 1, 128, 8, 1, 339, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0])
输出的是embed [23,300]= [
[ 0.0218, 0.0205, -0.0109, …, 0.0073, -0.0034, -0.0200],
[-0.0223, 0.0041, -0.0100, …, -0.0057, -0.0031, -0.0197],
[-0.0002, -0.0067, -0.0175, …, -0.0083, 0.0122, -0.0127],
…,
[-0.0102, -0.0095, 0.0112, …, -0.0233, -0.0214, 0.0092],
[-0.0102, -0.0095, 0.0112, …, -0.0233, -0.0214, 0.0092],
[-0.0102, -0.0095, 0.0112, …, -0.0233, -0.0214, 0.0092]]
经过 tanh和pack,squeeze之后,该模型返回【1,1024】:
[ 2.3714e-03, 9.1479e-03, 9.7701e-04, …, -1.2479e-02,
-2.6736e-03, -1.1262e-02],
class TextProcessor(nn.Module):def __init__(self, embedding_tokens, embedding_features, lstm_features, drop=0.0):"""embedding_tokens:问题中所有词,10571embedding_features:嵌入特征维度,300lstm_features:问题特征维度:1024"""super(TextProcessor, self).__init__()self.embedding = nn.Embedding(embedding_tokens, embedding_features, padding_idx=0)self.drop = nn.Dropout(drop)self.tanh = nn.Tanh()self.lstm = nn.GRU(input_size=embedding_features,hidden_size=lstm_features,num_layers=1)self.features = lstm_featuresself._init_lstm(self.lstm.weight_ih_l0)self._init_lstm(self.lstm.weight_hh_l0)self.lstm.bias_ih_l0.data.zero_()self.lstm.bias_hh_l0.data.zero_()init.xavier_uniform_(self.embedding.weight)def _init_lstm(self, weight):for w in weight.chunk(3, 0):init.xavier_uniform_(w)def forward(self, q, q_len):embedded = self.embedding(q)tanhed = self.tanh(self.drop(embedded)) packed = pack_padded_sequence(tanhed, q_len, batch_first=True)_, h = self.lstm(packed)return h.squeeze(0)
4.net网络中图像特征计算
v = v / (v.norm(p=2, dim=1, keepdim=True) + 1e-12).expand_as(v)由于实现提取好图像特征了,因此不需要再进行提取,【5,1024,1,100]
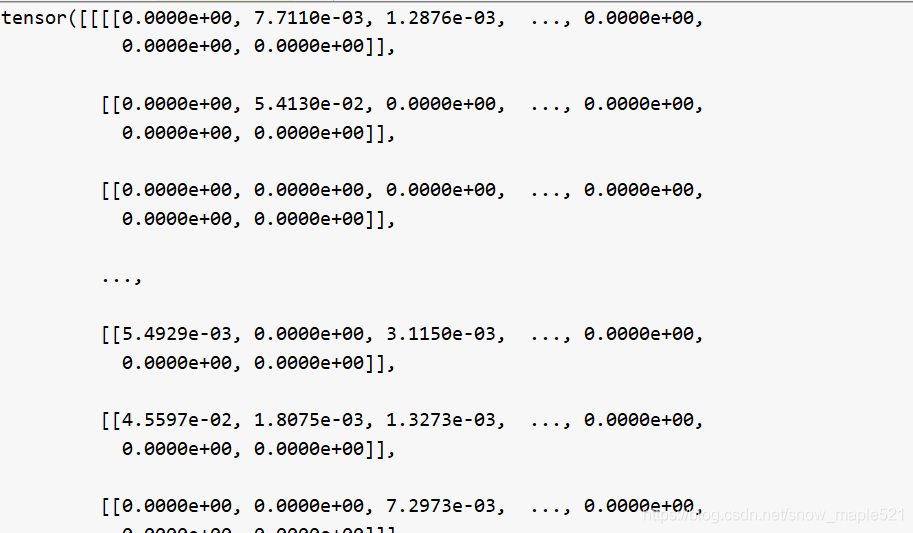
5.计算问题词向量和图像特征之间的软注意力特征
由3,4获得的词向量嵌入q[5,1024]和图像嵌入v[5,1024,1,100]之后传入到a = self.attention(v, q)获得融合了两个模态的注意力特征图 返回给a[5,2,1,100]。代码如下:
class Attention(nn.Module):def __init__(self, v_features, q_features, mid_features, glimpses, drop=0.0):#1024,1024,512,1super(Attention, self).__init__()self.v_conv = nn.Conv2d(v_features, mid_features, 1, bias=False) # let self.lin take care of biasself.q_lin = nn.Linear(q_features, mid_features)self.x_conv = nn.Conv2d(mid_features, glimpses, 1)self.drop = nn.Dropout(drop)self.relu = nn.ReLU(inplace=True)self.fusion = Fusion()def forward(self, v, q):'''v:[5,1024,1,100]q:[5,1024]'''q_in = q v = self.v_conv(self.drop(v))q = self.q_lin(self.drop(q))q = tile_2d_over_nd(q, v)x = self.fusion(v, q) x = self.x_conv(self.drop(x)) #5,2,1,100return x
a = self.attention(v, q)[5,2,1,100]后的a的值部分如下
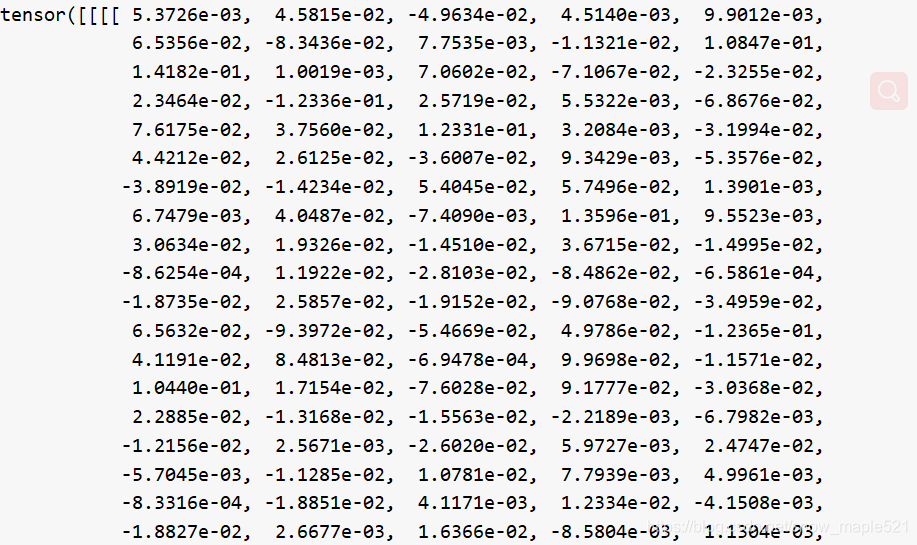
由于论文的创新之处在于不用原来的图像和问题特征进行对象计数,而是利用注意力特征信息来进行计数,所以接下来就是利用。
经过v=apply_attention(v,a)获取图像特征v[5,2048]如下:
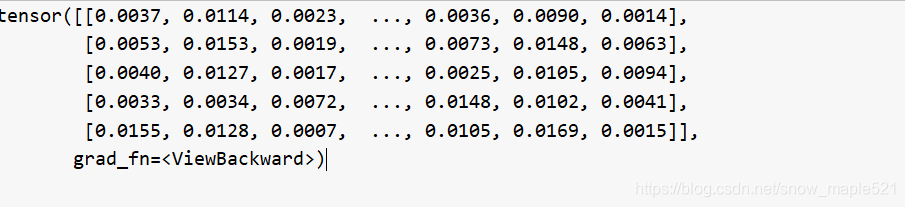
def apply_attention(input, attention):""" 在输入上应用任意数量的注意图。除了dim=1之外,注意图必须在所有维度上都有相同的大小"""n, c = input.size()[:2]glimpses = attention.size(1)'''因为我们不需要关心它们是如何排列的,所以将空间调平到第三层'''input = input.view(n, c, -1)attention = attention.view(n, glimpses, -1)s = input.size(2)'''对每个注意力图分别应用一个softmax
因为softmax只接受2d输入,所以我们必须将前两个维度折叠在一起
以便分别规范化每个瞥见'''attention = attention.view(n * glimpses, -1)attention = F.softmax(attention, dim=1)'''通过创建一个新的dim来平铺两个张量来应用加权'''target_size = [n, glimpses, c, s]input = input.view(n, 1, c, s).expand(*target_size)attention = attention.view(n, glimpses, 1, s).expand(*target_size)weighted = input * attention'''只对空间维度求和'''weighted_mean = weighted.sum(dim=3, keepdim=True)'''此时的形状为(n,瞥见,c, 1)'''return weighted_mean.view(n, -1) #n,c*瞥见数*1 = 2*1024=2048 返回[5,2048]
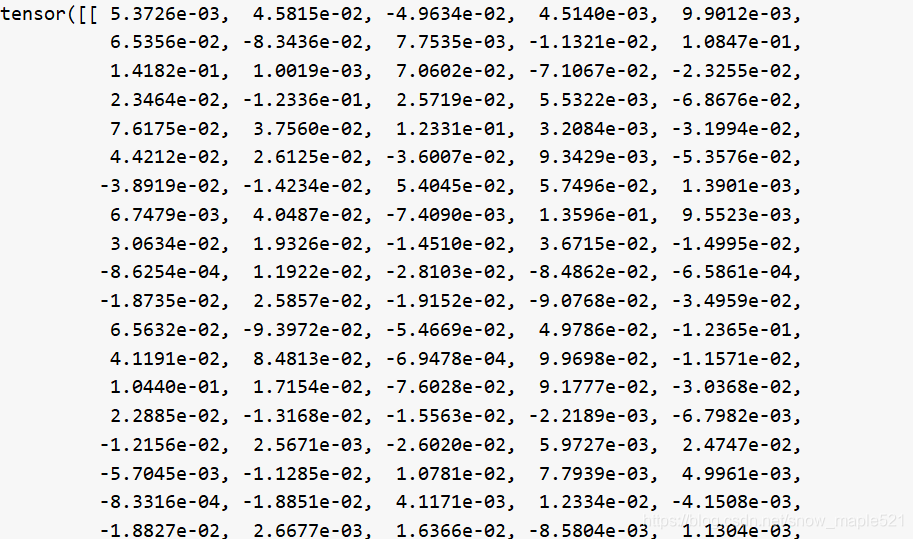
接着找出第一张注意力图(有2个瞥见)选第一个,这里是计数组件的地方,a1 =a[:, 0, :, :].contiguous().view(a.size(0), -1)这里的a[5,2,1,100]所以
a1=[5,100]
6. 计数组件
将5中获得的a1注意力图与边界框b,传个组件模型,就可以获得组件计数。具体如下:
将上面获得的a1=[5,100]与b[5,4,100]传给count = self.counter(b, a1)
b[5,4,100]的值如下:

代码如下
class Counter(nn.Module):""" 计数组件从每个边界框的一组边界框和一组分数中计算对象的数量"""def __init__(self, objects, already_sigmoided=False):"""objects:对象数 5already_sigmoided:是否已经归一化,false 没有"""super().__init__()self.objects = objects # 10self.already_sigmoided = already_sigmoidedself.f = nn.ModuleList([PiecewiseLin(16) for _ in range(16)]) #f赋值模型列表,PiecewiseLin 16个这个模型 16个分段函数def forward(self, boxes, attention):"""注意权重和边界盒的前向传播产生计数特征“boxes”必须是一个形状张量(n, 4, m), 4个通道按照这个顺序包含左上角的x和y坐标以及右下角的x和y坐标。“attention”必须是一个形状张量(n, m)。如果already_sigmoided设置为真,则每个值应该在[0,1],但是如果already_sigmoided设置为假,则没有任何限制。如果对应的boundign框是相关的,这个值应该接近1,如果不相关,这个值应该接近0。n为批大小,m为每幅图像的边框数量"""# 只关心得分最高的对象建议# 分数低的人对计数的影响很小# attention [5,100] torch.float32 cuda# boxes [5,4,100] torch.float64 cuda [batchsize,4,m] m:每幅图像的边界框数,也就是圈出来的对像数,论文中的虚线框出 选出了10个对象boxes, attention = self.filter_most_important(self.objects, boxes, attention) #过滤掉之后,剩下的是[5,4,5] ,[5,5]# 将权重归一化再 [0, 1]之间if not self.already_sigmoided:attention = torch.sigmoid(attention) #[5,5]relevancy = self.outer_product(attention) distance = 1 - self.iou(boxes, boxes) #D距离矩阵,采用边界框的相交-合并 Dij = 1-IOU(bi,bj)# intra-object dedup 消除对象内边缘:A_hat = f(A)*f(D) D是一个距离矩阵 得到一个分数score 此时score就是论文中的A_hatscore = self.f[0](relevancy) * self.f[1](distance) # inter-object dedup 采用f3和f4,与score(A_hat)相同,只不过具有不同的激活函数dedup_score = self.f[3](relevancy) * self.f[4](distance) # [6,10,10] torch.float64 cuda #论文中的X #f调用的是piecewiseLin模块#dedup_per_entry:每个条目的相似性,dedup_per_row:每行的相似性dedup_per_entry, dedup_per_row = self.deduplicate(dedup_score, attention) score = score / dedup_per_entry # aggregate the score 总比分# can skip putting this on the diagonal since we're just summing over it anyway# 可以不把它放在对角线上吗,因为我们只是对它求和correction = self.f[0](attention * attention) / dedup_per_row score = score.sum(dim=2).sum(dim=1, keepdim=True) + correction.sum(dim=1, keepdim=True) score = (score + 1e-20).sqrt()one_hot = self.to_one_hot(score) att_conf = (self.f[5](attention) - 0.5).abs() #论文中的pa公式9dist_conf = (self.f[6](distance) - 0.5).abs() #论文中的pD公式10conf = self.f[7](att_conf.mean(dim=1, keepdim=True) + dist_conf.mean(dim=2).mean(dim=1, keepdim=True)) #公式11return one_hot * conf
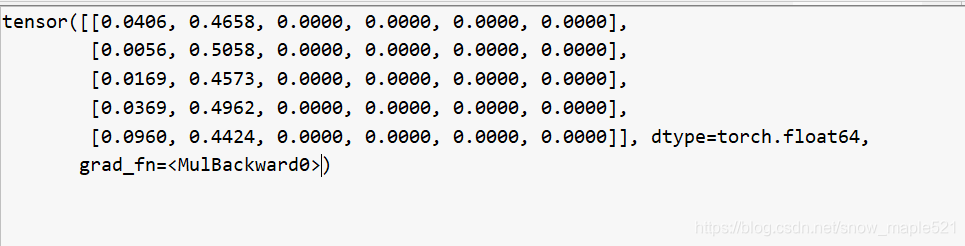
经过上面模型获得的count如下:
count[5,6]
7.模型答案预测
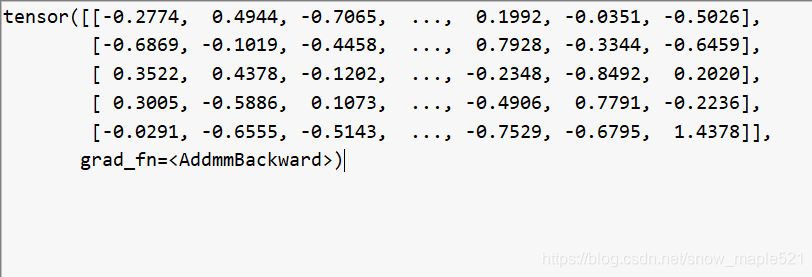
第6节获取的对象count张量,与加入注意力信息的图像特征v和词向量嵌入q,一起放入分类函数中,进行答案的预测。
answer[5,3000] = self.classifier(v, q, count)
8. 计算损失值与精度
8.1 计算损失值
通过调用out = net(v, b, q, q_len)获得了模型预测的答案向量大小为out[5,3000]batch_size=5.
然后将此结果与真实值a[5,3000]进行比较求损失值,
在求之前需要将预测的输出值out进行一次nll = -F.log_softmax(out, dim=1)
将得到的nll值与a进行损失值计算 loss = (nll * a / 10).sum(dim=1).mean()
log_softmax:能够解决函数overflow和underflow,加快运算速度,提高数据稳定性。就是softmax之后再做一次log运算,softmax值在[0,1]之间,log_softmax在【-∞,0]之间,本文中前加了负号,所以是[0,+∞]
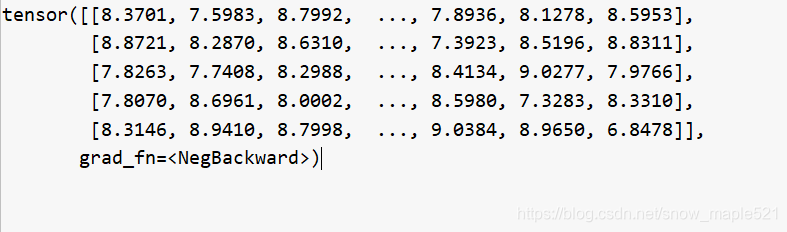
所有nll[5,3000] = -F.log_softmax(out, dim=1)的值为:
loss = (nll * a / 10).sum(dim=1).mean()的意思就是:
因为a为答案的向量表示,代表10个答案单词出现的位置标记其索引位置(vocab.json文件),没有值就标记为0,因此如果直接将nll与a相乘只有真实值出现的位置才有值,其余为0。
因为一组batchsize中的一个问题的答案的一个3000维的向量中最多有10个位置有值,其余为0,将其除10之后,再求每一行的和,接着求一个batch_size的平均值loss。
8.2 计算精度
acc = utls.batch_accuracy(out.data, a.data).cuda()
将每行答案向量中出现的最大值取出来,赋值给_,将这个最值对应的下标赋值给predicted_index,结果如下:
_=tensor([[1.3185],[1.8692],[1.9207], [1.6898],[2.3621]])
predicted_index=tensor([[ 93],[1724], [1550], [ 891],[1594]])
将得到的predicted_index下标传个真实值agreeing = true.gather(dim=1, index=predicted_index)(按行索引)
得到此时的agreeing=tensor([[0.], [0.],[0.],[0.],[0.]])
此结果说明,本次的模型预测的一个batch_size的答案predicted的最大值的索引对应在真实答案向量中的值为0,说明我们预测的答案不准确。
def batch_accuracy(predicted, true):""" 计算一个batch_size的预测和答案的准确性 """_, predicted_index = predicted.max(dim=1, keepdim=True) #选出一行中最大的值赋值给_,将最大值出现的下标赋值给predicted_index。agreeing = true.gather(dim=1, index=predicted_index) #return (agreeing * 0.3).clamp(max=1)
此时求的是整个所有问题的精度,没有区分类别,后面将预测的答案和相关问题id保存在result.json文件中,将其传入vqa评估平台即可获取每个问题类型的相关答案,当然我们也可以自己调用VQAEval类进行结果输出。
这个是计算每条问题估计答案的准确率的结果
9.写在最后
写到这,项目大致流程也已了解,由于篇幅有限,项目链接已给,所以没有将完整代码贴出。见谅!写的很乱,愿你能读懂吧!
常遇到的问题:
在运行项目中,常遇到以下问题:
①数据类型不匹配如下:expected type torch.cuda.DoubleTensor but got torch.cuda.FloatTensor
解决方法:
w = w.type(torch.DoubleTensor)相应位置类型转换一下即可②CUDA数据非法访问
RuntimeError: CUDA error: an illegal memory access was encountered
解决方法: 这个错误,是我的粗心造成的,在上面数据类型报错,更改时,导致w=f.type(tensor.Float),这个错误找了好久,最后逐个调试,才发现w的维度不对。导致x = x + f * w.gather(0, (idx+1).clamp(max=self.n))越界非法访问数据。所以遇到这个错你要调试看维度对不对,有没有访问越界。这里多说一句gather的用法
③很多时候出现CUDAmemoryError这个就要改batch_size了
④如果出现啥[5,6]和[7,8]维度不匹配时就要注意你的特征维度设置了
这篇关于VQA-object_counting代码项目分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




