本文主要是介绍学习笔记|两独立样本秩和检验|曼-惠特尼 U数据分布图|规范表达|《小白爱上SPSS》课程:SPSS第十二讲 | 两独立样本秩和检验如何做?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 学习目的
- 软件版本
- 原始文档
- 两独立样本秩和检验
- 一、实战案例
- 二、统计策略
- 三、SPSS操作
- 1、正态性检验
- 2、两样本秩和检验
- 四、结果解读
- 疑问:曼-惠特尼 U数据分布图如何绘制?
- 五、规范报告
- 1、规范表格
- 2、规范文字
- 六、划重点
学习目的
SPSS第十二讲 | 两独立样本秩和检验如何做?
软件版本
IBM SPSS Statistics 26。
原始文档
《小白爱上SPSS》课程
#统计原理
两独立样本秩和检验
前面学习过两独立样本T检验,主要用于数据服从正态分布。
如果遇到数据严重偏态样本数据,可采用两种统计策略:一是将数据转化为正态分布数据;二是采用两独立样本秩和检验,一般用Mann-Whitney U 检验。
秩和检验的原理是将连续型数据排序后分配秩次,再对秩次做假设检验。假设检验的结果表述为“各组数据分布的差异有无统计学意义”。
需指出的是,虽然要重视数据的正态性,但样本量也很重要,如果样本量足够大(比如超过50),只要数据不是那么严重偏态,在近似正态范围内,也可使用t检验,而且更推荐用t检验。
一、实战案例
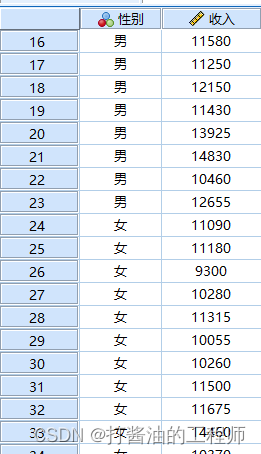
小白想了解男大侠和女大侠的收入差异。随机抽取了23名男侠和21名女侠,收集了每位大侠的性别和每月平均收入水平。
问,男女大侠之间的收入是否有差异?
读数据:
GETFILE='E:\E盘备份\recent\小白爱上SPSS\小白数据\第十二讲:两独立样本秩和检验.sav'.
二、统计策略
统计分析策略口诀“目的引导设计,变量确定方法”。
针对上述案例,扪心六问。
Q1:本案例研究目的是什么?
A:比较差异。
比较男侠和女侠收入分布有无统计学差异
Q2:本案例属于什么研究设计?
A:属于随机观察性研究。
事实上,两样本秩和检验也可用于实验性研究。
Q3:有几个变量?
A:有两个变量。
①自变量为性别
②因变量为收入
Q4:变量类型是什么?
A:自变量为分类变量
因变量为连续型变量。
Q5:连续型变量服从正态分布么?
A:需要检验。
Q6:可采用何种统计方法?
A:若服从,采用两独立样本T检验;
若不服从正态,可采用两样本秩和检验。
概括而言,如果数据满足以下条件,则采用两独立样本秩和检验。
三、SPSS操作
1、正态性检验
命令行:
EXAMINE VARIABLES=收入 BY 性别/PLOT HISTOGRAM NPPLOT /*若无此行,则不输出正态性检验表*//COMPARE GROUPS /STATISTICS DESCRIPTIVES /CINTERVAL 95 /MISSING LISTWISE /NOTOTAL.
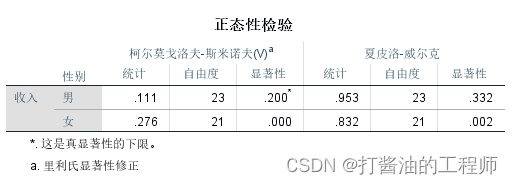
正态性检验结果:
直方图:
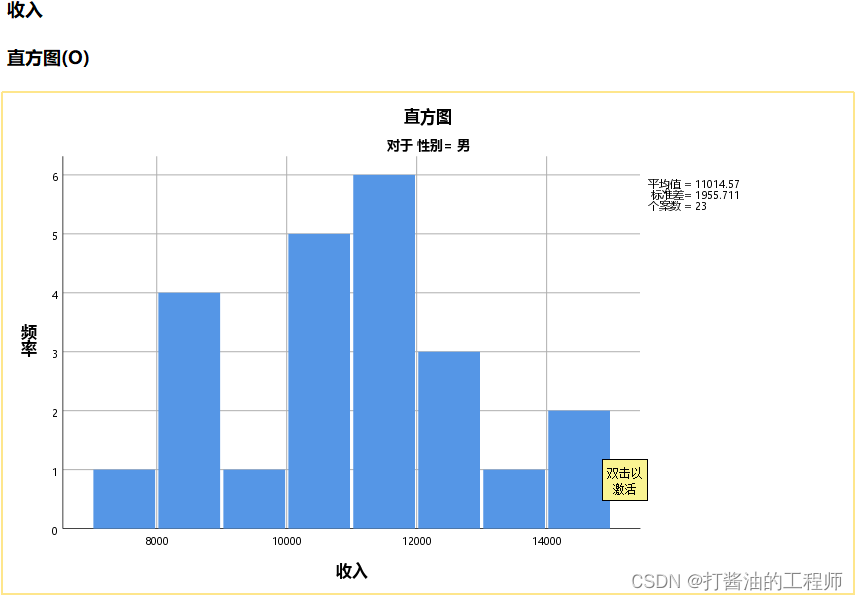
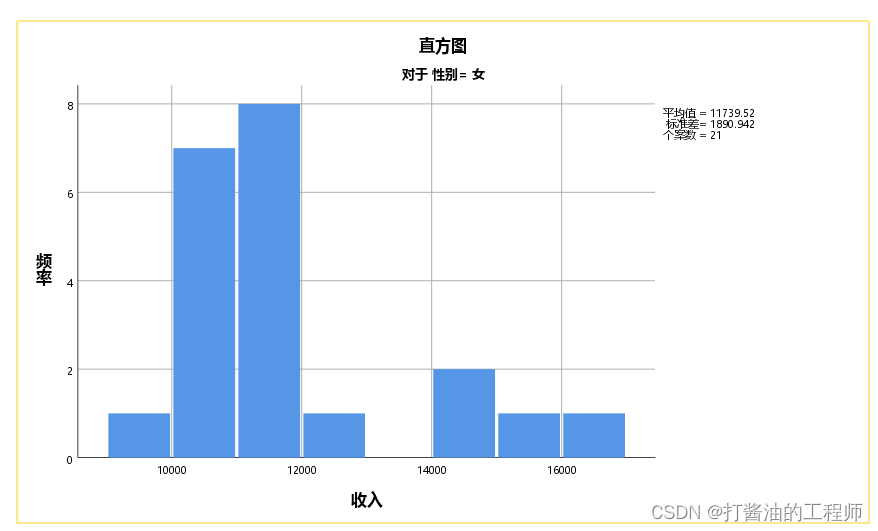
经S-W检验结果显示:男侠组收入P=0.332,女侠组收入P=0.002<0.01。同时结合直方图,可认为,男侠组服从正态分布,而女侠组不符合正态分布,建议采用两样本秩和检验。
2、两样本秩和检验
Step1 : 依次点击“分析—非参数检验–旧对话框–2个独立样本”,弹出两个独立样本检验对话框。
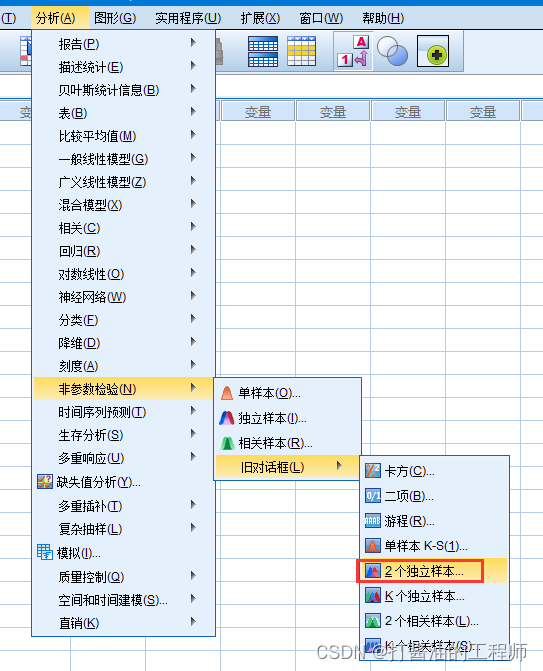
Step2 : 点击“收入”放入“检验变量”,性别放入“分组变量”同时进行定义组。
①检验类型:曼-惠特尼 U(Man-whttey U),是最常见的两样本秩和检验
②检验变量:即放入结局指标,本例为收入
③分组变量:放入性别。这里“定义组”需要进一步明确。
定义组:即指定比较哪两组。
在本例,我们比较男侠和女侠组,他们在数据库赋值为1和2,因此这里填写1,2;此处填什么数据,需要和数据库的赋值对应起来,且不能填写文字或者字母,只能填数字。
再次提醒:构建SPSS数据库时一般赋值建议用数字,不要用文字或者字母。
④选项:对总体数据进行基本的统计描述
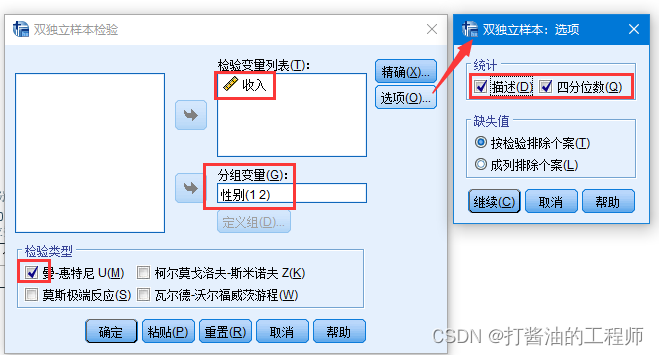
继续,确定,输出结果。
命令行:
NPAR TESTS /M-W= 收入 BY 性别(1 2) /STATISTICS=DESCRIPTIVES QUARTILES /MISSING ANALYSIS.
四、结果解读
根据上述SPSS操作,秩和检验将提供3张表格。
表1:提供对收入的总体描述
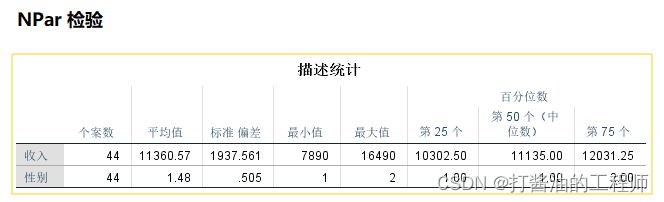
表2:提供分组描述收入平均排名(秩平均值)和总排名(秩总和)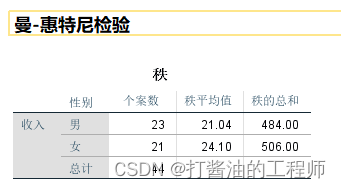
统计描述为各组的“平均秩次”和“秩总和”,然而,“平均秩次”和“秩总和”并不能充分反映各组数据的集中趋势。一般论文不报告秩平均和秩总和。
那报告什么呢?
对于非正态分布数据,中位数是描述其集中趋势的较好指标,四分位数是描述离散趋势的较好指标。
对于正态分布数据,均数是描述其集中趋势的较好指标,标准差是描述离散趋势的较好指标。
表3:秩和检验分析结果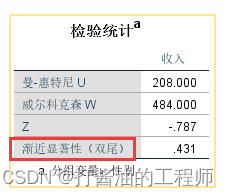
曼-惠特尼U(Mann-Whitney U)和威尔克森W(Wilcoxon)是常用的两独立样本秩和检验方法。
两者的检验方法没有实质上的差别,检验原理和结果也完全等价,只是在计算统计量时略有差别,统计分析时写清楚用哪种方法即可。
我们主要关注Z值和对应的p值。本案例的Z=-0.787,p=0.431>0.05, 表明两者的数据分布无显著性差异(数据分布图如下所示):
疑问:曼-惠特尼 U数据分布图如何绘制?
请选择“分析”——“非参数检验”——“独立样本”方式,在“设置”中选择“曼-惠特尼U”检验,确定
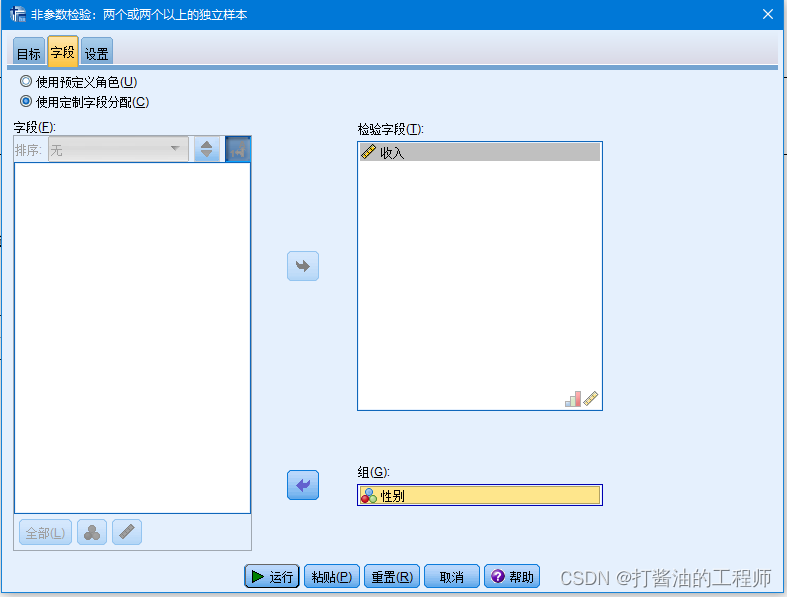
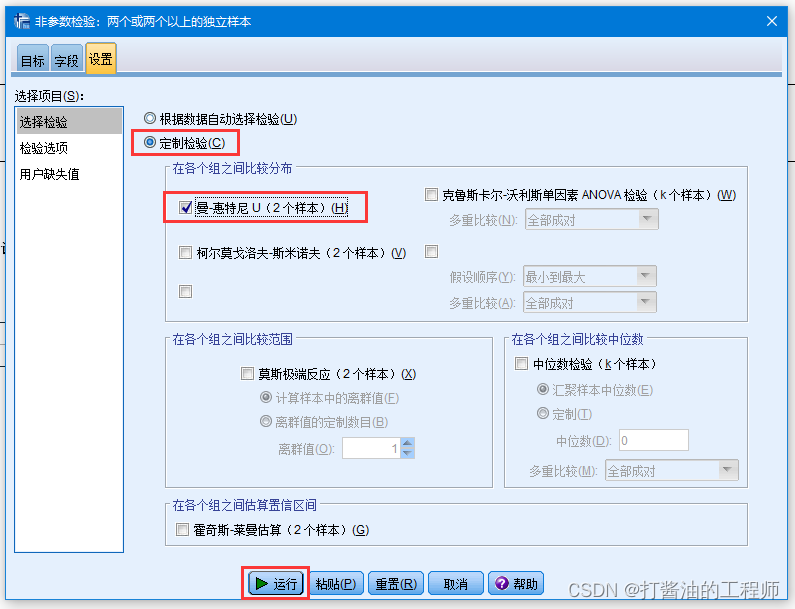
即可输出该图:
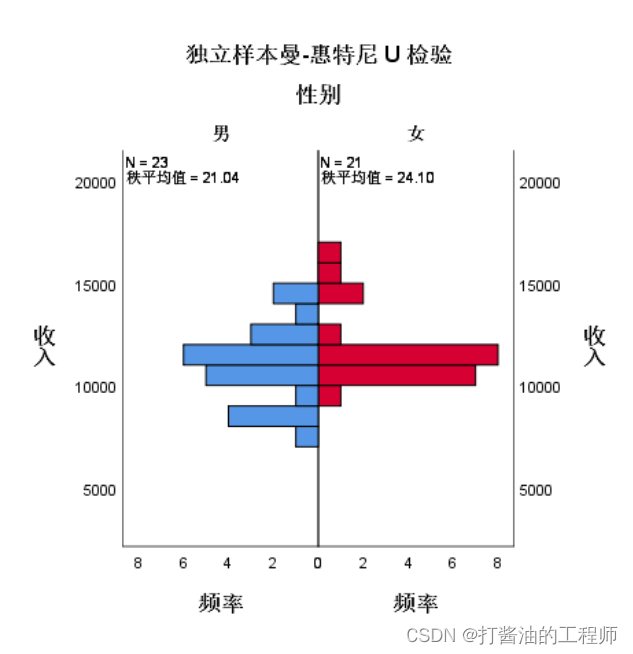
命令行:
*Nonparametric Tests: Independent Samples.
NPTESTS /INDEPENDENT TEST (收入) GROUP (性别) MANN_WHITNEY /MISSING SCOPE=ANALYSIS USERMISSING=EXCLUDE/CRITERIA ALPHA=0.05 CILEVEL=95.
五、规范报告
规范报告有多种方式,本公众号只提供一种方式供参考。
1、规范表格
表 男女大侠收入差异比较
注:数据不服从正态时,不能用平均数和标准差来描述;而应采用中位数和四分位距(第25百分位数和第75百分位数之距离)来描述。
如何获得中位数?详见第二讲|描述性统计,你学会了吗?
2、规范文字
经S-W检验以及直方图结果显示,女侠这一组数据不服从正态分布,故采用两样本Mann-Whitney U检验。
结果显示,男侠组收入的中位数11014.6(10168.9,11860)元,女侠组的中位数11739.5(10878.8,12600.3)元,两组总体收入分布不存在统计差异(Z=0.787,p =0.431)。
六、划重点
1、两独立样本的秩和检验主要是用于次序数据或不满足正态分布的连续型数据,一般用Mann-Whitney U检验。
2、如果数据严重偏态分布或存在若干个极端异常值,至少一组数据正态性检验p值接近0.01或者<0,01,优先考虑秩和检验。
3、秩和检验的描述性统计应采用中位数和四分位距(25%和75%位数),而非平均数和标准差。
小白学完两节秩和检验课程,心里又有几分成就感。
他想到了之前学习的配对样本T检验。如果数据不服从正态分布,那么也不适合T检验见,应该有配对秩和检验吧!
是的,小白思路没错,下一讲:配对样本秩和检验。
这篇关于学习笔记|两独立样本秩和检验|曼-惠特尼 U数据分布图|规范表达|《小白爱上SPSS》课程:SPSS第十二讲 | 两独立样本秩和检验如何做?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




