本文主要是介绍加速图像处理的神器: Intel ISPC编译器 (五) 迁移图像旋转算法 - ISPC单精度 从单核到多核 及最终性能提升结果,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在CPU的核心数越来越多,即使现在的移动平台也是动辄4核起。前面的代码都是用单线程来运行的,所以只用到了CPU的一个核心。接下来尝试一下使用ISPC多任务机制来利用CPU的多核加速。
ISPC代码从单核到多核的优化
在ISPC的开发手册里,最简单的多任务机制用到了2个关键字 launch和task
- 在一个函数前面加关键字task,标识这个函数是任务函数,可以在其他代码里通过launch语句来启动。任务函数可以被同时启动多次,在函数里有个内建的变量taskIndex, 标识着当前任务是第几个任务。
task void foo_task()
{print("taskIndex = %\n", taskIndex);
}- launch用来启动任务,launch后面的数组[100]表示同时启动100个foo_task任务
launch[100] foo_task();- ISPC编译器默认不提供多任务管理库,也就是说对应launch任务的底层函数需要自己来实现,具体的说明可以参考开发手册的“Task Parallelism: Runtime Requirements”部分。好在ISPC的例程里自带了一套示例代码tasksys.cpp, 前面在cmake的配置文件里设置USE_COMMON_SETTINGS,项目就会自动编译链接这个tasksys.cpp。
接下来把image_rotate_float_ispc()改成多任务版,先把输入图像分成多个小块,每个任务处理32像素高度的图像
块。
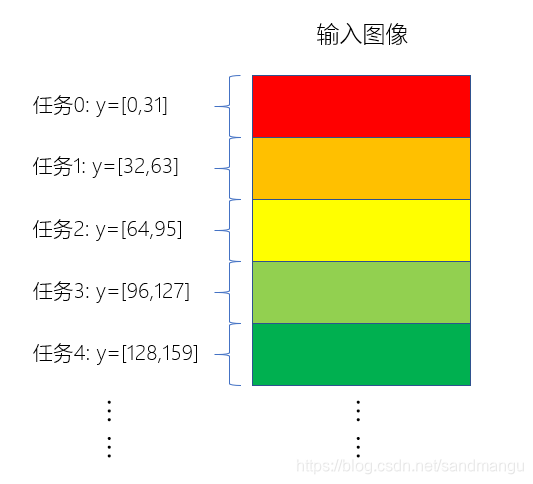
对应代码
#define M_PI_F 3.1415926535ftask void image_rotate_float_ispc_task(uniform const uint8 srcImg[], uniform uint8 dstImg[], uniform float center_x,uniform float center_y, uniform int iWidth, uniform int iHeight, uniform int span, uniform float skewDegree)
{//计算当前任务需要处理的图像块的起始y坐标和结束y坐标uniform int ystart = taskIndex * span;uniform int yend = min((taskIndex+1) * span, (unsigned int)iHeight);uniform float angle = (float)RotateDegree*M_PI_F / 180.0;uniform float alpha = cos(angle);uniform float beta = sin(angle);uniform float m[6];m[0] = alpha;m[1] = -beta;m[2] = (1.0 - alpha) * (float)center_x + beta * (float)center_y ;m[3] = beta;m[4] = alpha;m[5] = (1.0 - alpha) * (float)center_y - beta * (float)center_x;foreach (row = ystart ... yend, col = 0 ... iWidth) {float x, y;int leftX, rightX, topY, bottomY;float w00, w01, w10, w11;float fxy;x = m[0] * (float)col + m[1] * (float)row + m[2];y = m[3] * (float)col + m[4] * (float)row + m[5];leftX = floor(x);topY = floor(y);rightX = leftX + 1.0;bottomY = topY + 1.0;w11 = abs(x - leftX)*abs(y - topY);w01 = abs(1.0 - (x - leftX))*abs(y - topY);w10 = abs(x - leftX)*abs(1 - (y - topY));w00 = abs(1.0 - (x - leftX))*abs(1.0 - (y - topY));if ((int)leftX >= 0 && (int)rightX < Width && (int)topY >= 0 && (int)bottomY < Height) {fxy = (float)srcImg[topY*Width+ leftX]*w00 + (float)srcImg[bottomY*Width+ leftX]*w01 +(float)srcImg[topY*Width+ rightX]*w10 + (float)srcImg[bottomY*Width+ rightX]*w11;fxy = round(fxy);if (fxy < 0)fxy = 0;if (fxy > 255)fxy = 255;dstImg[row*Width+ col] = (uint8)(fxy);}elsedstImg[row*Width + col] = 0;};
};export void myWarpAffine_float_ispc_mt(uniform const uint8 srcImg[], uniform uint8 dstImg[], uniform float center_x,uniform float center_y, uniform int iWidth, uniform int iHeight, uniform float skewDegree)
{//任务分块,定义每个任务处理32像素高的图像块uniform int span = 32;//启动任务launch[iHeight/span] image_rotate_float_ispc_task(srcImg, dstImg, center_x, center_y, iWidth, iHeight, span, skewDegree);
};
运行一下多任务版本,我这个4核8线程的笔记本上耗时: 230ms
ISPC多核对单核算法的效率对比为
781ms/230ms=3.40X
也基本接近了4核4倍的理论值
最后的收官优化
在最后阅读ISPC开发手册的时候,发现了一个clamp函数
The clamp() functions clamp the provided value to the given range. (Their implementations are based on min() and max() and are thus quite efficient.)float clamp(float v, float low, float high)这不就是做我的代码里的把最终算出的像素值卡到[0,255]之间的功能么,赶快替换一下
fxy = round(fxy);
#if 0if (fxy < 0)fxy = 0;if (fxy > 255)fxy = 255;
#elsefxy = clamp(fxy,0,255);
#endif最后多核的运行时间: 211ms 又快了一点 :)
最终的性能提升总结
代码优化到这里,已经利用了SIMD和多核的硬件优势,大的优化可能基本已经没有了。如果要进一步的优化,就需要从内存和缓存的读取写入的利用率来重新调整代码架构了。这就属于终极优化部分了,对于我这个测试程序就没有意义了。
现在对比一下原始C代码和ISPC多核版本的性能提升
4294ms/211ms = 20.35X
对应的是并不多的改动时间,回报是巨大的,ISPC真乃神器 强烈推荐:)
最后放上ISPC的几个链接
ISPC的主页 这里是总入口,可以找到各种发行包,开发文档以及性能测试等各类信息
ISPC的Github ISPC编译器是完全开源的,有兴趣开发者的可以加上对自家硬件的支持
这篇关于加速图像处理的神器: Intel ISPC编译器 (五) 迁移图像旋转算法 - ISPC单精度 从单核到多核 及最终性能提升结果的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



