本文主要是介绍LLMs之BELLE:BELLE(一款能够帮到每一个人的中文LLM引擎)的简介(基于Alpaca架构+中文优化+考察词表扩充/数据质量/数据语言分布/数据规模的量化分析)、使用方法、案例应用之详细攻略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs之BELLE:BELLE(一款能够帮到每一个人的中文LLM引擎)的简介(基于Alpaca架构+中文优化+考察词表扩充/数据质量/数据语言分布/数据规模的量化分析)、使用方法、案例应用之详细攻略
导读:2023年4月8日,BELLE(Be Everyone's Large Language model Engine),项目目标是促进中文对话大模型开源社区的发展,愿景是成为能够帮到每一个人的LLM Engine。是开源中文对话大模型 70 亿~130亿参数,目标是促进中文对话大模型开源社区的发展,愿景是成为能够帮到每一个人的 LLM Engine。
BELLE基于斯坦福的 Alpaca架构,但进行了中文优化,并对生成代码进行了一些修改,不仅如此,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。BELLE 项目的研究方向着眼于提升中文指令调优模型的指令跟随、指令泛化效果,降低模型训练和研究工作的门槛,让更多人都能感受到大语言模型带来的帮助。
相比如何做好大语言模型的预训练,BELLE更关注如何在开源预训练大语言模型的基础上,帮助每一个人都能够得到一个属于自己的、效果尽可能好的具有指令表现能力的语言模型,降低大语言模型、特别是中文大语言模型的研究和应用门槛。为此,BELLE项目会持续开放指令训练数据、相关模型、训练代码、应用场景等,也会持续评估不同训练数据、训练算法等对模型表现的影响。
>> 基于Meta LLaMA实现调优的模型:BELLE-LLaMA-7B-0.6M-enc , BELLE-LLaMA-7B-2M-enc , BELLE-LLaMA-7B-2M-gptq-enc , BELLE-LLaMA-13B-2M-enc , BELLE-on-Open-Datasets 以及基于LLaMA做了中文词表扩充的预训练模型BELLE-LLaMA-EXT-7B。
>> 基于Alpaca框架(中文优化+ChatGPT产指令调优数据集)+4bit量化+Deepspeed-Chat+finetune+LoRA+GPT-4打分+8*A100-40G:一个1k+的测试集合,和对应打分prompt。包含多个类别,采用GPT-4或者ChatGPT打分。同时提供了一个打分的网页,方便针对单个case使用。
目录
BELLE的简介
1、BELLE(一款能够帮到每一个人的中文大型语言模型引擎)的概述
2、近期更新内容
3、相关论文
《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation朝着更好的中文指令模仿语言模型:探究训练数据与评估的影响》的翻译与解读
《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model中文指令模仿大语言模型全参调优与LoRA调优对比研究》的翻译与解读
4、核心技术
(1)、扩展了LLaMA的词汇表,并在34亿个中文词汇上进行了二次预训练
(2)、基于ChatGPT产生指令训练数据的三大方式
(3)、开源聊天模型综合评估及其实验结果—探究训练数据类别对模型性能的影响:词表扩充、数据质量、数据语言分布、数据规模等因素
(4)、基于LLaMA基础模型,比较了全参数微调和基于LoRA的调优方法,建议在已完成了指令学习的模型的基础上针对特定任务做LoRA的自适应训练
BELLE的安装
1、配置环境
T1、利用Docker镜像部署安装
T2、conda或pip安装
2、模型下载及其格式转换
2.1、下载官方模型权重
2.2、模型权重转换为hf格式
(1)、facebook官方LLaMA权重转为hf格式
(2)、BELLE-LLaMA转为hf格式
3、合并词表:扩充LLaMA模型的原始中文词表,参考merge_tokenizers.py
LLMs之BELLE:源码解读(merge_tokenizers.py文件)训练和合并两个不同的SentencePiece分词模型—使用SentencePiece库来训练一个名为belle的BPE分词器→加载两个现有的分词器模型→合并词汇表→保存合并后的模型作为新的分词器模型
4、模型微调
4.1、准备数据集
(0)、生成中文数据集
含175个种子任务zh_seed_tasks.jsonl示例
LLMs之BELLE:源码解读(generate_instruction.py文件)让机器自动生成大量指令数据并避免生成重复内容—利用GPT-3模型生成自我指导的任务指令→并根据相似度筛选出合适的指令→保存到文件中→用于NLP的训练与评估
(1)、指令微调(SFT)数据集
LLMs之BELLE:源码解读(convert_to_conv_data.py文件)数据格式转换——将原始指令格式的数据文件{单轮对话任务,instruction+input+output}转换成标准的人机对话格式的数据文件{多轮对话任务,id+conversations[人类+助手]]}
(2)、继续预训练(PT)数据格式
4.2、模型训练
(1)、两大训练场景:继续预训练(run_pt.sh)、指令微调(run_sft.sh)
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯度检查点/flash_attention)→加载训练和验证数据集→模型训练
(2)、微调的三种方式
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯度检查点/flash_attention)→加载训练和验证数据集→模型训练
T1、基于单机多卡—全量参数微调:
T2、基于单机多卡—LoRA微调
合并LoRA权重
T3、多机多卡训练:以2台8卡为例
5、模型推理:验证模型生成文本的效果
T1、CLI:命令脚本实现
T2、WebUI:基于gradio的交互式web界面交互实现
T3、加速推理—并行推理
T4、加速推理—基于ZeRO的推理
T4.1、批量推理(推荐)
T4.2、推理后端(前后端分离)
T5、Colab:BELLE模型在Colab推理的示例:colab上面可运行的推理代码
6、模型量化:基于GPTQ为LLaMa量化的开源实现,将其应用于Belle模型
7、RLHF训练流程
T1、PPO训练
(1)、奖励模型
LLMs之BELLE:源码解读(ppo_train.py文件)训练一个基于强化学习的自动对话生成模型—解析命令行参数→加载数据集(datasets库)→初始化模型分词器和PPOConfig配置参数(trl库)→模型训练(accelerate分布式训练+DeepSpeed推理加速,生成对话→计算奖励【评估生成质量】→执行PPO算法更新【改善生成文本的质量】)→模型保存之详细攻略
(2)、PPO
T2、DPO训练
LLMs之BELLE:源码解读(dpo_train.py文件)训练一个基于强化学习的自动对话生成模型(DPO算法微调预训练语言模型)—解析命令行参数与初始化→加载数据集(json格式)→模型训练与评估之详细攻略
BELLE的使用方法
1、使用App在设备端本地运行4bit量化的BELLE-7B模型
BELLE的简介
1、BELLE(一款能够帮到每一个人的中文大型语言模型引擎)的概述
| 地址 | GitHub地址:https://github.com/LianjiaTech/BELLE 论文地址: 《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation》 《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model》 |
| 时间 | 时间:2023年4月 |
| 作者 | BELLE Group |
2、近期更新内容
- [2023/05/14] 开放BELLE-LLaMA-EXT-13B,在LLaMA-13B的基础上扩展中文词表,并在400万高质量的对话数据上进行训练。
- [2023/05/11] BELLE/data/10M中,新加350万条生成多样化指令任务数据,包括单轮和多轮对话train_3.5M_CN。
- [2023/04/19] 开放了其中一篇论文中的的相关模型:包括在LLaMA7B基础上增量预训练扩展中文词表的模(详见BelleGroup/BELLE-LLaMA-EXT-7B),以及基于多样化开源数据训练后的LLaMA-7B模型(详见BelleGroup/BELLE-on-Open-Datasets)。
- [2023/04/18] 更新了train代码,详见BELLE/train,集成了Deepspeed-Chat,提供了相关的docker
- [2023/04/18] 更新了两篇最新论文工作,对比了不同方式产生的训练数据、不同训练方法(LoRA, finetune)对效果的影响
- [2023/04/12] 发布了ChatBELLE App,基于llama.cpp和Flutter,实现跨平台的BELLE-7B离线模型实时交互。
- [2023/04/11] 更新了一个人工精校的eval集合,大约一千多条
- [2023/04/08] BELLE/data/10M中,新加40万条生成的给定角色的多轮对话Generated Chat,新加200万条生成多样化指令任务数据train_2M_CN。
3、相关论文
《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation朝着更好的中文指令模仿语言模型:探究训练数据与评估的影响》的翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2304.07854 |
| 时间 | 时间:2023年4月16日 |
| Recently, significant public efforts have been directed towards developing low-cost models with capabilities akin to ChatGPT, thereby fostering the growth of open-source conversational models. However, there remains a scarcity of comprehensive and in-depth evaluations of these models' performance. In this study, we examine the influence of training data factors, including quantity, quality, and linguistic distribution, on model performance. Our analysis is grounded in several publicly accessible, high-quality instruction datasets, as well as our own Chinese multi-turn conversations. We assess various models using a evaluation set of 1,000 samples, encompassing nine real-world scenarios. Our goal is to supplement manual evaluations with quantitative analyses, offering valuable insights for the continued advancement of open-source chat models. Furthermore, to enhance the performance and training and inference efficiency of models in the Chinese domain, we extend the vocabulary of LLaMA - the model with the closest open-source performance to proprietary language models like GPT-3 - and conduct secondary pre-training on 3.4B Chinese words. We make our model, data, as well as code publicly available. | 最近,公众已经付出了大量努力,开发具有ChatGPT类似能力的低成本模型,从而促进了开源对话模型的发展。然而,这些模型性能的全面深入评估仍然很少。在本研究中,我们考察了训练数据因素(包括数量、质量和语言分布)对模型性能的影响。我们的分析基于几个公开可获取的高质量指令数据集,以及我们自己的中文多轮对话数据。我们使用一个包含9个真实场景的评估集对各种模型进行评估,该集合包含1000个样本。我们的目标是通过定量分析来补充手动评估,为开源对话模型的持续进展提供有价值的见解。此外,为了增强模型在中文领域的性能、训练和推理效率,我们扩展了LLaMA的词汇量(LLaMA是与GPT-3等专有语言模型最接近的开源模型),并在34亿中文词汇上进行了辅助预训练。我们将我们的模型、数据和代码公开提供。 |
| In conclusion, this study addresses the grow-ing need for comprehensive evaluations of open-source conversational models by investigating the influence of various training data factors, such as quantity, quality, and linguistic distribution. By utilizing publicly accessible high-quality in-struction datasets and Chinese multi-turn conver-sations, we assess different models on a evaluation set of 1,000 samples across nine real-world scenar-ios. We also conclude several challenges of build-ing a comprehensive evaluation dataset and argue the necessity of prioritizing the development of such evaluation set. Moreover, this study extends the vocabulary of LLaMA and conducts secondary pre-training with 3.4B Chinese words to enhance its performance and efficiency in the Chinese do-main. This results in a 60% reduction in train-ing and inference time without sacrificing perfor-mance. By making the model, data, and code pub-licly available, this research contributes to the on-going efforts of the open-source community to de-velop more accessible and efficient conversational models especially for Chinese. | 总之,本研究通过研究训练数据的数量、质量和语言分布等各种因素对开源对话模型进行全面评估,以满足日益增长的这方面需求。我们利用公开可获取的高质量指令数据集和中文多轮对话数据,在包含9个真实场景的1000个样本的评估集上评估了不同的模型。我们还总结了构建全面评估数据集的几个挑战,并提出了优先发展这种评估集的必要性。此外,本研究扩展了LLaMA的词汇量,并在34亿中文词汇上进行了辅助预训练,以提高其在中文领域的性能和效率。这使得训练和推理时间减少了60%,而不会牺牲性能。通过公开提供模型、数据和代码,这项研究为开源社区不断努力开发更易于访问和高效的对话模型,特别是针对中文,做出了贡献。 |
《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model中文指令模仿大语言模型全参调优与LoRA调优对比研究》的翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2304.08109 |
| 时间 | 时间:2023年4月17日 |
| Recently, the instruction-tuning of large language models is a crucial area of research in the field of natural language processing. Due to resource and cost limitations, several researchers have employed parameter-efficient tuning techniques, such as LoRA, for instruction tuning, and have obtained encouraging results In comparison to full-parameter fine-tuning, LoRA-based tuning demonstrates salient benefits in terms of training costs. In this study, we undertook experimental comparisons between full-parameter fine-tuning and LoRA-based tuning methods, utilizing LLaMA as the base model. The experimental results show that the selection of the foundational model, training dataset scale, learnable parameter quantity, and model training cost are all important factors. We hope that the experimental conclusions of this paper can provide inspiration for training large language models, especially in the field of Chinese, and help researchers find a better trade-off strategy between training cost and model performance. To facilitate the reproduction of the paper's results, the dataset, model and code will be released. | 最近,在自然语言处理领域,对大型语言模型进行指令微调是一项重要的研究领域。由于资源和成本的限制,一些研究人员采用了参数高效的微调技术,如LoRA,进行指令微调,并取得了令人鼓舞的结果。与全参数微调相比,LoRA-based微调在训练成本方面表现出明显的优势。在本研究中,我们使用LLaMA作为基础模型,对全参数微调和LoRA-based微调方法进行了实验比较。实验结果显示,基础模型的选择、训练数据集规模、可学习参数数量和模型训练成本都是重要因素。我们希望本文的实验结论能够为训练大型语言模型,特别是在中文领域,提供启示,并帮助研究人员找到更好的训练成本和模型性能之间的权衡策略。为了便于复现本文的结果,数据集、模型和代码将被发布。 |
| In this article, we conducted an experimental com-parison between full-parameter fine-tuning and LoRA-based tuning methods using LLaMA as the base model. We also explored the impact of differ-ent amounts of training data and model parameters on the effectiveness of LoRA-based tuning. From the experimental results comparison, some inter-esting ideas can observed: (1)、The choice of the base model has a signif-icant impact on the effectiveness of LoRA-based tuning. Comparing LLaMA-7B+LoRA(0.6M) and LLaMA-7B+FT(0.6M), as well as LLaMA- 7B+LoRA(2M) and LLaMA-7B+FT(2M), it is evident that LoRA-based tuning on a base model that has not undergone instruction tun-ing has limited effectiveness and is far less ef-fective than full-parameter fine-tuning (averag-ing 10 points lower). However, by compar-ing LLaMA-7B+FT(2M)+FT(math_0.25M) and LLaMA-7B+FT(2M)+LoRA(math_0.25M), it can be seen that LoRA-based tuning on a model that has undergone instruction tuning can achieve com-parable results to fine-tuning. This indicates that the choice of the base model is crucial to the ef-fectiveness of the LoRA-based tuning method. (2)、Increasing the amount of training data can continuously improve the model’s effectiveness. Comparing LLaMA-7B+LoRA(0.6M), LLaMA- 7B+LoRA(2M), and LLaMA-7B+LoRA(4M) shows that as the amount of training data in-creases, the model’s effectiveness improves (an average of approximately 2 points improvement for every doubling of data). (3)、LoRA-based tuning benefits from the number of model parameters. Comparing LLaMA- 7B+LoRA(4M) and LLaMA-13B+LoRA(2M) shows that the number of model parameters has a greater impact on the effectiveness of LoRA-based tuning than the amount of training data. | 在本文中,我们使用LLaMA作为基础模型,进行了全参数微调和LoRA-based微调方法的实验比较。我们还探讨了不同数量的训练数据和模型参数对LoRA-based微调效果的影响。通过实验结果比较,我们得出了一些有趣的观点: (1)、基础模型的选择对LoRA-based微调的效果有显著影响。比较LLaMA-7B+LoRA(0.6M)和LLaMA-7B+FT(0.6M),以及LLaMA-7B+LoRA(2M)和LLaMA-7B+FT(2M),可以明显看出,在未经过指令微调的基础模型上进行LoRA-based微调的效果有限,远不如全参数微调(平均低10个点)。然而,通过比较LLaMA-7B+FT(2M)+FT(math_0.25M)和LLaMA-7B+FT(2M)+LoRA(math_0.25M),可以看出,在经过指令微调的模型上进行LoRA-based微调可以达到与全参数微调相当的结果。这表明基础模型的选择对LoRA-based微调方法的有效性至关重要。 (2)、增加训练数据量可以不断提高模型的效果。比较LLaMA-7B+LoRA(0.6M),LLaMA-7B+LoRA(2M)和LLaMA-7B+LoRA(4M)可以发现,随着训练数据量的增加,模型的效果也在改善(每倍数据增加平均约2个点)。 (3)、LoRA-based微调受益于模型参数的数量。比较LLaMA-7B+LoRA(4M)和LLaMA-13B+LoRA(2M)可以看出,模型参数的数量对LoRA-based微调的有效性影响更大,而不是训练数据量。 |
4、核心技术
(1)、扩展了LLaMA的词汇表,并在34亿个中文词汇上进行了二次预训练
为了推动开源大语言模型的发展,大家投入了大量精力开发能够类似于ChatGPT的低成本模型。 首先,为了提高模型在中文领域的性能和训练/推理效率,我们进一步扩展了LLaMA的词汇表,并在34亿个中文词汇上进行了二次预训练。
(2)、基于ChatGPT产生指令训练数据的三大方式
此外,目前可以看到基于ChatGPT产生的指令训练数据方式有:
>> 1)参考Alpaca基于GPT3.5得到的self-instruct数据;
>> 2)参考Alpaca基于GPT4得到的self-instruct数据;
>> 3)用户使用ChatGPT分享的数据ShareGPT。
(3)、开源聊天模型综合评估及其实验结果—探究训练数据类别对模型性能的影响:词表扩充、数据质量、数据语言分布、数据规模等因素
在这里,我们着眼于探究训练数据类别对模型性能的影响。具体而言,我们考察了训练数据的数量、质量和语言分布等因素,以及我们自己采集的中文多轮对话数据,以及一些公开可访问的高质量指导数据集。
为了更好的评估效果,我们使用了一个包含一千个样本和九个真实场景的评估集来测试各种模型,同时通过量化分析来提供有价值的见解,以便更好地促进开源聊天模型的发展。
这项研究的目标是填补开源聊天模型综合评估的空白,以便为这一领域的持续进步提供有力支持。
实验结果如下:
| Factor | Base model | Training data | Score_w/o_others |
| 词表扩充 | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B | zh(alpaca-3.5&4) + sharegpt | 0.652 | |
| 数据质量 | LLaMA-7B-EXT | zh(alpaca-3.5) | 0.642 |
| LLaMA-7B-EXT | zh(alpaca-4) | 0.693 | |
| 数据语言分布 | LLaMA-7B-EXT | zh(alpaca-3.5&4) | 0.679 |
| LLaMA-7B-EXT | en(alpaca-3.5&4) | 0.659 | |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 | |
| LLaMA-7B-EXT | en(alpaca-3.5&4) + sharegpt | 0.668 | |
| 数据规模 | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt + BELLE-0.5M-CLEAN | 0.762 | |
| - | ChatGPT | - | 0.824 |
其中BELLE-0.5M-CLEAN是从230万指令数据中清洗得到0.5M数据,其中包含单轮和多轮对话数据,和之前开放的0.5M数据不是同一批数据。
需要强调指出的是:通过案例分析,我们发现我们的评估集在全面性方面存在局限性,这导致了模型分数的改善与实际用户体验之间的不一致。构建一个高质量的评估集是一个巨大的挑战,因为它需要在保持平衡难易程度的同时,包含尽可能多样的使用场景。如果评估样本主要都过于困难,那么所有模型的表现将会很差,使得辨别各种训练策略的效果变得具有挑战性。相反,如果评估样本都相对容易,评估将失去其比较价值。此外,必须确保评估数据与训练数据保持独立。 基于这些观察,我们谨慎地提醒不要假设模型仅通过在有限数量的测试样本上获得良好结果就已经达到了与ChatGPT相当的性能水平。我们认为,优先发展全面评估集具有重要意义。
(4)、基于LLaMA基础模型,比较了全参数微调和基于LoRA的调优方法,建议在已完成了指令学习的模型的基础上针对特定任务做LoRA的自适应训练
为了实现对大语言模型的指令调优,受限于资源和成本,许多研究者开始使用参数高效的调优技术,例如LoRA,来进行指令调优,这也取得了一些令人鼓舞的成果。 相较于全参数微调,基于LoRA的调优在训练成本方面展现出明显的优势。 在这个研究报告中,我们选用LLaMA作为基础模型,对全参数微调和基于LoRA的调优方法进行了实验性的比较。
实验结果揭示,选择合适的基础模型、训练数据集的规模、可学习参数的数量以及模型训练成本均为重要因素。
我们希望本文的实验结论能对大型语言模型的训练提供有益的启示,特别是在中文领域,协助研究者在训练成本与模型性能之间找到更佳的权衡策略。 实验结果如下:
| Model | Average Score | Additional Param. | Training Time (Hour/epoch) |
|---|---|---|---|
| LLaMA-13B + LoRA(2M) | 0.648 | 28M | 8 |
| LLaMA-7B + LoRA(4M) | 0.624 | 17.9M | 11 |
| LLaMA-7B + LoRA(2M) | 0.609 | 17.9M | 7 |
| LLaMA-7B + LoRA(0.6M) | 0.589 | 17.9M | 5 |
| LLaMA-7B + FT(2M) | 0.710 | - | 31 |
| LLaMA-7B + LoRA(4M) | 0.686 | - | 17 |
| LLaMA-7B + FT(2M) + LoRA(math_0.25M) | 0.729 | 17.9M | 3 |
| LLaMA-7B + FT(2M) + FT(math_0.25M) | 0.738 | - | 6 |
其中的score是基于本项目集目前开放的1000条评估集合得到。
其中LLaMA-13B + LoRA(2M) 代表了一个使用LLaMA-13B作为基础模型和LoRA训练方法,在2M指令数据上进行训练的模型。而LLaMA-7B + FT(2M) 代表了一个使用全参数微调进行训练的模型。
LLaMA-7B + FT(2M) + LoRA(math_0.25M) 代表了一个在0.25M数学指令数据上,以LLaMA-7B + FT(2M)作为基础模型并使用LoRA训练方法进行训练的模型。LLaMA-7B + FT(2M) + FT(math_0.25M) 代表了一个使用增量全参数微调进行训练的模型。关于训练时间,所有这些实验都是在8块NVIDIA A100-40GB GPU上进行的。
其中的math_0.25M是开放的0.25M数学数据库。在实验过程中,根据我们的评估(详见论文),我们的模型在数学任务上表现不佳,得分大多低于0.5。
为了验证 LoRA 在特定任务上的适应能力,我们使用增量0.25M数学数据集(math_0.25M)来调整指令遵循的大型语言模型(我们选择LLaMA-7B+FT(2M)作为基础模型)。作为对比,我们使用了学习速率为5e-7的增量微调方法,并进行了2个时期的训练。因此,我们得到了两个模型,一个是LLaMA-7B+FT(2M)+LoRA(math_0.25M),另一个是LLaMA-7B+FT(2M)+FT(math_0.25M)。
从实验结果可以看出,增量微调仍然表现更好,但需要更长的训练时间。LoRA和增量微调都提高了模型的整体性能。从附录中的详细数据可以看出,LoRA和增量微调都在数学任务中显示出显著的改进,而只会导致其他任务的轻微性能下降。具体而言,数学任务的表现分别提高到了0.586和0.559。
可以看到:
>> 1) 选择基础模型对于 LoRA 调整的有效性具有显著影响;
>> 2)增加训练数据量可以持续提高LoRA模型的有效性;
>> 3)LoRA 调整受益于模型参数的数量。
对于LoRA方案的使用,我们建议可以在已经完成了指令学习的模型的基础上针对特定任务做LoRA的自适应训练。
同样地,该论文中的相关模型也会尽快开放在本项目中。
BELLE的安装
1、配置环境
T1、利用Docker镜像部署安装
| 简介 | 我们提供了一个完整可运行的Docker镜像,Dockerfile写在docker文件夹下。考虑到build存在一定的困难,我们提供了镜像下载,你可以使用下面命令从dockerhub拉取我们的镜像,然后在镜像中运行代码, docker环境说明:https://github.com/LianjiaTech/BELLE/blob/main/docker/README.md 注意:上述挂载的目录必须是绝对路径 |
| 拉取docker镜像 | sudo docker pull tothemoon/belle:latest |
| clone BELLE仓库 | git clone https://github.com/LianjiaTech/BELLE.git |
| 将BELLE目录挂载 | |
| 将huggingface目录挂载 | 将huggingface目录挂载。其中huggingface_models代表预训练模型的保存路径,该目录下存放所有需要的预训练语言模型,如llama-7b, bloomz-7b1-mt等 sudo docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \ --network host \ --privileged \ [--env https_proxy=$https_proxy \] [--env http_proxy=$http_proxy \] [--env all_proxy=$all_proxy \] --env HF_HOME=$hf_home \ -it [--rm] \ --name belle \ -v $belle_path:$belle_path \ -v $hf_home:$hf_home \ -v $ssh_pub_key:/root/.ssh/authorized_keys \ -w $workdir \ $docker_user/belle:$tag \ [--sshd_port 2201 --cmd "echo 'Hello, world!' && /bin/bash"] []中内容可忽略 --rm:容器退出时销毁,如果长期在容器中工作,可忽略 --sshd_port:sshd监听端口,默认是22001 --cmd:容器要执行的命令"echo 'Hello, world!' && /bin/bash",可忽略 hf_home:huggingface缓存目录 $ssh_pub_key:sshd公钥目录 |
T2、conda或pip安装
| 安装 | 由于部分包依赖系统环境编译,推荐使用docker。假如由于机器等原因不能使用docker,也可以通过conda创建环境,然后pip安装需要的包,需自行解决依赖问题 pip install -r requirements.txt |
| 注意事项 | 但是通过pip安装deepspeed很有可能安装或者运行失败,FAQ 中给出了一些安装deepspeed的教程以及可能遇到的问题 地址:https://github.com/LianjiaTech/BELLE/blob/main/train/docs/FAQ.md |
2、模型下载及其格式转换
2.1、下载官方模型权重
地址:https://github.com/LianjiaTech/BELLE/tree/main/models
2.2、模型权重转换为hf格式
(1)、facebook官方LLaMA权重转为hf格式
| 下载 | 首先,您需要从facebookresearch/llama获取LLaMA模型的访问权限,下载官方检查点 地址:GitHub - facebookresearch/llama: Inference code for LLaMA models |
| 转换 | python scripts/convert_llama_weights_to_hf.py --input_dir download_official_llama_path --model_size 7B --output_dir xx/llama-7b-hf 运行训练脚本时将model_name_or_path改为xx/llama-7b-hf即可 |
(2)、BELLE-LLaMA转为hf格式
| 下载 | 由于LLaMA模型的使用约束,我们只能开源与原始模型的diff(如:BELLE-LLaMA-7B-2M-enc)。 |
| 转换 | 当您已经从facebookresearch/llama获取LLaMA模型的访问权限后,可参考 https://github.com/LianjiaTech/BELLE/tree/main/models ,转换后的模型即为我们指令调优后的LLaMA模型。 地址:https://github.com/LianjiaTech/BELLE/tree/main/models |
3、合并词表:扩充LLaMA模型的原始中文词表,参考merge_tokenizers.py
| 实现代码 | 如果您想在原版LLaMA的基础上扩充中文词表,可参考scripts/merge_tokenizers.py,后续会开放训练embedding的代码,即当前版本的代码尚不包含用于训练embedding的部分,后期会新增用于在扩充了词表后的LLaMA模型上训练词向量的代码,来进一步优化模型的中文处理能力。 源码地址:https://github.com/LianjiaTech/BELLE/blob/main/train/scripts/merge_tokenizers.py |
| 效果 | 扩充词表后的效果可参考我们的工作:Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation |
LLMs之BELLE:源码解读(merge_tokenizers.py文件)训练和合并两个不同的SentencePiece分词模型—使用SentencePiece库来训练一个名为belle的BPE分词器→加载两个现有的分词器模型→合并词汇表→保存合并后的模型作为新的分词器模型
LLMs之BELLE:源码解读(merge_tokenizers.py文件)训练和合并两个不同的SentencePiece分词模型—使用SentencePiece库来训练一个名为belle的BPE分词_一个处女座的程序猿的博客-CSDN博客
4、模型微调
4.1、准备数据集
(0)、生成中文数据集
源地址文档:https://github.com/LianjiaTech/BELLE/tree/main/data/1.5M
| 子集 | 各子集使用统一的字段 instruction: 指令 input: 输入 output: 输出 |
| zh_seed_tasks.jsonl:包含175个种子任务。 0.5M生成的数据 : 为了方便模型训练,huggingface开源数据将原始生成文件中的"instruction"、"input"字段合并成"input"字段,"output"字段修改为"target"字段。 1M生成的数据:生成方式与0.5M数据集相同,在后处理中去掉了一些质量不高的数据,例如自称GPT模型的数据、由于input不完善导致模型无法回答的数据,以及指令是中文但input或target是英文的数据。 | |
| 命令 | 沿用Alpaca的方式: pip install -r requirements.txt export OPENAI_API_KEY=YOUR_API_KEY python 1.5M/generate_instruction.py generate_instruction_following_data 默认使用Completion API,模型text-davinci-003。如果想使用Chat API并使用gpt-3.5-turbo模型,可通过参数控制: python 1.5M/generate_instruction.py generate_instruction_following_data \ --api=chat --model_name=gpt-3.5-turbo |
| 输出 | 输出文件在Belle.train.json,可以人工筛选后再使用。 |
含175个种子任务zh_seed_tasks.jsonl示例
{"id": "seed_task_8", "name": "english_haiku_generation", "instruction": "请以下面词语为主题写一首诗", "instances": [{"input": "夏天", "output": "不但春妍夏亦佳,随缘花草是生涯。\n鹿葱解插纤长柄,金凤仍开最小花。"}], "is_classification": false}{"id": "seed_task_38", "name": "synonym_generation", "instruction": "给出下面词语的同义词", "instances": [{"input": "惊人地", "output": "令人惊奇地,令人惊讶地,意外地,难以置信地,不可思议地"}], "is_classification": false}……LLMs之BELLE:源码解读(generate_instruction.py文件)让机器自动生成大量指令数据并避免生成重复内容—利用GPT-3模型生成自我指导的任务指令→并根据相似度筛选出合适的指令→保存到文件中→用于NLP的训练与评估
LLMs之BELLE:源码解读(generate_instruction.py文件)让机器自动生成大量指令数据并避免生成重复内容—利用GPT-3模型生成自我指导的任务指令→并根据相似度筛选出合适的指令-CSDN博客
(1)、指令微调(SFT)数据集
| 下载数据集 | wget https://huggingface.co/datasets/BelleGroup/school_math_0.25M/resolve/main/school_math_0.25M.json |
| 数据集示例 | 该数据是数学应用题求解任务,包含解题过程,共计约25万条。示例 |
| 转换格式 | 转换数据格式:并选取前1000条作为验证集,其余数据作为训练集 python scripts/convert_to_conv_data.py --orig_data school_math_0.25M.json --write_data school_math_0.25M_conv.json --dataset_name bellemath head -n 1000 school_math_0.25M_conv.json > belleMath-dev1K.json tail -n +1001 school_math_0.25M_conv.json > belleMath.json 其他的训练数据见:https://huggingface.co/BelleGroup 按照上述流程转换格式即可 |
| 单论对话数据集 **注:**目前仓库的代码要兼容单轮和多轮数据,因此对于之前的开源数据(格式为[instruction,output],目前绝大部分开源的单轮instruction数据均为这种格式),需要用convert_to_conv_data.py脚本转换为如下的统一格式: {"id": "bellemath42", "conversations": [{"from": "human", "value": " 一箱鸡蛋有25个,小明爸爸每天给他9个鸡蛋吃,那么一箱鸡蛋能够供小明吃几天?"}, {"from": "assistant", "value": "\n一箱鸡蛋有25个,小明每天吃9个鸡蛋,用除法计算一下即可:\n25 ÷ 9 = 2余7\n也就是说,小明第1天到第2天共吃2个鸡蛋,第3天吃剩下的7个鸡蛋。\n因此,一箱鸡蛋能够供小明吃2天。"}]} {"id": "bellemath80", "conversations": [{"from": "human", "value": "小明手中有15颗糖果,他想要分给他的朋友小红和小李,每人分得的糖果数是3颗,那么他还剩下几颗糖果?"}, {"from": "assistant", "value": " \n1. 该题可以用减法来解决。小明手中有15颗糖果,每人分得3颗,所以小红和小李一共分得6颗糖果(3+3=6)。\n2. 然后再用原来的糖果总数减去分给小红和小李的糖果数,即可得到小明手中剩余的糖果数。 \n计算过程如下:\n15 - 6 = 9\n所以,小明还剩下9颗糖果。"}]} | |
| 多轮对话数据: shareGPT 是一个开源的大规模多轮对话数据,具体效果可参考我们的工作:Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation 当前代码已支持训练这种多轮对话数据。 数据下载:wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json |
LLMs之BELLE:源码解读(convert_to_conv_data.py文件)数据格式转换——将原始指令格式的数据文件{单轮对话任务,instruction+input+output}转换成标准的人机对话格式的数据文件{多轮对话任务,id+conversations[人类+助手]]}
LLMs之BELLE:源码解读(convert_to_conv_data.py文件)数据格式转换——将原始指令格式的数据文件{单轮对话任务,instruction+input+output}转换成标准-CSDN博客
(2)、继续预训练(PT)数据格式
| 数据集格式 | 数据格式 {"text": xxx} {"text": xxx} |
4.2、模型训练
(1)、两大训练场景:继续预训练(run_pt.sh)、指令微调(run_sft.sh)
| 注意 | 训练的启动脚本写在scripts/run_<pt|sft>.sh,你需要按照实际需求修改run_<pt|sft>.sh中的参数。 启动脚本中均包含了全量参数微调和LoRA两种训练方式的启动命令,这里将简单说明下启动命令中各个参数的含义 |
| 训练命令 | bash scripts/run_sft.sh |
| 参数解释 | model_name_or_path 代表预训练模型(如果是LLaMA模型,需事先转为hf格式才能通过from_pretrained读取) train_file 代表训练数据 validation_file 代表验证数据 output_dir 代表训练日志和模型保存的路径 cache_dir 代表缓存数据处理过程的路径 cutoff_len 代表最长输入序列长度(LLaMA模型建议设置为1024以上,Bloom模型设置为512以上) |
| 支持的训练方式 | run_<pt|sft>.sh中包含了全量参数微调和LoRA两种训练方式的启动命令,这里将简单说明下启动命令中各个参数的含义。 |
| 参数解释 | 模型从检查点恢复:如果output_dir包含了多个存档点,训练直接从最新的存档点恢复,也可以--resume_from_checkpoint ${output_dir}/checkpoint-xxx手动指定从step xxx恢复。 Flash Attention:flash attention实现了高效利用显存的attention,可支持更大的序列长度。 run_pt.sh中,默认使用flash-attention-v2 run_sft.sh中,flash-attention-v2可选,可通过--use_flash_attention打开 |
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯度检查点/flash_attention)→加载训练和验证数据集→模型训练
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯-CSDN博客
(2)、微调的三种方式
| 训练方式 | 支持配置 >> 全量微调 + Deepspeed >> LoRA + Deepspeed >> LoRA + int8 |
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯度检查点/flash_attention)→加载训练和验证数据集→模型训练
LLMs之BELLE:源码解读(sft_train.py文件)源码解读(sft_train.py文件)采用LoRA微调模型—解析命令行参数→参数与日志初始化→初始化模型和标记器→模型优化(LoRA/梯-CSDN博客
T1、基于单机多卡—全量参数微调:
| 脚本命令 | 下面的命令是单机多卡进行全量参数微调,同时采用deepspeed,基础模型是LLaMA。 torchrun --nproc_per_node 8 src/entrypoint/sft_train.py \ --model_name_or_path ${model_name_or_path} \ --llama \ --deepspeed configs/deepspeed_config.json \ --train_file ${train_file} \ --validation_file ${validation_file} \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 4 \ --num_train_epochs 2 \ --model_max_length ${cutoff_len} \ --save_strategy "steps" \ --save_total_limit 3 \ --learning_rate 8e-6 \ --weight_decay 0.00001 \ --warmup_ratio 0.05 \ --lr_scheduler_type "cosine" \ --logging_steps 10 \ --evaluation_strategy "steps" \ --fp16 True \ --seed 1234 \ --gradient_checkpointing True \ --cache_dir ${cache_dir} \ --output_dir ${output_dir} |
| 参数解释 | --nproc_per_node:如果想要单卡训练,仅需将nproc_per_node设置为1即可 -llama:如果预训练模型不是LLaMA,则去掉--llama。如果是LLaMA模型,需要指定--llama。因为LLaMA模型需要采用LLamaTokenizer加载,如果用AutoTokenizer加载llama可能会出现无限递归的问题,这和transformers版本有关。 |
| --deepspeed:如果运行环境不支持deepspeed,去掉--deepspeed。deepspeed 的参数配置可参考: 官网:DeepSpeed Configuration JSON - DeepSpeed Huggingface:https://huggingface.co/docs/accelerate/usage_guides/deepspeed Github:https://github.com/huggingface/transformers/blob/main/tests/deepspeed >> 如果显存充足,可优先考虑stage 2,对应的配置文件是configs/deepspeed_config.json。如果显存不足,可采用stage 3,该模式下模型参数将分布在多张显卡上,可显著减小显存占用,对应的配置文件是configs/deepspeed_config_stage3.json。 >> 不开deepspeed会占用更多显存,建议全量参数finetune模式尽可能采用deepspeed >> LoRA训练如果采用8bit量化,就不能使用deepspeed;如果使用deepspeed,就不能指定use_int8_training | |
| 输出结果 | 训练日志和模型保存在output_dir目录下,目录下的文件结构应该如下 output_dir/ ├── checkpoint-244/ │ ├── pytorch_model.bin │ ├── config.json │ └── trainer_state.json ├── checkpoint-527/ │ ├── pytorch_model.bin │ ├── config.json │ └── trainer_state.json ├── pytorch_model.bin ├── print_log.txt └── config.json 其中,trainer_state.json记录了loss、learning_rate的变化。 |
T2、基于单机多卡—LoRA微调
| 脚本命令 | torchrun --nproc_per_node 8 src/entry_point/sft_train.py \ --model_name_or_path ${model_name_or_path} \ --llama \ --use_lora True \ --use_int8_training \ --lora_config configs/lora_config_llama.json \ --train_file ${train_file} \ --validation_file ${validation_file} \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 4 \ --num_train_epochs 2 \ --model_max_length ${cutoff_len} \ --save_strategy "steps" \ --save_total_limit 3 \ --learning_rate 8e-6 \ --weight_decay 0.00001 \ --warmup_ratio 0.05 \ --lr_scheduler_type "cosine" \ --logging_steps 10 \ --evaluation_strategy "steps" \ --fp16 True \ --seed 1234 \ --gradient_checkpointing True \ --cache_dir ${cache_dir} \ --output_dir ${output_dir} \ # --deepspeed configs/deepspeed_config_stage3.json |
| 参数解释 | use_lora 代表采用LoRA训练 use_int8_training 代表采用8bit量化训练,可显著减少显存占用 lora_config 给出了LoRA的参数配置。如果训练Bloom模型,则改为configs/lora_config_bloom.json deepspeed 训练的序列较长时,推荐使用deepspeed stage 3,能有效将模型参数分配到多卡上,留下空间加载更长的序列 注意:use_int8_training和deepspeed只能二选一,不可同时使用 |
| 输出结果 | output_dir目录的文件结构如下: output_dir/ ├── checkpoint-244/ │ ├── pytorch_model.bin │ └── trainer_state.json ├── checkpoint-527/ │ ├── pytorch_model.bin │ └── trainer_state.json ├── print_log.txt └── adapter_config.json 最上级目录存储训练的最终模型 |
合并LoRA权重
| 简介 | 如果您想要实现LoRA权重与预训练模型的合并,可运行如下命令: bash scripts/merge_lora.sh 合并后的权重保存在output_path目录下,后续可通过from_pretrained直接加载 |
| 合并的意义 | LoRA权重合并主要是为了获得一个结合了预训练模型和LoRA微调知识的新模型,这样的融合模型可以直接加载使用,比分别加载两份参数更加简洁方便。 >> LoRA训练完成后,模型权重是保存在适配器中,而不是主要的模型参数里。这意味着如果直接加载LoRA训练好的模型,只会加载适配器的参数,而不会加载预训练模型的参数。 >> 为了让训练好的LoRA适配器参数和原始预训练模型参数结合起来,需要进行权重合并。这样合并后的模型才同时包含了原始预训练模型学习到的知识,以及LoRA适配器对下游任务进行微调学习到的知识。 >> 权重合并后,就可以得到一个融合了预训练模型强大语言表达能力和LoRA适配器针对性调优知识的新模型。这样的模型可以直接通过from_pretrained方法加载使用。 >> 如果不进行权重合并,则预训练模型参数和LoRA适配器参数是分离的,每次使用时都需要同时加载两份参数才可以,使用上不太方便。 |
T3、多机多卡训练:以2台8卡为例
| 简介 | 以两台机器为例,每台机器上有8张卡 首先需要在第一台机器(主机器)上运行 bash scripts/multinode_run.sh 0 然后在第二台机器上运行 bash scripts/multinode_run.sh 1 |
| 训练命令 | node_rank=$1 echo ${node_rank} master_addr="10.111.112.223" # #Multi-node torchrun --nproc_per_node 8 --nnodes 2 --master_addr ${master_addr} --master_port 14545 --node_rank ${node_rank} src/train.py |
| 参数解释 | 参数说明 node_rank 代表节点的rank,第一台机器(主机器)的rank设置为0,第二台机器的rank设置为1 nnodes 代表节点机器的数量 master_addr 代表主机器的ip地址 master_port 代表与主机器通信的端口号 |
5、模型推理:验证模型生成文本的效果
T1、CLI:命令脚本实现
| 简介 | 模型推理:验证模型生成文本的效果 |
| 脚本命令 | CUDA_VISIBLE_DEVICES=0 python src/entry_point/inference.py \ --model_name_or_path $model_name_or_path \ --ckpt_path $ckpt_path \ --llama \ --use_lora |
| 参数解释 | model_name_or_path 是原生预训练模型的路径 ckpt_path 是训练后保存的模型路径,也就是output_dir llama 代表基础模型是否是LLaMA模型 use_lora 代表ckpt_path是否是LoRA权重 |
| 注意事项 | 注:LoRA训练后保存的模型adapter_model.bin有可能是空文件,此时需要将其它checkpoint-step下保存的pytorch_model.bin复制到output_dir目录下。 如果您已经将LoRA权重与预训练模型进行了合并,则ckpt_path指定为合并后权重保存的路径即可,不需要再指定use_lora。 |
T2、WebUI:基于gradio的交互式web界面交互实现
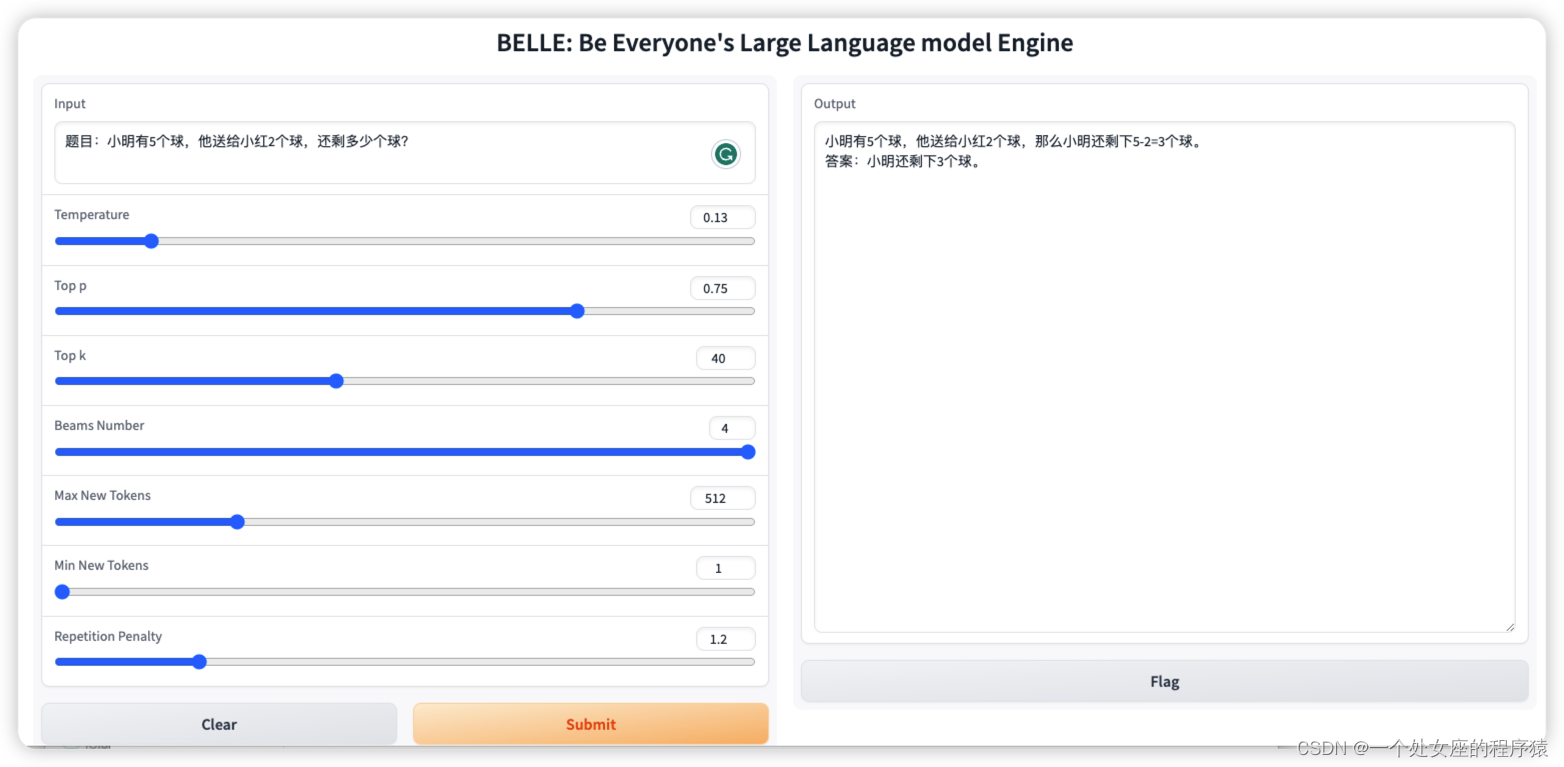
| 简介 | 提供了一个简洁的基于gradio的交互式web界面,启动服务 |
| 脚本命令 | CUDA_VISIBLE_DEVICES=0 python src/entry_point/interface.py \ --model_name_or_path $model_name_or_path \ --ckpt_path $ckpt_path \ --llama \ --use_lora 服务访问地址是 hostip:17860 |
T3、加速推理—并行推理
| 脚本命令 | bash scripts/run_multi_backend.sh |
| 自定义 | 打开src/entry_point/evaluation.ipynb,设置相应路径,加载自己的数据推理。 |
T4、加速推理—基于ZeRO的推理
| 简介 | Zero Inference利用ZeRO stage 3的数据并行特性,能够将模型分布到多张GPU上,或者Offload到内存或者NVMe上,推理单GPU无法加载的模型 (1)、Zero Inference是数据并行的推理,因此需要在各个GPU同时启动推理进程并进行model.forward,否则会卡住 | ||||||||||||||||
| 对比 | 三大并行对比
| ||||||||||||||||
| 注意事项 | 本仓库实现了LLaMA和LLaMA 2的flash attention,可在推理时启动,降低显存占用。 由于flash attention不支持自定义的attention mask,启动flash attention时,batch size必须设为1并关闭任何padding。 |
T4.1、批量推理(推荐)
| 准备数据 | 准备数据 {"text": xxx} {"text": xxx} |
| 脚本命令 | 运行 bash scripts/run_zero_inference.sh 可传入的参数有max_new_tokens、min_new_tokens、do_sample、num_beams、temperature、top_k、top_p、repetition_penalty。 具体说明见huggingface文档, https://huggingface.co/docs/transformers/main/main_classes/text_generation |
T4.2、推理后端(前后端分离)
| 两步骤实现 | 第一步,运行后端 bash scripts/run_zero_inference_backend_without_trainer.sh devices:指令使用哪几个显卡,格式同CUDA_VISIBLE_DEVICES base_port:后端服务监听端口,打开[base_port, base_port + num_devices - 1]的端口 第二步,运行前端 运行src/evaluation.ipynb,由于ZeRO Inference要求多个model.forward必须同时运行,必须设置synced_worker=True,同时保证客户端连接上了每个后端进程 |
T5、Colab:BELLE模型在Colab推理的示例:colab上面可运行的推理代码
| 简介 | 提供在colab环境运行BELLE模型的代码。默认加载的是4bit量化的BLOOM 7B模型,4bit量化的模型目前效果上面还是会有损失。 在模型加载到内存过程中,最高消费RAM大概需要8G,等模型load到GPU中以后,RAM只需要4G,GPU大概需要10G。 |
地址:https://colab.research.google.com/github/LianjiaTech/BELLE/blob/main/models/notebook/BELLE_INFER_COLAB.ipynb
6、模型量化:基于GPTQ为LLaMa量化的开源实现,将其应用于Belle模型
| 简介 | 利用GPTQ技术对Belle模型进行量化压缩的方法、模型使用与部署建议。重点介绍了Huggingface上预训练模型的使用、预测代码及模型量化保存示例。对理解应用GPTQ压缩Belle模型提供了方便。 |
地址:https://github.com/LianjiaTech/BELLE/tree/main/models/gptq
7、RLHF训练流程
T1、PPO训练
(1)、奖励模型
| 准备数据 | 准备数据 {"chosen": xxx, "rejected": xxx} 注意: xxx文本已经添加了正确的提示,用于区别人类和bot,如 Human: \n{text}\n\nAssistant: \n{text} |
| 训练 | bash scripts/run_rm.sh use_llama:是否使用llama作为基础模型 use_lora:是否使用lora微调 load_in_8bit:是否使用8bit载入 load_in_4bit:是否使用4bit载入 |
| 注意 | 支持deepspeed stage 3直接运行 不支持deepspeed stage 3 + lora,deepspeed stage 1/2 + lora可以运行 load_in_8bit和load_in_4bit不能和deepspeed同时使用,可以和lora同时使用。需要将 configs/accelerate_config_rm.yaml中"distributed_type"从"DEEPSPEED"改为"MULTI_GPU" |
| TODO | deepspeed stage 3 + lora支持 |
LLMs之BELLE:源码解读(ppo_train.py文件)训练一个基于强化学习的自动对话生成模型—解析命令行参数→加载数据集(datasets库)→初始化模型分词器和PPOConfig配置参数(trl库)→模型训练(accelerate分布式训练+DeepSpeed推理加速,生成对话→计算奖励【评估生成质量】→执行PPO算法更新【改善生成文本的质量】)→模型保存之详细攻略
LLMs之BELLE:源码解读(ppo_train.py文件)训练一个基于强化学习的自动对话生成模型—解析命令行参数→加载数据集(datasets库)→初始化模型分词器和PPOConfig配置参数(t_一个处女座的程序猿的博客-CSDN博客
(2)、PPO
| 准备数据 | {"text": xxx} 注意:xxx文本已经添加了正确的提示,用于区别人类和bot,如 Human: \n{text}\n\nAssistant: \n |
| 训练 | bash scripts/run_ppo.sh use_llama:使用llama作为基础模型 use_lora:使用lora微调 batch_size:每个进程搜集的experience大小 mini_batch_size:在experience上训练的batch大小 input_length:输入文本的最长长度,超过该长度会被过滤掉 ppo_epochs:在采样的batch训练多少轮 data_epochs:在prompt数据上训练多少轮 |
| 注意 | 支持deepspeed zero stage 3,拆分model、ref_model和reward_model 支持deepspeed zero stage 3 + lora 数据集大小要大于 num_processes * batch_size,否则部分进程拿不到数据,出现报错,输出中 Train dataset length可以看到经过长度过滤的数据集大小 |
| TODO | >> 每次训练的batch_size是 num_processes * batch_size,每个进程只会从自己的 batch中采样,而不是从全局的 num_processes * batch_size中采样,这会导致每个gpu采到的 mini_batch不是完全随机的,mini_batch不包含其它进程 batch中的样本 >> gradient checkpointing >> resume from checkpoint |
T2、DPO训练
| 准备数据 | 格式: {"chosen":xxx, "reject":xxx, "prompt":xxx} 一条数据样例: {"chosen": "水的化学式是H2O。这意味着每个水分子由两个氢原子(H)和一个氧原子(O)组成。在这个结构中,氢原子和氧原子通过共价键相连。", "rejected": "H2O.", "prompt": "Human: \n水的化学式是什么?\n\nAssistant: \n"} |
| 训练 | 首先,请将“train/scripts”下“run_dpo.sh”脚本中的“...”改成所需参数值 其次: cd train/scripts bash run_dpo.sh |
LLMs之BELLE:源码解读(dpo_train.py文件)训练一个基于强化学习的自动对话生成模型(DPO算法微调预训练语言模型)—解析命令行参数与初始化→加载数据集(json格式)→模型训练与评估之详细攻略
LLMs之BELLE:源码解读(dpo_train.py文件)训练一个基于强化学习的自动对话生成模型(DPO算法微调预训练语言模型)—解析命令行参数与初始化→加载数据集(json格式)→模型训练与评估-CSDN博客
BELLE的使用方法
1、使用App在设备端本地运行4bit量化的BELLE-7B模型
可以使用App在设备端本地运行4bit量化的BELLE-7B模型,在M1 Max CPU上实时运行的效果(未加速)。App下载详见App配套模型下载及使用说明,App下载链接,目前仅提供了mac os版本。模型需要单独下载。模型经过量化后,效果损失明显,我们将持续研究如何提升。
这篇关于LLMs之BELLE:BELLE(一款能够帮到每一个人的中文LLM引擎)的简介(基于Alpaca架构+中文优化+考察词表扩充/数据质量/数据语言分布/数据规模的量化分析)、使用方法、案例应用之详细攻略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




