本文主要是介绍【论文小综】基于外部知识的VQA(视觉问答),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们生活在一个多模态的世界中。视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知。作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题。从15年首次被提出[1]至今,其涉及的方法从最开始的联合编码,到双线性融合,注意力机制,组合模型,场景图,再到引入外部知识,进行知识推理,以及使用图网络,多模态预训练语言模型…近年来发展迅速。 传统的VQA仅凭借视觉与语言信息的组合来回答问题,而近年来许多研究者开始探索外部信息对于解决VQA任务的重要性。

如图所示,这里的VQA pair中,要回答问题“地面上的红色物体能用来做什么”,要想做出正确的回答“灭火”,所依靠的信息不仅来源于图片上所识别出的“消防栓”,还必须考虑到来自外部的事实(知识)“消防栓能灭火”作为支撑。这就是一个典型的VQA上应用外部知识的场景。传统的VQA近些年发展迅速,随着CV/NLP方向基础理论的发展,在模型性能,覆盖数据方面均有了大幅提高。传统VQA模型之外,基于预训练语言模型的多模态VQA任务也逐渐兴起,大家开始关注如何利用多模态预训练的方法,解决通用VQA问题。
但以上种种方法,始终无法解决这些需要外部知识的困难VQA问题。接下来我将结合多篇论文简述在VQA上应用外部知识的方法,做相应的梳理。
【1】Ask Me Anything: Free-Form Visual Question Answering Based on Knowledge From External Sources
发表会议:CVPR 2016
会议等级:CCF-A
论文链接:Ask Me Anything
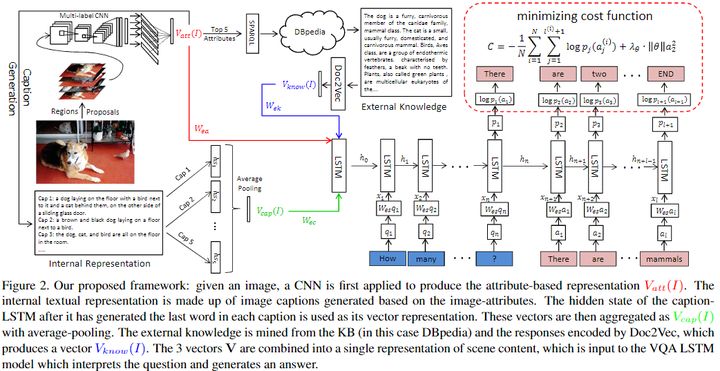
推理与知识的实际存储进行分离是基于外部知识VQA相关论文所持的观点。该论文核心思想是将自动生成的图像描述与外部的Knowledge bases融合,以实现对问题的预测。其中生成图像描述的方法借鉴了同年作者发表的了一篇文章[5]:给定一张图像,先预测图像中各种属性,然后再将这些属性代替之前的 CNN 图像特征,输入到 RNN 当中生成语句。这个简单的操作使他们的图像标注模型在当年 COCO图像标注大赛上排名第一。添加中介属性减小双模态鸿沟的方法,也用在了本文中。
对于一个给定的V-Q pair,首先用CNN提取图片特征属性,然后利用这些检测到的属性,使用sparql查询语句从knowledge base比如DBpedia中提取出图像相关描述的一个段落,利用Doc2Vec对这些段落编码。同时,根据图片特征属性使用Sota的image caption方法形成图像对应的段落特征表达。
最后将上面两种信息以及编码的属性结合在一起并输入作为一个Seq2Seq模型的初始初始状态,同时将问题编码作为LSTM的输入,利用最大似然方法处理代价函数,预测答案。

该方法的可解释性相对于端到端的模型而言强了许多,这也是后续许多模型采用的思想,即各种特征融合到一起然后丢到一个递归网络例如LSTM中。最后在COCO-QA数据集上取得了Sota效果。

【2】Fvqa: Fact-based visual question answering
发表期刊:TPAMI 2018
期刊等级:CCF-A
论文链接:Fvqa
代码地址:data
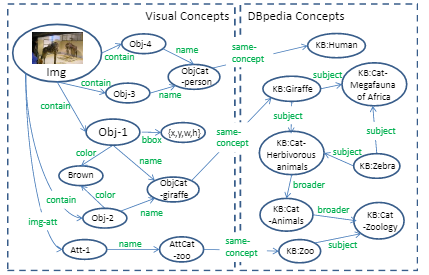
既然knowledge 和 reasoning 对 VQA 都很重要,那么就可以考虑将它们两个结合在一起,进行显示推理。和以往直接把图像加问题直接映射到答案不同,作者提出的Ahab[3]模型的答案是可追溯的,就是通过查询语句在KG中的搜索路径可以得到一个显式的逻辑链。这也是一种全新的能够进行显式推理的 VQA 模型。并且,他们提出了一种涉及外部知识的VQA任务。它首先会通过解析将问题映射到一个 KB 查询语句从而能够接入到已有知识库中。同时将提取的视觉概念(左侧)的图链接到DBpedia(右侧)里面,如下图所示。
同期发表的FVQA是对其的改进和梳理,并且贡献了这方面很重要的数据集:除了一般的图片、问题、回答以外,这个数据集还提供了支撑这一回答的事实Facts事实集合(参考数据来源于DBpedia, Conceptnet, WebChild三个数据库),共包括4216个fact。某种意义上来说,该数据集是基于fact去针对性构建的。具体如下:
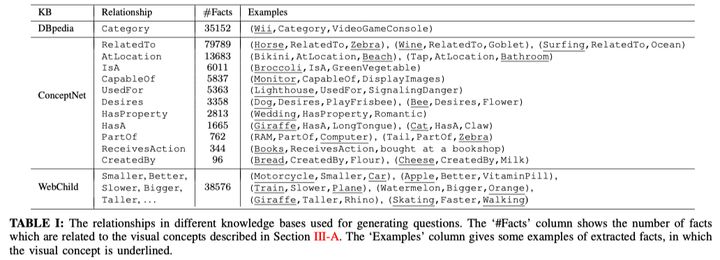
在实际的数据中,fact以关系三元组的形式表示,其中的relationship使用来自于数据库中已有的定义。
模型的第一部分和ahab类似,检测图像中的视觉概念,然后将他们与知识库对齐并连接到subgraph中。第二步将自然语言式的问题映射到一个查询类型,然后相应地确定关键的关系类型,视觉概念和答案源。再根据上面的信息构建一个特殊的查询会去请求上一步当中建立好的图,找到所有满足条件的事实。最后通过关键词筛选得到对应问题的答案。
【3】Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering
发表会议:NIPS 2018
会议等级:CCF-A
论文链接:Out of the box
代码地址:
前文提出的方法大多类似于组合模型。此外,近几年也有涉及到图来解决外部知识VQA问题的方法[7]。
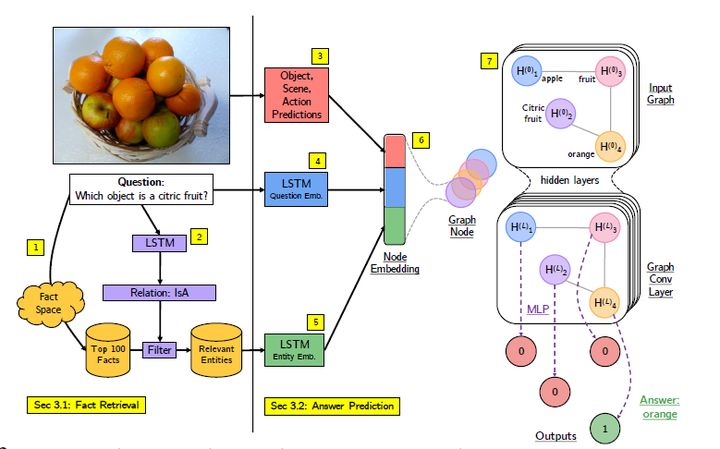
该文章的作者基于FVQA数据集,把之前深度网络筛选事实的这一训练过程用图卷积网络代替,成为一个端到端的推理系统,用于具有知识库的视觉问题解答。
一共分为七个步骤,给定图像和问题,首先使用相似性评分技术根据图像和问题从事实空间获得相关事实。 使用LSTM模型从问题预测关系,筛选fact来进一步减少相关事实及其实体的集合。然后分别进行图像视觉概念提取,问题的LSTM嵌入,以及事实词组的的LSTM嵌入,将图像的视觉概念multi-hot向量和问题的lstm嵌入向量组合,并与每一个实体的LSTM嵌入拼接,作为一个实体的特征表示,同时也是作为GCN模型里图上的一个节点。图中的边代表实体之间的关系。最后将GCN输出的每一个实体节点特征向量作为多层感知机二元分类模型的输入,最后输出的结果通过argmax得到最终的决策结果。
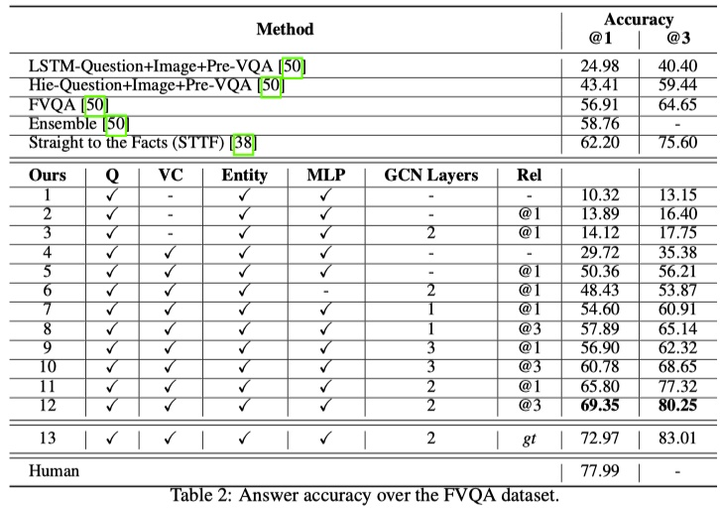
模型在双层GCN以及top3 relation的设定下,超过了FVQA的方法大概10%。(58.7%->69.3),结果如下:
【4】Straight to the facts: Learning knowledge base retrieval for factual visual question answering
发表会议: ECCV 2018
会议等级:CCF-B
论文链接: Straight to the facts
代码地址:
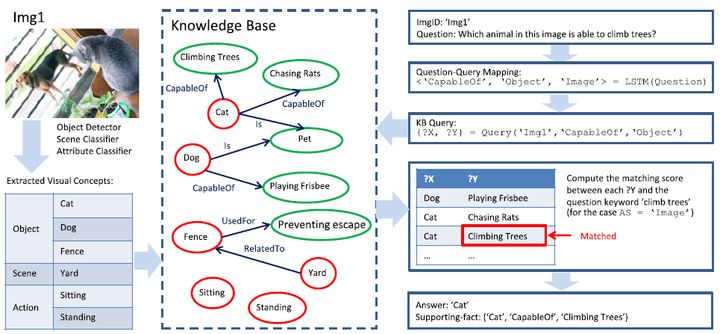
在回答给定上下文(例如图像)的问题时,该文章将观察到的内容与常识无缝结合在一起。对于自然参与我们日常工作的自主代理和虚拟助手,在最常根据上下文和常识回答问题的地方,利用观察到的内容和常识的算法非常有用。许多前述方法集中在问题回答任务的视觉方面,即,通过结合问题和图像的表示来预测答案。这与描述的类人方法明显不同,后者将观察与常识相结合。为此,相关研究设计了一种从问题中提取关键字并从知识库中检索包含这些关键字的事实的方法。但是,同义词和同形异义词构成了难以克服的挑战。
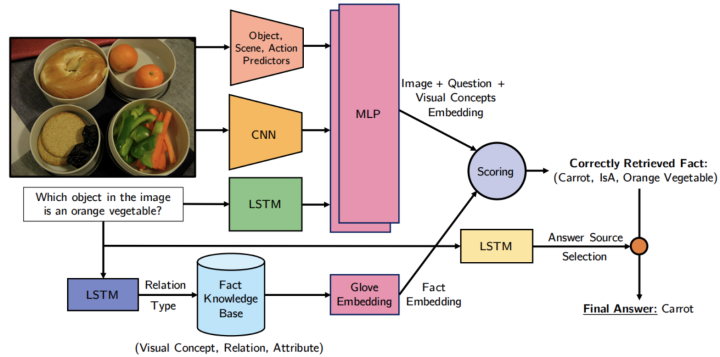
为了解决这个问题,作者开发了一种基于学习的检索方法,如图 所示。更具体地说,他们的方法学习事实和问题图像对到嵌入空间的参数映射。为了回答问题,他们使用与所提供的问题图像对最一致的事实。知识库中的事实是根据视觉概念(例如,对象,场景和从输入图像中提取的动作)进行过滤的。然后将预测的查询应用于过滤后的数据库,从而获得一组检索到的事实。然后,在检索到的事实和问题之间计算匹配分数,以确定最相关的事实。最正确的事实构成了问题答案的基础。
给定图像和关于图像的问题,通过在图像上使用CNN,在问题上使用LSTM以及将两种方式组合在一起的多层感知器(MLP)来获得图像+问题嵌入。 为了从知识库(KB)中过滤相关事实,使用另一个LSTM从问题中预测事实关系类型。 使用GloVe嵌入对检索到的结构化事实进行编码。 通过嵌入向量之间的点积对检索到的事实进行排序,并返回排名靠前的事实以回答问题。
当前的任务是通过使用外部知识库KB来预测给定图像x的问题Q的答案y,该知识库由一组事实fi组成,知识库中的每个事实fi都表示为形式为fi =(ai, ri, bi) 的资源描述框架(RDF)三元组,其中ai是图像中的视觉概念,bi是与主题相关的属性或短语 ri是两个实体之间的关系。 数据集| R | = 13包含关系r = {Category, Comparative, HasA, IsA, HasProperty, CapableOf, Desires, RelatedTo, AtLocation, PartOf, ReceivesAction, UsedFor, CreatedBy}。 数据集中的知识库的三元组示例有(Umbrella, UsedFor, Shade), (Beach, HasProperty, Sandy), (Elephant, Comparative-LargerThan, Ant).
该模型一共有三个需要训练参数的模块:
预测fact关系类型的多分类器;
预测答案来源的二分类器;
计算fact score的模块,主要的参数在参与编码GNN的MLP中。
文章把这三个模块分别进行单独的训练。前两个只是简单的分类模型,因此用对应的数据和cross-entropy loss进行训练即可。第三个模块的训练则稍微费劲一些。这里追求的目标是,ground-truth fact 的score比其他的score更大,为此,文章借鉴了软间隔SVM的思想,确保以下的条件成立:
此外,文章还用到了hard negative mining的训练方法。面对数据集规模不大的情况(FVQA数据集中只有5,286个问题),该方法强化了模型对错判的纠正,从而有效提升模型的准确性。
【5】Ok-vqa: A visual question answering benchmark requiring external knowledge
发表会议: CVPR 2019
会议等级:CCF-A
论文链接: OK-VQA
代码地址:data
该文章[6]的问题背景是,对于已有的小部分需要外部知识的数据集,依赖于结构化知识(例如上文提到的FVQA)。而已有的VQA数据集,问题难度普遍不高,标准VQA数据集,超过78%的问题能够被十岁以下儿童回答。
于是,作者提出并构建了一个(最)大规模的需要外部知识的数据集( Outside Knowledge VQA ),并且在OK-VQA数据集上就目前最好的VQA模型提供了benchmark实验。与此同时,提出了一种ArticleNet的方法,可以处理互联网上的非结构化数据来辅助回答其中的问题。
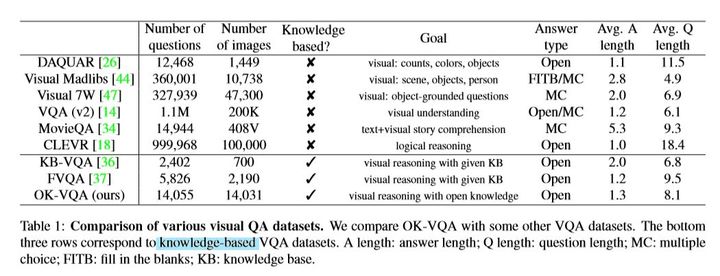
数据集大小和对比如下:
因为标准VQA数据集质量不高(难度低),所以作者自行请MTurk工人,从COCO数据集中进行了数据采集、问题搜集、问题质量筛选、问题回答。同时通过过滤操作,降低了bias的影响,减少文本对于某些回答的偏差(如 Is there ...)。同时考虑了长尾效应。就数据分类而言,划分了10+1(other)个类别,保证问题类型的互斥。

图片场景覆盖了COCO总共的365个场景中的350.。保证了覆盖率和分布的合理性。 就ArticleNet模型而言,其分为三步:
(1)从图片(pre-trained+ scene classifiers)和问题pair中搜集关键字,并组合成可能的query (2)使用wiki的API进行检索,获得排名最高的几个文章。 (3)基于query 的单词在这几篇文章中得到最有可能的句子。 (4)【可选】从句子中得到最有可能的词作为答案。
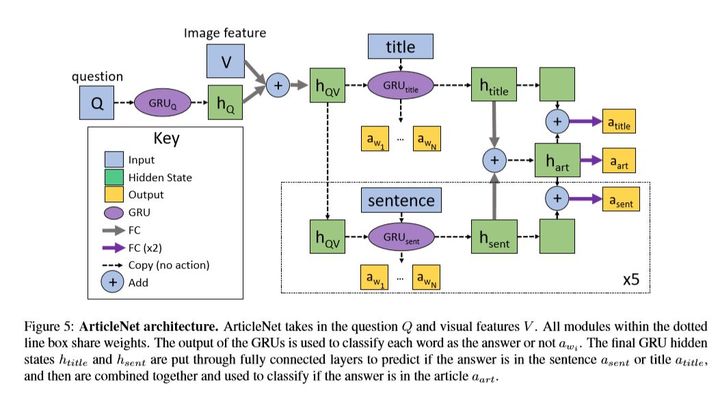
ArticleNet模型可以与许多已有的VQA模型进行拼接以提升模型在外部知识VQA场景下性能。作者进行了相应实验:
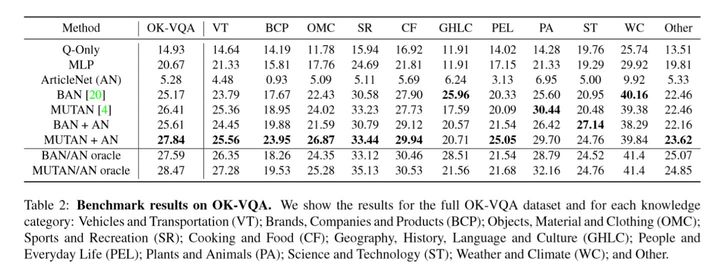
其中ArticleNet的结合方法是将sentence与具体模型中某一层的输出向量进行一个向量拼接,以捕获外部信息。ArticleNet单独作用的方法可能一般(依赖于互联网数据,比较死板),但是如何和其他模型结合e.g. mutan、ban(end-2-end),效果都会有提升。同时其并不是和VQA模型一起训练,可以单独训练。如下是ArticleNet在其中起作用的例子:

【6】Kvqa: Knowledge-aware visual question answering
发表会议:AAAI 2019
会议等级:CCF-A
论文链接:KVQA
代码地址:
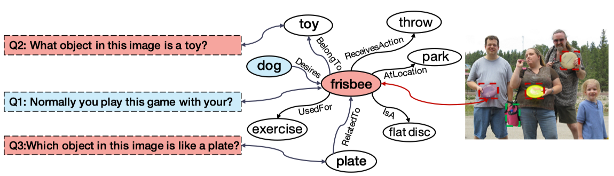
这篇论文发表在2019年AAAi上,核心贡献在于发布一个关注图片中命名实体知识的数据集,解决这个问题需要的知识区别于常识知识,而是作者所提到的world knowledge。如图
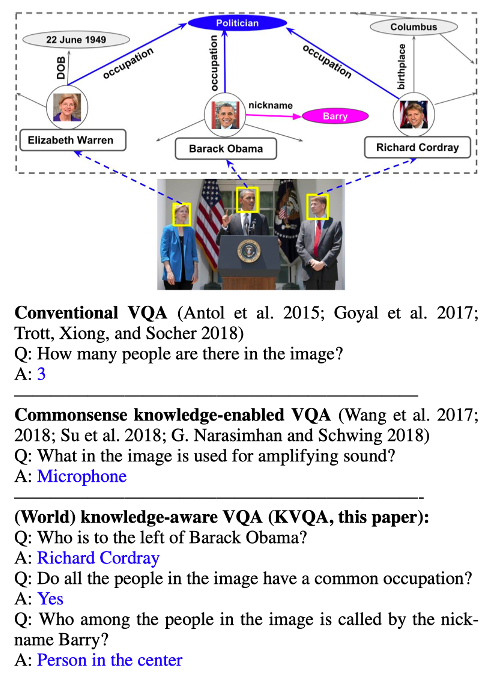
它提出的方法并没有很大的创新点,简单描述一下就是三个步骤。
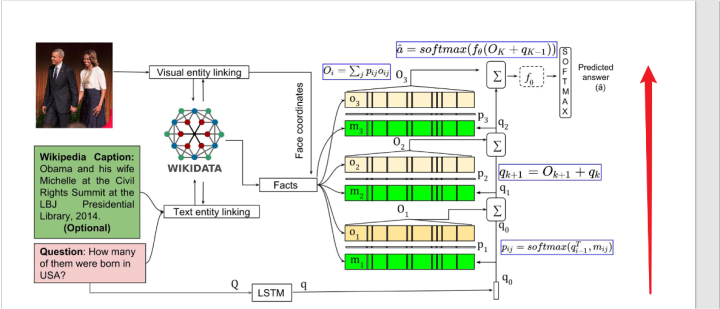
第一步把问题和图像使用某些方法,对齐到一个知识库中,然后第二步把对齐得到的fact和相关人物的坐标拿出来,用一个模型比如BLSTM进行表示。
第三步和问题的表示进行进行soft attention(也就是点乘之后进行softmax),然后相加,最后输入到一个softmax中进行分类。这里作者应该是希望模型能找到和当前问题最相关的fact,给其更高的权重,以进行最后的分类。
然后作者模型为了解决逻辑是multi-hop的多跳视觉问答问题,使用了模型堆叠的方法,也就是把第三步里面的soft attention重复三次,每次的问题输入的表示是前一层的输出。
模型整体结构如图所示:
缺点:commonsense knowledge 和world knowledge就组织方式而言我不认为有明显的区别。
方法没有明显的创新
【7】Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering
发表会议:IJCAI 2020
会议等级:CCF-A
论文链接:Mucko
代码地址:code
作者对比了前人的工作,一个方向是将问题转化成关键词,然后在候选事实中根据关键词匹配检索出对应的支撑事实的pineline方式,比如前文所提的FVQA,但是如果视觉概念没有被问题完全提及(比如同义词和同形异义词)或者事实图中未捕获提及的信息(比如它问红色的柱子是什么,却没有提到消防栓),那这类方法就会因为匹配而产生误差。另一个方向将视觉信息引入到知识图中,通过GCN推导出答案,就比如前文提到的out of the box模型。虽然解决了上面的问题但是每个节点都引入了相同且全部的视觉信息,而只有一部分的视觉信息和当前节点是相关的,这样会引入噪声。并且每个节点都是固定形式的的视觉-问题-实体的嵌入表示,这使得模型无法灵活地从不同模态中捕获线索。而本文[8]则较好地解决了上述问题。
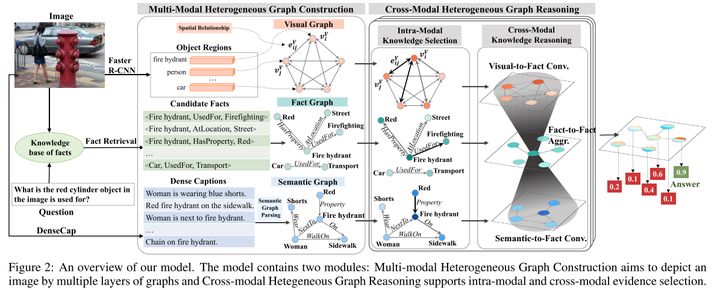
文章的出发点是将图像表示成一个多模态的异构图,其中包含来自不同模态三个层次的信息(分别是视觉图、语义图和事实图),来互相补充和增强VQA任务的信息。具体来说,视觉图包含了图像中的物体及其位置关系的表示,语义图包含了用于衔接视觉和知识的高层语义信息,事实图则包含图像对应的外部知识,它的构造思想参考了out of the box 模型。
然后进行每个模态内的知识选择:在问题的引导下确定每个节点和边在内部图卷积过程中的分数权重占比,然后进行常规的update操作。也就是说在跨模态之前,先独立选择单个模态内有价值的证据,让和问题相关性强的节点及边,在图内部卷积过程中占更大的权重。这三个模态内部的卷积操作都是相同的,只是节点和边的表示不同。
最后,跨模态的知识推理是基于part2模态内的知识选择的结果。考虑到信息的模糊性,不同图很难显式地对齐,所以作者采用一种隐式的基于注意力机制的异构图卷积网络方法来关联不同模态的信息,从不同层的图中自适应地收集互补线索并进行汇聚。包括视觉到事实的卷积和语义到事实的卷积。比如视觉到事实的卷积场景中,对于事实图中的每个节点vi,计算视觉图中每个节点vj和它在问题引导下的相似度注意力分数,越互补的节点它的相似度分数就越高,然后根据这个分数对视觉图加权求和,得到事实图中每个节点来自视觉图层的事实互补信息。
分别迭代地执行Part2模态内的知识选择和Part3跨模态的知识推理,执行多个step可以获得最终的fact实体表示,并将其传到一个二元分类器,输出概率最高的实体当做预测的答案。
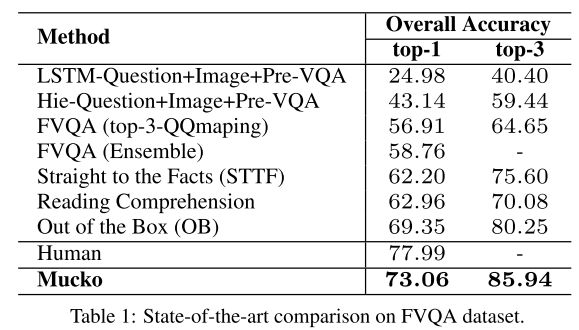
模型在三个数据集上验证了实验结果。该模型在FVQA上表现很好:
另外一个数据集Visual7W KB也和FVQA类似,问题是直接根据Conceptnet生成的。不同点在于他不提供fact。可以看到结果也明显好于Sota。
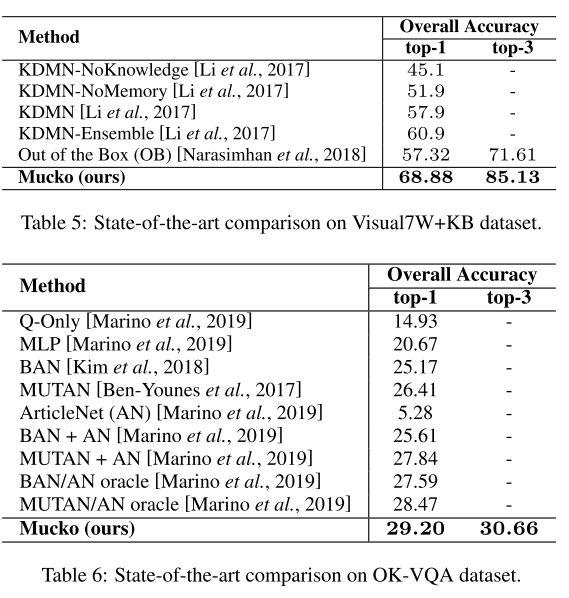
第三个数据集OK-VQA比较特殊,没有知识库作为参考,知识跨度大难度高,sota只有30%不到。该模型在其上表现的不太好,不过还是比Sota要高大概0.7%。原因猜测是光凭借单一的外部知识库可能不足以对ok-vqa达到较大提升,所以ok-vqa问题在未来实际上还有很大的提升空间。
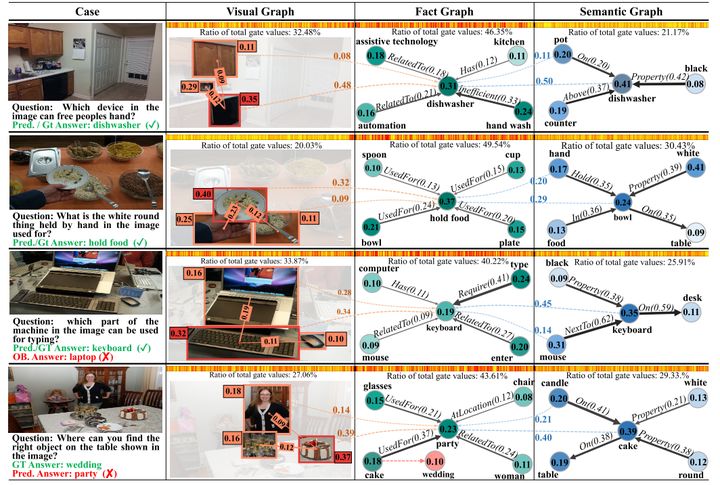
该模型另外一个优点是结果具有比较好的解释性。上图是FVQA数据下测试的结果。把fact graph中最重要fact所对应的top2视觉和语义对象节点,用虚线连接,虚线上的值表示了跨模态卷积中不同层哪些节点对结果影响重要性更大,结果比较直观。热力条根据最后特征融合时的gate值得到,密度越大则代表对应位置通道的重要性越高。可以发现,在大多数的情况下事实信息会更重要,也就是密度最大。因为FVQA中97.3%的问题都是需要额外知识才能回答的。而密度第二大的区域往往会由问题的类型决定是视觉更重要还是问题更重要。比如第二个图中问题里面的hold by这个词无法在图片中具体体现,所以所以语义信息的占比会更大一些。而第一个图的话则视觉信息占比更大。
【8】Conceptbert: Concept-aware representation for visual question answering
发表会议:EMNLP 2020
会议等级:CCF-B
论文链接:Conceptbert
代码地址:code
普通VQA的工作主要关注直接分析问题和图像就可以得出答案的问题(没有外部知识),对于需要常识/外部结构化基本事实支撑的VQA问题,可以分为两种方法:
方法一:对于需要 常识/外部结构化基本事实 支撑的VQA问题
方法二:对于需要 常识/外部结构化基本事实 支撑的VQA问题
他们有以下缺点:
1) 不是 end-to-end;
2) 不是 fully trainable;
3) 大多基于普通词嵌入;
基于此,本文作者提出了一种Concept-Aware的算法,使用 ConceptNet KGE 来编码 common sense knowledge(对数据集无要求, 不需要查询query, 使用了bert),主要创新点来自于:
-
1) 学习了一个 joint Concept-Vision-Language embedding 来解VQA问题。
-
2) 捕捉 image-question-knowledge 直接的特殊交互。
其中三种模态的交互过程如图所示:
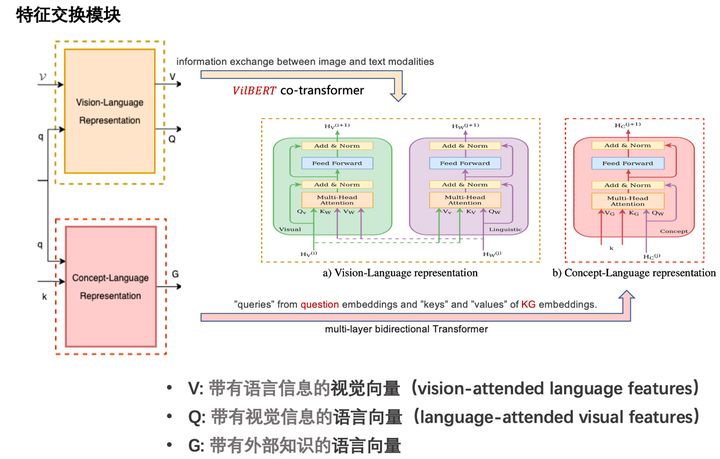
文章整体模型如图所示:
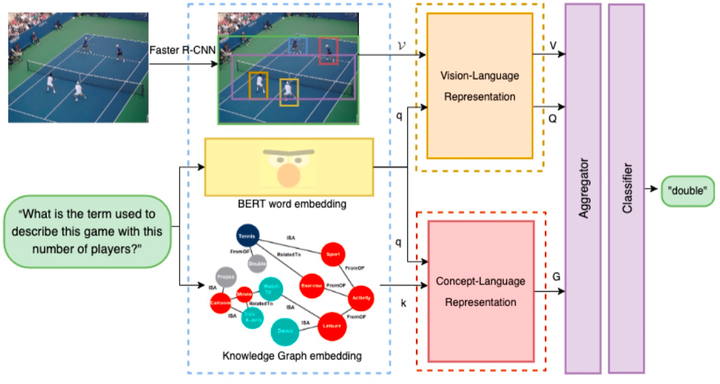
并最终模型取得了不错的效果:
-
VQA 2.0 (not sota);
-
OK-VQA(sota)
整个流程可以表示于:
- 得到对应模态的嵌入表示 - 通过两个并行模态融合模块 --- 视觉-语言(输出2个向量) --- 知识-语言(输出1个向量) - 聚合三种向量 --- 带有语言信息的视觉向量 --- 带有视觉信息的语言向量 --- 带有外部知识的语言向量 - 分类器进行答案分类
该工作有以下的前置工作:
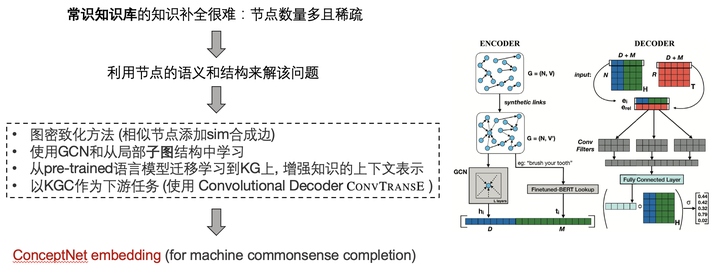
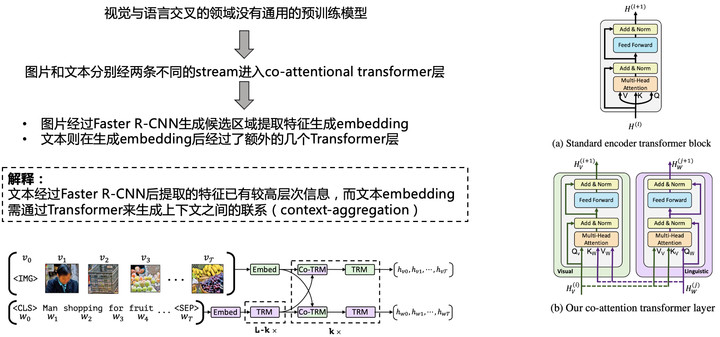
该文章对于后续工作有许多启发:常识知识库某种程度上可增强许多VQA任务,哪怕不是显式地需要外部知识。多模态任务中以图的形式引入外部知识依然有很大的潜力可以挖掘,预训练fine-tune +(交叉)注意力机制 + 外部知识 + KG图结构 某种程度上可以使得 信息最大化.
【9】Zero-shot Visual Question Answering using Knowledge Graph
发表会议:ISWC 2021
会议等级:CCF-B
论文链接:ZS-F-VQA
代码地址:code/data
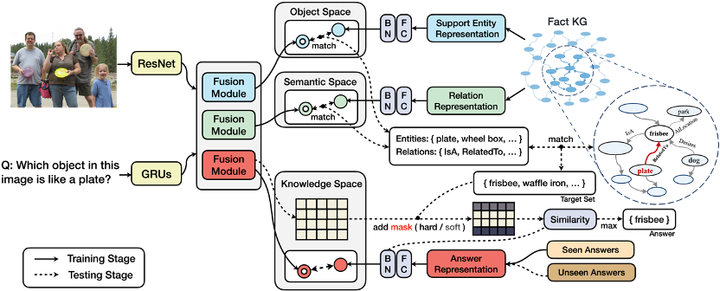
现有的许多方法采用pipeline的模式,多模块分工进行跨模态知识处理和特征学习,但这种模式下,中间件的性能瓶颈会导致不可逆转的误差传播(Error Cascading)。此外,大多数已有工作都忽略了答案偏见问题——因为长尾效应的存在,真实世界许多答案在模型训练过程中可能不曾出现过(Unseen Answer)。
该工作提出了一种适用于零样本视觉问答(ZS-VQA)的基于知识图谱的掩码机制,更好结合外部知识的同时,一定程度缓解了误差传播对于模型性能的影响。并在原有F-VQA数据集基础上,提供了基于Seen / Unseen答案类别为划分依据的零样本VQA数据集(ZS-F-VQA)。实验表明,其方法可以在该数据集下达到最佳性能,同时还可以显著增强端到端模型在标准F-VQA任务上的性能效果。
人天生就具有强大的领域迁移能力,且这种能力往往不需要很多的样本,甚至仅需一些规则描述,根据过往的经验与知识就可以迅速适应一个新的领域,并对新概念进行认知。基于此假设,作者设计零样本下的外部知识VQA:测试集答案与训练集的答案没有重叠。即,在原有F-VQA数据集基础上,提供以Seen / Unseen答案类别为划分依据的ZS-F-VQA数据集,并提出了一种适用于零样本视觉问答(ZS-VQA)的基于知识图谱的掩码机制。
区别于传统VQA基于分类器的模型设定,本文采取基于空间映射的方法,建立多个特征空间并进行知识分解,同时提出了一种灵活的可作用于任何模型的k mask设定,缓解少样本情况下对于Seen类数据的领域漂移。这提供了一种多模态数据和KG交互的新思路,实验证明在多个模型上可取得稳定的提升,更好地结合外部知识同时缓解误差传播对于模型性能的影响。
新数据集(注意到,原始F-VQA是根据图片进行数据划分的,因此在image上的重叠(overlap)是0,而ZS-F-VQA在answer上重叠为0。):
方法包含两部分。
第一部分,三个特征空间以处理不同分布的信息:实体空间(Object Space)、语义空间(Semantic Space)、知识空间(Knowledge Space)的概念。其中:
实体空间主要处理图像/文本中存在的重点实体与知识库中存在实例的对齐;
语义空间关注视觉/语言的交互模态中蕴含的语义信息,其目的是让知识库中对应关系的表示在独立空间中进行特征逼近。
知识空间让 (问题,图像)组成的pair与答案直接对齐,建模的是间接知识,旨在挖掘多模态融合向量中存在的(潜层)知识。
第二部分是基于知识的答案掩码。
给定输入图像/文本信息得到融合向量后,基于第一部分独立映射的特征空间和给定的超参数Ke / Kr,根据空间距离相似度在实体/语义空间中得到关于实体/关系的映射集,结合知识库三元组信息匹配得到答案候选集。答案候选集作为掩码的依据,在知识空间搜索得到的模糊答案的基础上进行掩码处理,最后进行答案排序。
作者设计了两种掩码类型:硬掩码(hard mask)和软掩码(soft mask),主要作用于答案的判定分数(score),区别在于遮掩分数的多少。作用场景分别为零样本场景和普通场景。零样本背景下领域偏移问题严重,硬掩码约束某种意义上对于答案命中效果的提升远大于丢失正确答案所带来的误差。而普通场景下过高的约束则容易导致较多的信息丢失,收益小于损失。
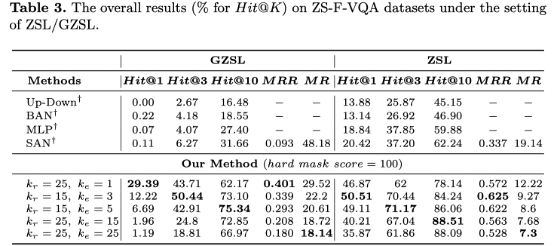
模型在ZSL/GZSL下表现提升显著
case study:

小结:
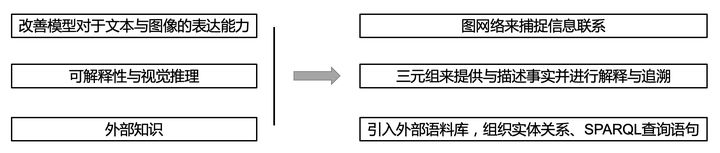
总而言之,形形色色的方法各有千秋。在实际应用中,可以根据不同方法的优劣和实际场景的条件选择合适的VQA模型。目前来说解决VQA问题主要方向主要是三个大方向(改善模型对于文本与图像的表达能力,可解释性与视觉推理,外部知识),其 知识图谱(KG)而言在这三个方向中都有涉及。起到的作用分别对应于:用图网络来捕捉信息联系,通过三元组来提供与描述事实并进行解释与答案追溯,以及引入外部语料库,组织实体关系和spaql查询语句。
此外,现有的模型默认训练集与测试集具有独立同分布的特质,但现实往往不尽如人意,也就是说同分布的假设大概率要打破。正如三位图灵奖大佬最近发表的文章Deep Learning for AI中所强调的核心概念——高层次认知。将现在已经学习的知识或技能重新组合,重构成为新的知识体系,随之也重新构建出了一个新的假想世界(如在月球上开车),这种能力是人类天生就被赋予了的,在因果论中,被称作“反事实”能力。现有的统计学习系统仅仅停留在因果关系之梯的第一层,即观察,观察特征与标签之间的关联,而无法做到更高层次的事情。
零样本领域(ZSL)如何合理利用已有知识?我们普遍认为见过的就是事实,而未见过的就是事实以外的错误(反事实),这显然过于绝对。零样本某种意义上,就可看成是反事实的一种特例。
当然,未来还有许多潜在的方法和应用等待挖掘,欢迎大家补充和交流。
码字不易~ 希望对你能有帮助和启发
转发至:
【论文小综】基于外部知识的VQA(视觉问答) - 知乎
这篇关于【论文小综】基于外部知识的VQA(视觉问答)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








