词表专题
数据统计:词频统计、词表生成、排序及计数、词云图生成
文章目录 📚输入及输出📚代码实现 📚输入及输出 输入:读取一个input.txt,其中包含单词及其对应的TED打卡号。 输出 output.txt:包含按频率降序排列的每个单词及其计数(这里直接用于后续的词云图生成)。 output_word.json:包含每个单词及其计数,以及与之关联的TED打卡号列表,生成一个json文件(按字母序排列,用于后续网页数据导入

基于逆向最大化词表中文分词法。(转载)
应用别人的东西 以前做知识管理系统的时候,由于需要建立全文检索和统计词频,需要对中文文本进行分词。对于中文分词, 国内做到好的应该是中科院自然研究所,但是相对比较复杂,我看了几次没有看明白. :) ,由于平常我们的知识系统 对分词的要求没有这么高,所以 就选择了最大化的词表分词法. 词表选择的是人民日报97版的词表. 实际效果可以达到90%以上,基本可以满足需要。支持 Lucene.n

WordPiece词表的创建
文章目录 一、简单介绍二、步骤流程2.1 预处理2.2 计数2.3 分割2.4 添加subword 三、代码实现 本篇内容主要介绍如何根据提供的文本内容创建 WordPiece vocabulary,代码来自谷歌; 一、简单介绍 wordpiece的目的是:通过考虑单词内部构造,充分利用subwords的优势,在把长word转化为短word提高文字的灵活性以及提高word转化
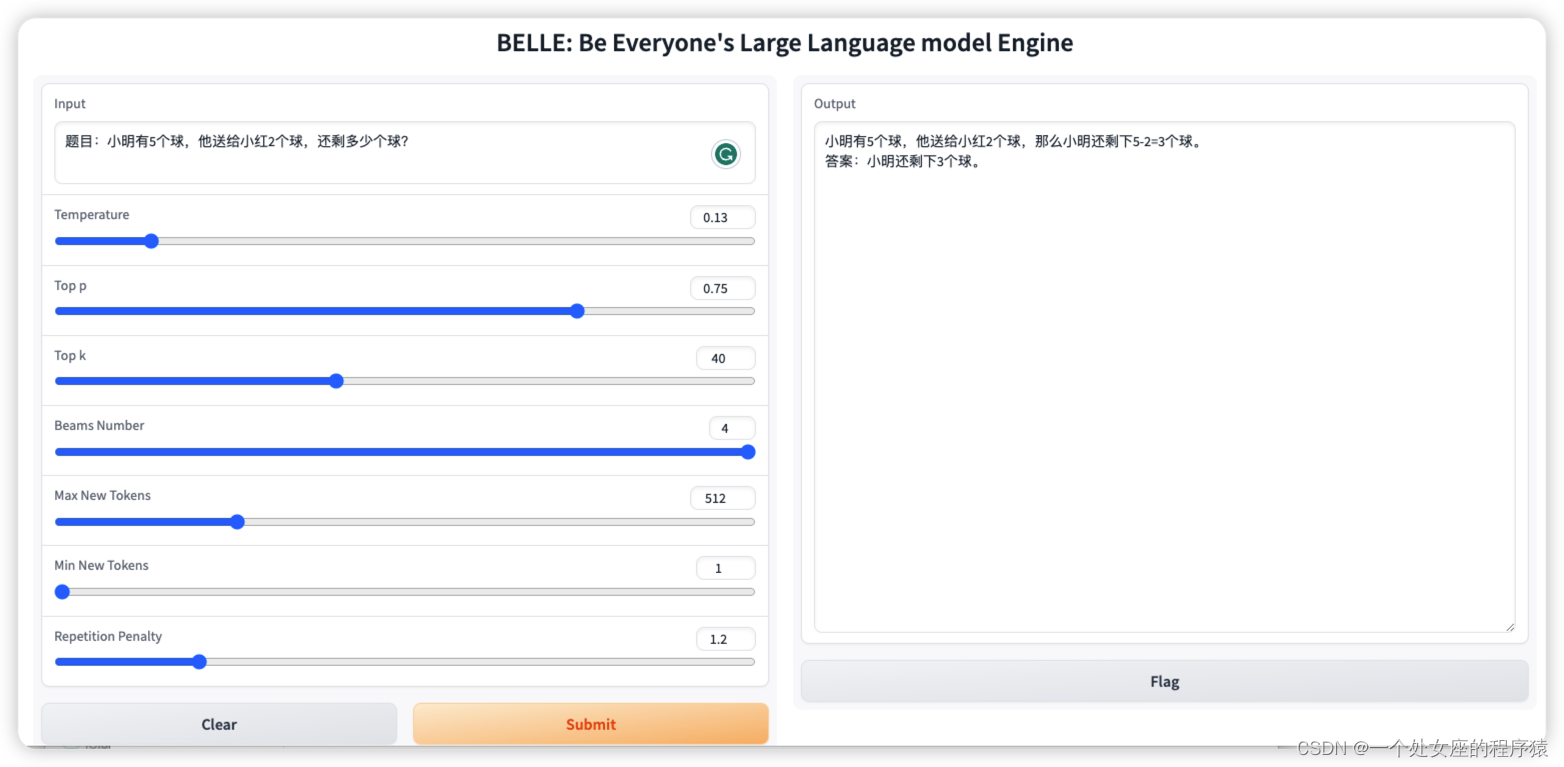
LLMs之BELLE:BELLE(一款能够帮到每一个人的中文LLM引擎)的简介(基于Alpaca架构+中文优化+考察词表扩充/数据质量/数据语言分布/数据规模的量化分析)、使用方法、案例应用之详细攻略
LLMs之BELLE:BELLE(一款能够帮到每一个人的中文LLM引擎)的简介(基于Alpaca架构+中文优化+考察词表扩充/数据质量/数据语言分布/数据规模的量化分析)、使用方法、案例应用之详细攻略 导读:2023年4月8日,BELLE(Be Everyone's Large Language model Engine),项目目标是促进中文对话大模型开源社区的发展,愿景是成为能够帮到每一个人
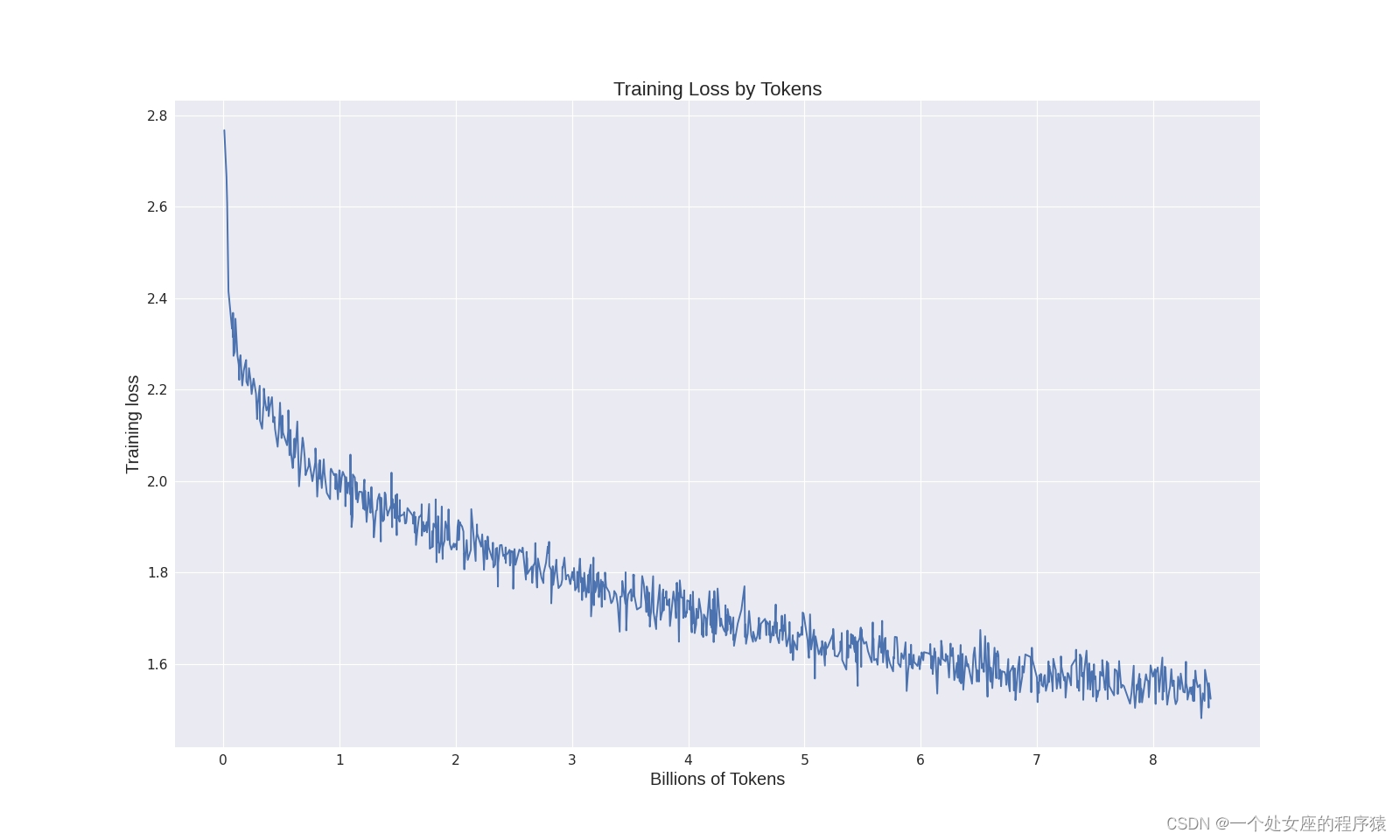
LLMs之Colossal-LLaMA-2:Colossal-LLaMA-2的简介(基于LLaMA-2架构+中文优化+扩充词表+仅千美元成本)、安装、使用方法之详细攻略
LLMs之Colossal-LLaMA-2:Colossal-LLaMA-2的简介(基于LLaMA-2架构+中文优化+扩充词表+仅千美元成本)、安装、使用方法之详细攻略 导读:2023年9月25日,Colossal-AI团队推出了开源模型Colossal-LLaMA-2-7B-base = 8.5B的token 数据+6.9万词汇+15 小时+不到1000美元的训练成本。Colossal-LL

对于LLM来说,token何必是表广义token时代 大词表时代
何必是表广义token 摘要:引言:方法:结论:分析: 摘要: 本论文主要探讨了语言模型(LLM)中词表的作用以及与数据处理方式的关系。首先,我们介绍了词表作为存储信息的表和数据库或数据中心的角色,然后讨论了增加词表大小的影响。接下来,我们从两个角度出发,一是从token_id层面将数字分解为嵌入向量和输出头,二是从信息本身层面使用多个表和字段处理数据。最后,我们总结了这两种处理

LLM-LLaMA中文衍生模型:LLaMA-ZhiXi【没有对词表进行扩增、全参数预训练、部分参数预训练、指令微调】
下图展示了我们的训练的整个流程和数据集构造。整个训练过程分为两个阶段: (1)全量预训练阶段。该阶段的目的是增强模型的中文能力和知识储备。 (2)使用LoRA的指令微调阶段。该阶段让模型能够理解人类的指令并输出合适的内容。 3.1 预训练数据集构建 为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,我们并没有对词表进行扩增,而是搜集了中文语料、英文语料和