本文主要是介绍【博客719】时序数据库基石:LSM Tree的Compact策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时序数据库基石:LSM Tree的Compact策略
场景:
为什么Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。
在Compact策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
- 读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
- 写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
- 空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
LSM结构
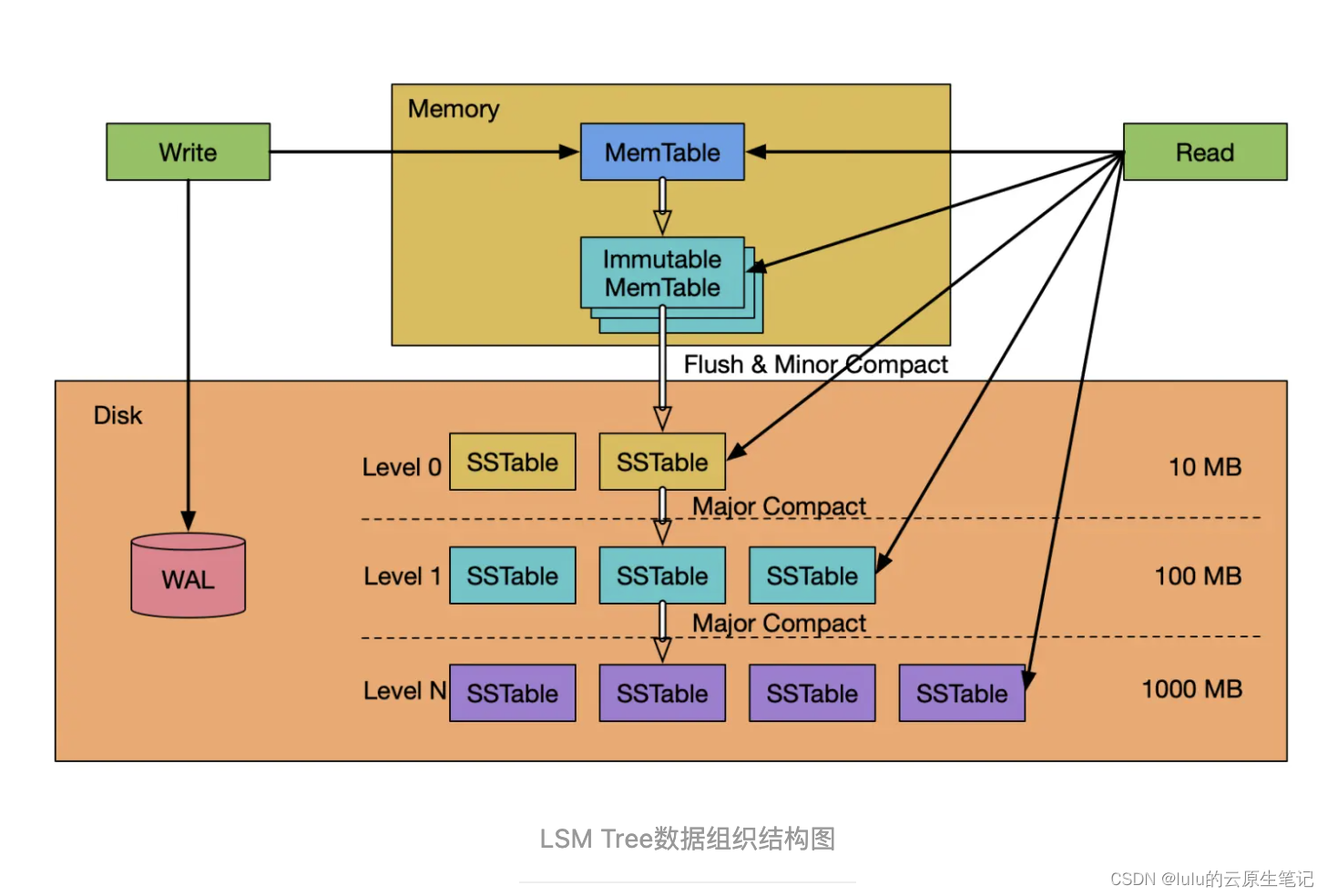
上图中,WAL(Write Ahead LOG)严格来说本身并不是LSM Tree数据结构的一部分,但是实际系统中,WAL是数据库不可或缺的一部分,把WAL包括进来才能更准确的理解LSM Tree。有些场景下性能更重要时,也可以去掉WAL这部分,用一致性来换可用性,如:victoriametrics项目就是。
LSM Tree的数据由两部分组成:内存部分和持久到磁盘中的部分。内存部分由一个MemTable和一个或多个Immutable MemTable组成。磁盘中的部分由分布在多个level的SSTable组成。level级数越小(level 0)表示处于该level的SSTable越新,level级数越大(level 1…level N)表示处于该level的SSTable越老,最大级数(level N)大小由系统设定。在本图中,磁盘中最小的级数为level 0,也有的系统把内存中的Immutable MemTable定义为level 0,而磁盘中的数据从Level 1开始,这只是level定义的不同,并不影响系统的工作流程和对系统的理解。
-
WAL的结构和作用跟其他数据库一样,是一个只能在尾部以Append Only方式追加记录的日志结构文件,它用来当系统崩溃重启时重放操作,使MemTable和Immutable MemTable中未持久化到磁盘中的数据不会丢失。
-
MemTable往往是一个跳表(Skip List)组织的有序数据结构(当然,也可以是有序数组或红黑树等二叉搜索树),跳表既支持高效的动态插入数据,对数据进行排序,也支持高效的对数据进行精确查找和范围查找。
-
SSTable一般由一组数据block和一组元数据block组成。元数据block存储了SSTable数据block的描述信息,如索引、BloomFilter、压缩、统计等信息。因为SSTable是不可更改的,且是有序的,索引往往采用二分法数组结构就可以了。为了节省存储空间和提升数据块block的读写效率,可以对数据block进行压缩。
Compact策略
LSM Tree虽然数据写入速度非常快,但是存在空间放大和读放大的现象,这些现象如果不进行抑制,可能导致读性能的极端恶化和空间占用过于膨胀,最终导致LSM Tree在实际生产环境中不可用。SSTable合并就是用来缓解这种现象的。LSM Tree支持将多个SSTable合并为一个新的SSTable,合并过程中,会删除旧的重叠数据,并真正物理删除被删除的数据,也减少了SSTable的数量,这样消除了空间放大,同时也提升了数据查找的性能。但是,合并需要将合并涉及的SSTable读入内存,并把合并后产生的新的SSTable写入磁盘,会增加磁盘IO和CPU的消耗,这种写入磁盘的数据量大于实际数据量现象成为写放大(write amplification),当然合并也意味着读放大。由此可见,SSTable合并是一把双刃剑,有利也有弊,需要合理利用。
SSTable合并分为minor compaction和major compaction:
- minor compaction是指将内存中的Immutable MemTable内容flush到磁盘中形成SSTable时进行的数据处理过程
- major compaction则是指相邻的两级level将数字小level(如level 0)的SSTable合并入数字大level(如level 1)的SSTable中的过程。
SSTable合并其实就是在空间放大、写放大、读放大几个相互制约的因素间寻求平衡,不同的应用场景需要重点优化解决某个问题
从而形成了几种典型的SSTable合并策略:
1、leveled compaction:
leveled compaction为每层level的SSTable数据总大小设置一个阈值,level数越大,阈值设置的也越大,比如level0阈值为10MB、level1阈值设置为100MB、level2阈值设置为1000MB。当某level层的数据总量大小超过设置的阈值时,则选取一个SSTable合并入高一级level层的一个或多个SSTable中。高level层涉及的SSTable的选择处决于数据的分布,以合并后高level层中的所有SSTable数据是整体有序的为准(one sorted run),也就是说数据在同一层中不存在重叠的现象。
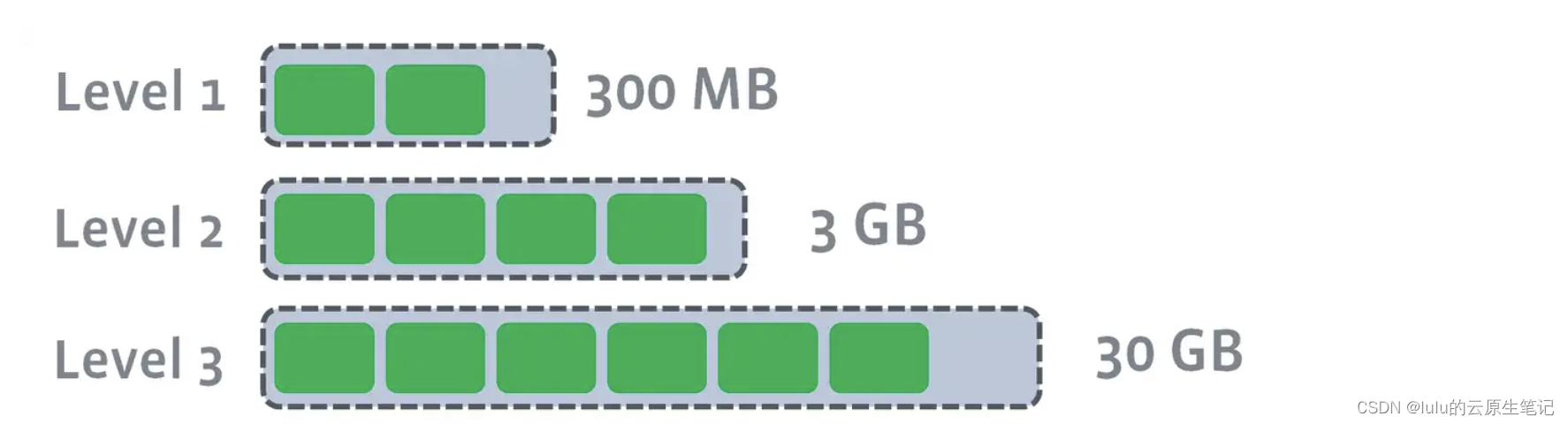
leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同
当L1的总大小超过L1本身大小限制:
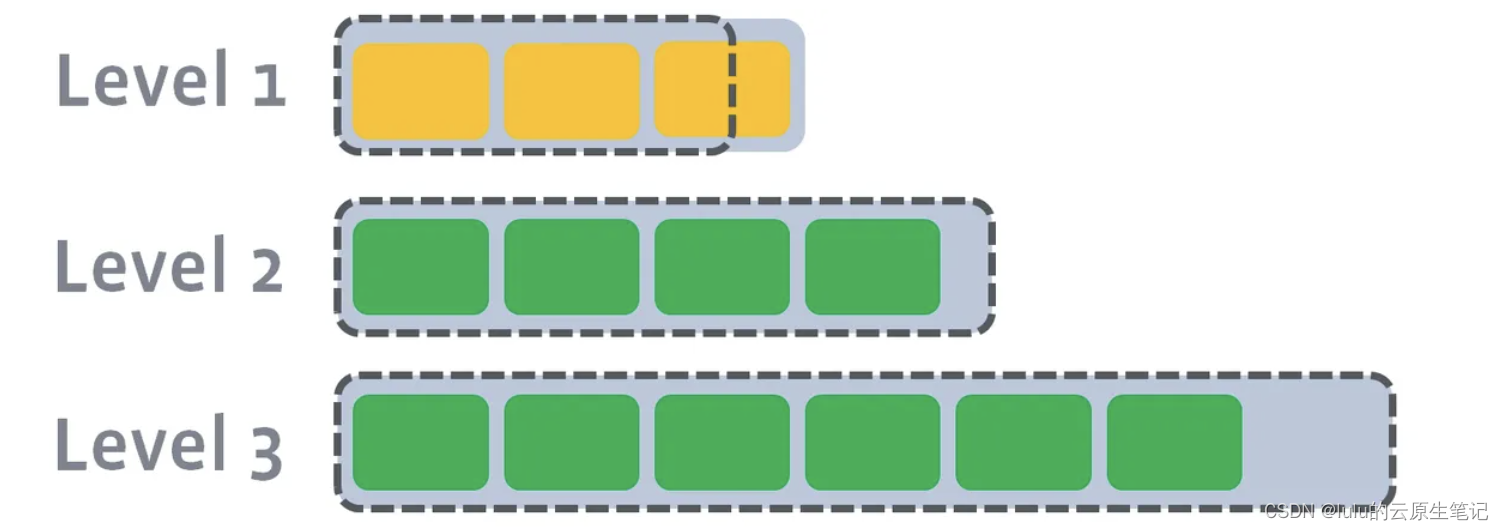
此时会从L1中选择至少一个文件,然后把它跟L2有交集的部分(非常关键)进行合并。生成的文件会放在L2:
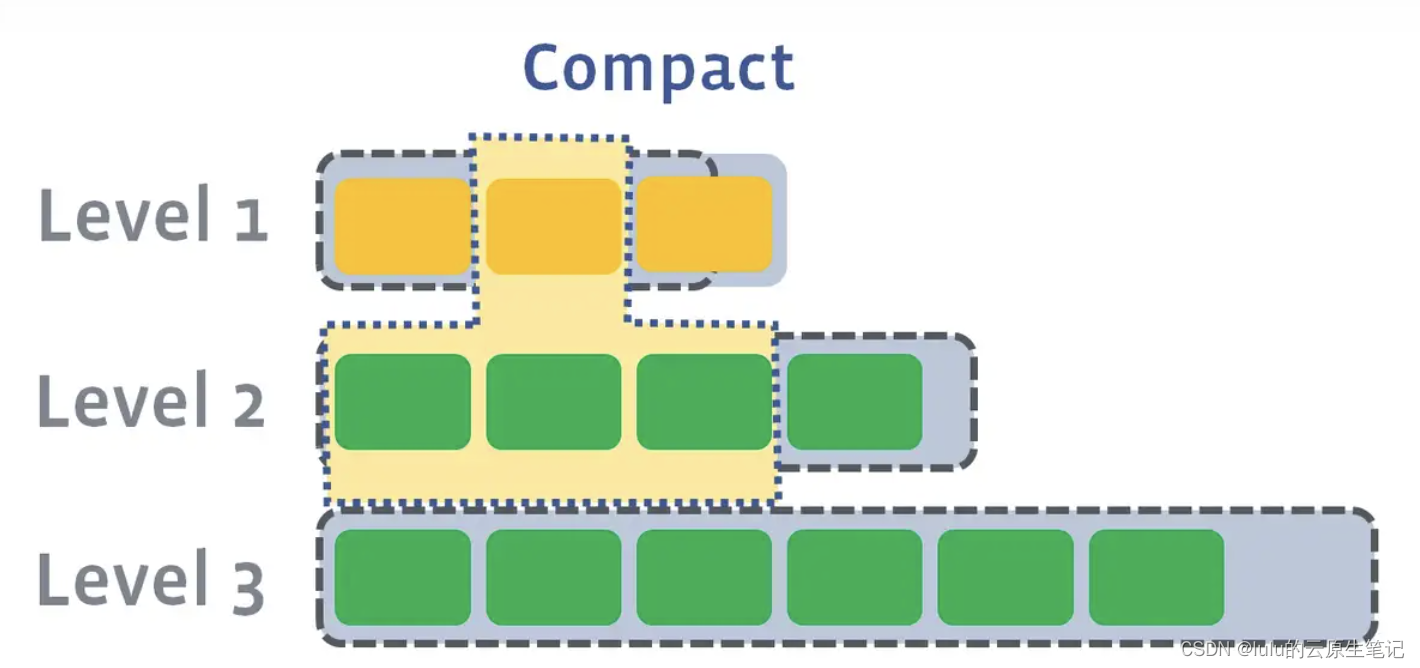
此时L1第二SSTable的key的范围覆盖了L2中前三个SSTable,那么就需要将L1中第二个SSTable与L2中前三个SSTable执行Compact操作。
如果L2合并后的结果仍旧超出L5的阈值大小,需要重复之前的操作 —— 选至少一个文件然后把它合并到下一层:
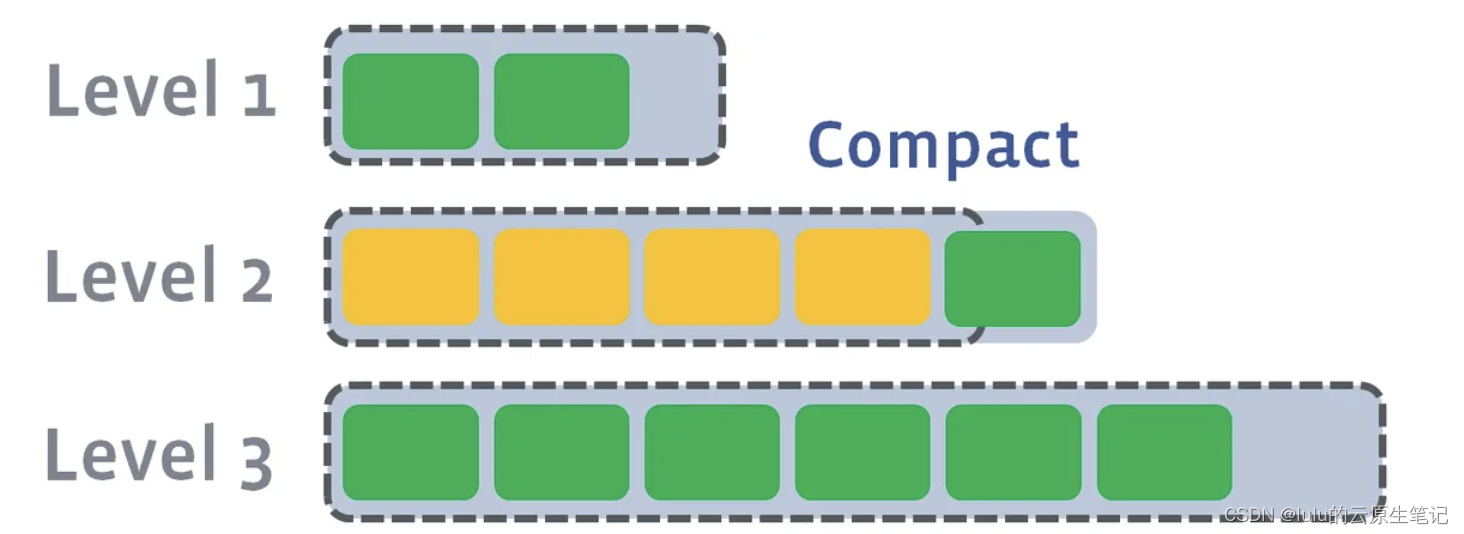
多个不相干的合并是可以并发进行的:
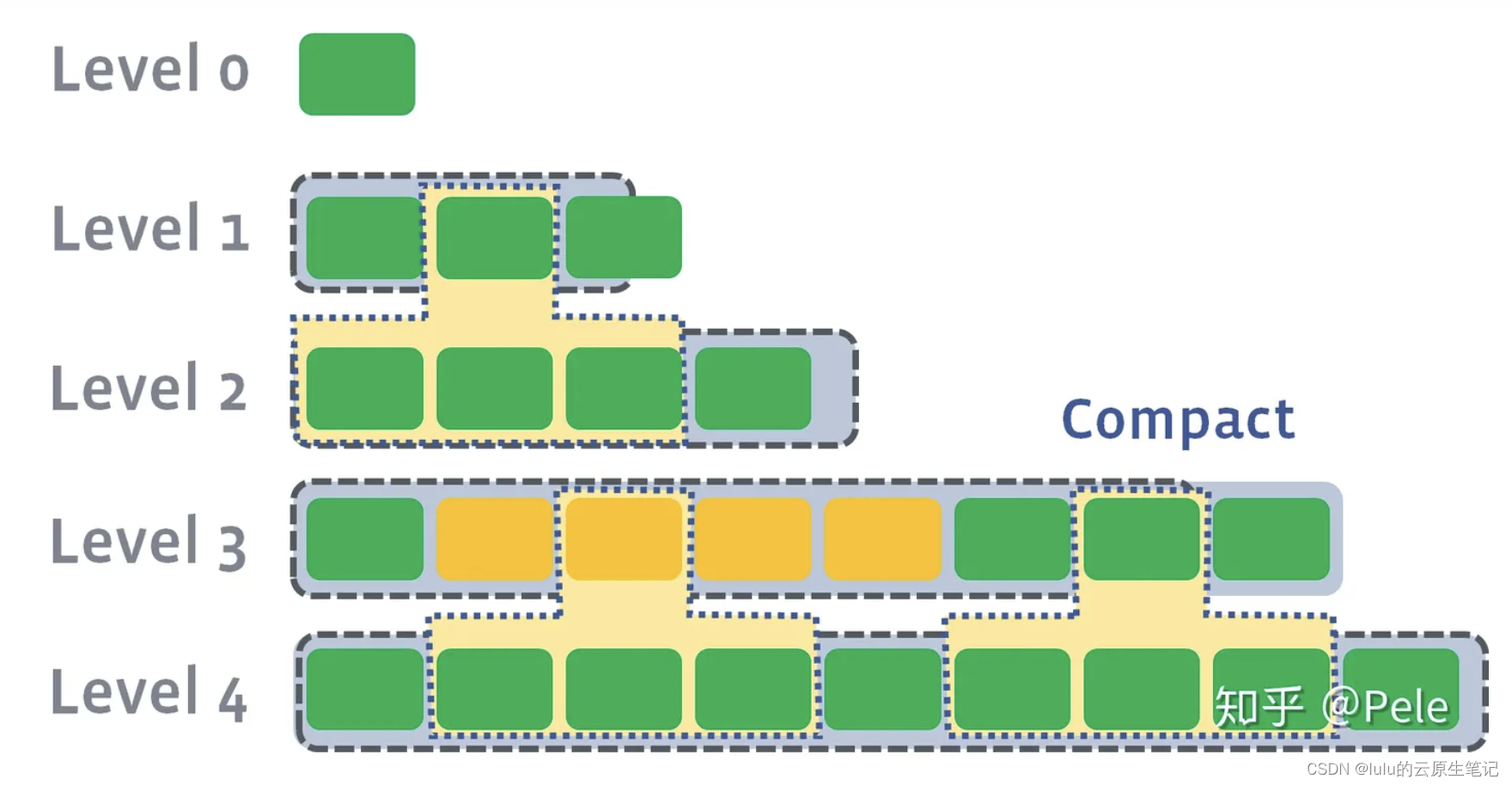
leveled策略相较于size-tiered策略来说,每层内key是不会重复的,即使是最坏的情况,除开最底层外,其余层都是重复key,按照相邻层大小比例为10来算,冗余占比也很小。因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。
2、tiered compaction:
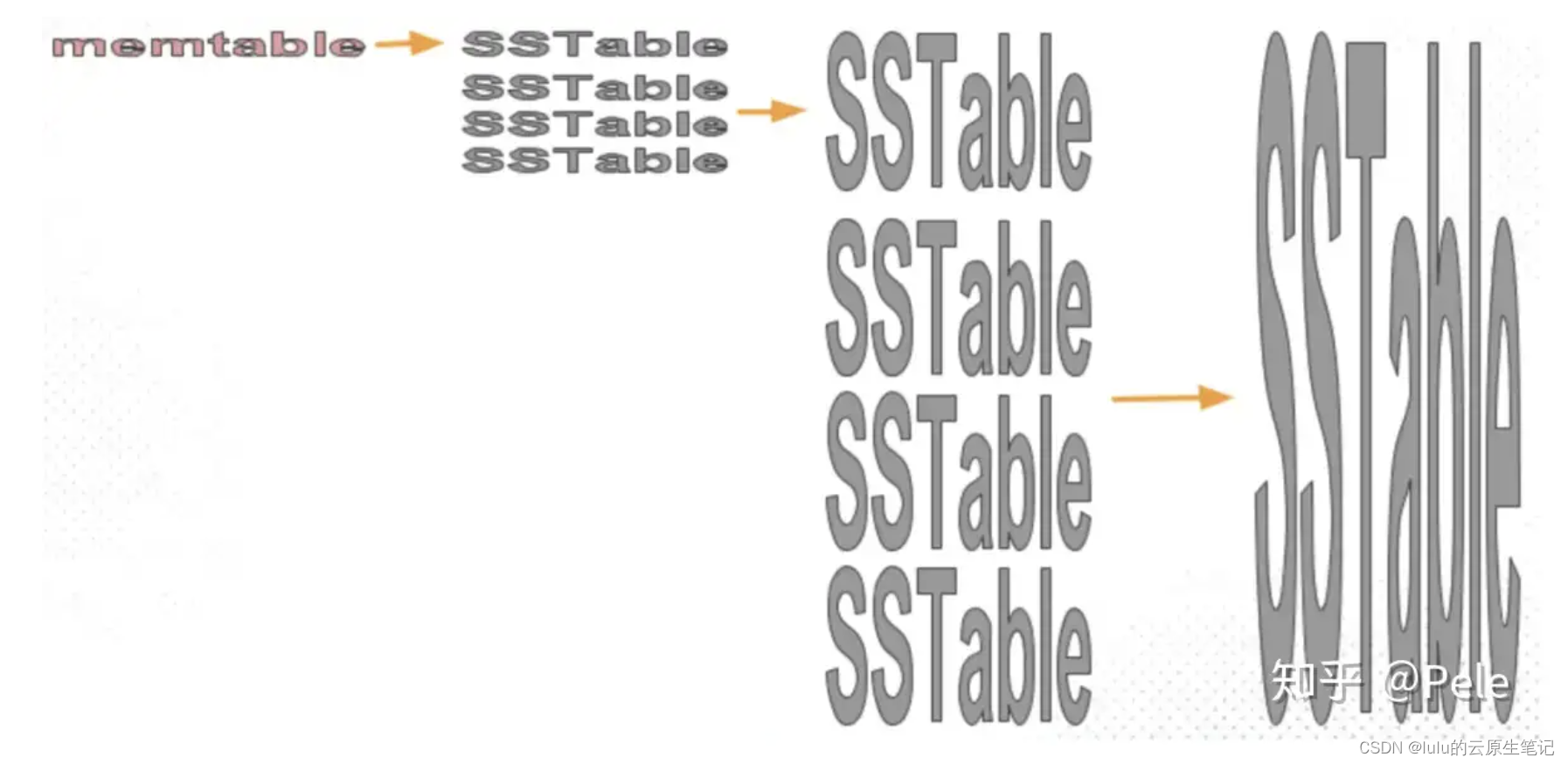
size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录
3、leveled-tiered mixed compaction:
结合leveled compaction和tiered compaction的优势,在部分level之间采用tiered compaction,在另一部分level之间采用leveled compaction。
RocksDB的leveled Compaction采用的是leveled-tiered mixed compaction策略。数据从Immutable MemTable flush到level 0时采用的是tiered compaction,也就是说level0中是存在重叠数据的。level0到levelN之间采用leveld compaction策略。
4、FIFO compaction
FIFO compaction在磁盘中只有一个level层级,SSTable按生成的时间顺序排列,删除过早生成的SSTable。
FIFO compaction适合时间序列数据,一旦生成数据就不会再修改。
Cassandra的TWCS(Time Window Compaction Strategy)、DTCS(Date Tiered Compaction Strategy)和RocksDB的FIFO compaction使用的是FIFO类型的合并策略。
这篇关于【博客719】时序数据库基石:LSM Tree的Compact策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






