本文主要是介绍这个「女娲」模型火了!怒刷8项SOTA!MSRA和北大提出NÜWA:图像、视频生成大一统!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:新智元
编辑:好困 小咸鱼 LRS
【导读】微软亚洲研究院、北京大学强强联合提出了一个可以同时覆盖语言、图像和视频的统一多模态预训练模型——NÜWA(女娲),直接包揽8项SOTA。其中,NÜWA更是在文本到图像生成中完虐OpenAI DALL-E。5天github项目,已获得1000+ star!
太卷了,太卷了!
在几年前,要说AI能直接用一段文字描述生成清晰的图像,那可真是天方夜谭。
结果现在,Transformer的出现彻底带火了「多模态」这一领域。

照着文字「脑补」图像居然都不稀奇了!

更夸张的是,竟然有AI已经可以用文字描述去生成一段视频了,看上去还挺像模像样的。

这个AI不仅看文字描述可以生成视频,给它几幅草图,一样能「脑补」出视频来!

这么秀的AI出自何方神圣啊?
答案是微软亚洲研究院+北京大学强强联合的研究团队!
最近,微软可谓是跟OpenAI「干」上了。
前脚刚推出取得了40多个新SOTA的Florence「佛罗伦萨」吊打CLIP,横扫40多个SOTA。
后脚就跟着放出NÜWA「女娲」对标DALL-E。
今年1月,OpenAI官宣了120亿参数的GPT-3变体DALL-E。

论文地址:https://arxiv.org/pdf/2102.12092.pdf
DALL-E会同时接收文本和图像作为单一数据流,其中包含多达1280个token,并使用最大似然估计来进行训练,以一个接一个地生成所有的token。
这个训练过程让DALL-E不仅可以从头开始生成图像,而且还可以重新生成现有图像的任何矩形区域,与文本提示内容基本一致。

从文本「一个穿着芭蕾舞裙遛狗的萝卜宝宝」生成的图像示例
同时,DALL-E也有能力对生成的图像中的物体进行操作和重新排列,从而创造出一些根本不存在的东西,比如一个「一个长颈鹿乌龟」:

这次,MSRA和北大联合团队提出的统一多模态预训练模型——NÜWA(女娲),则可以为各种视觉合成任务生成新的或编辑现有的图像和视频数据。

论文地址:https://arxiv.org/abs/2111.12417
GitHub地址:https://github.com/microsoft/NUWA
为了在不同场景下同时覆盖语言、图像和视频,团队设计了一个三维变换器编码器-解码器框架,它不仅可以处理作为三维数据的视频,还可以适应分别作为一维和二维数据的文本和图像。
此外,论文还提出了一个3D邻近注意(3DNA)机制,以考虑视觉数据的性质并降低计算的复杂性。
在8个下游任务中,NÜWA在文本到图像生成、文本到视频生成、视频预测等方面取得了新的SOTA。其中,在文本到图像生成中的表现直接超越DALL-E。
同时,NÜWA在文本引导的图像和视频编辑任务中显示出优秀的zero-shot能力。
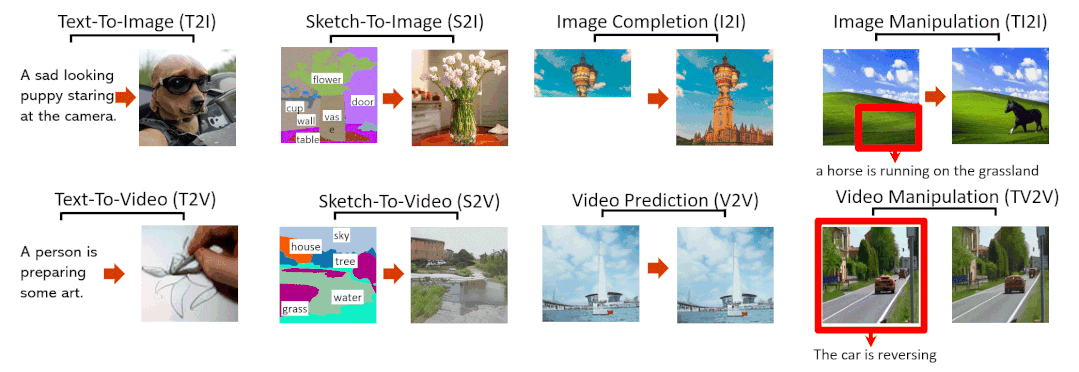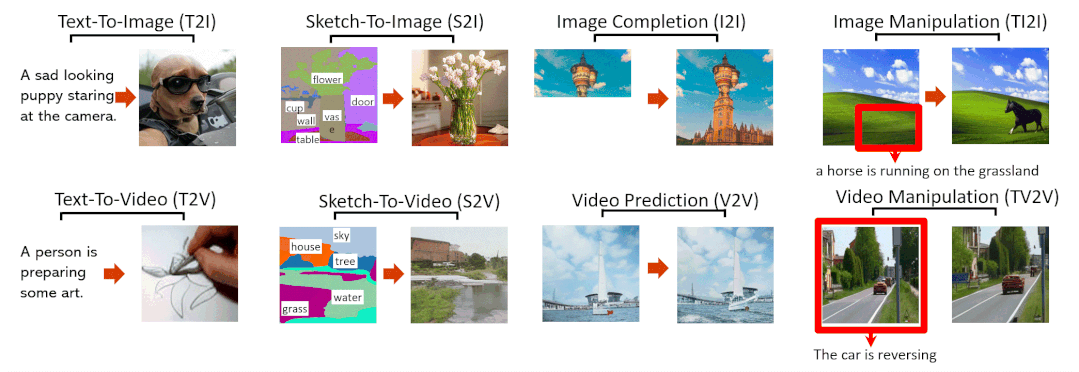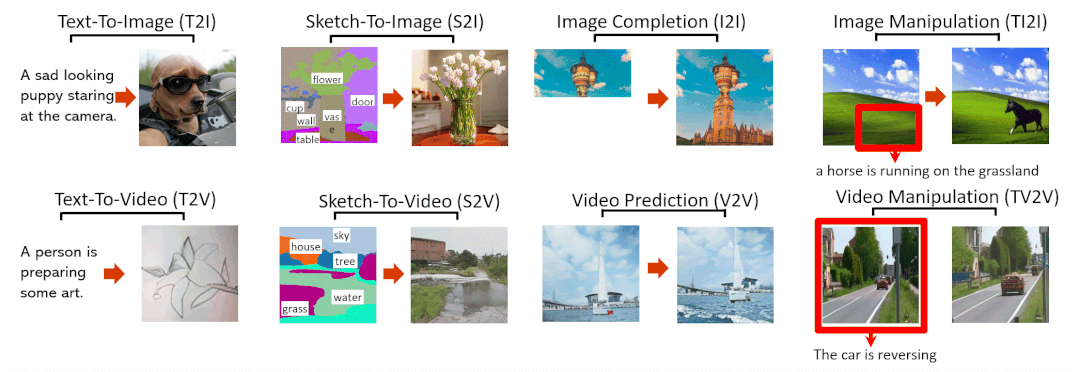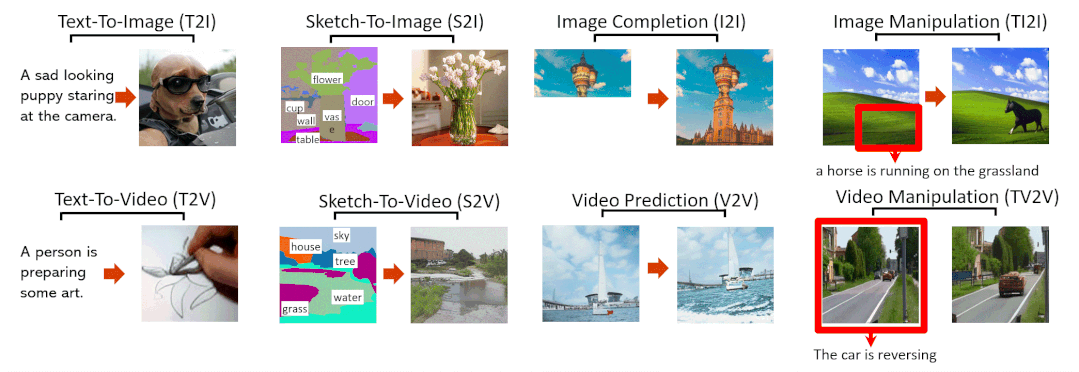
NÜWA模型支持的8种典型视觉生成任务
8大SOTA效果抢先看
文字转图像(Text-To-Image,T2I)

草图转图像(SKetch-to-Image,S2I)

图像补全(Image Completion,I2I)

用文字指示修改图像(Text-Guided Image Manipulation,TI2I)
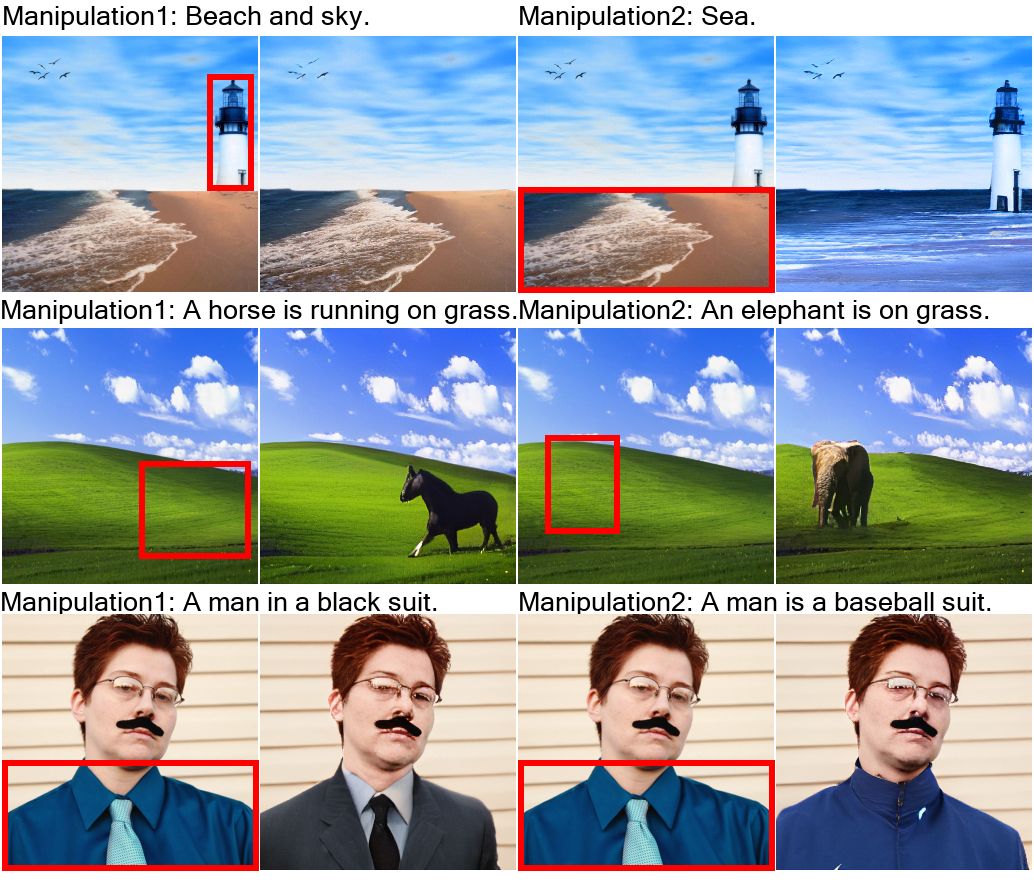
文字转视频(Text-to-Video,T2V)
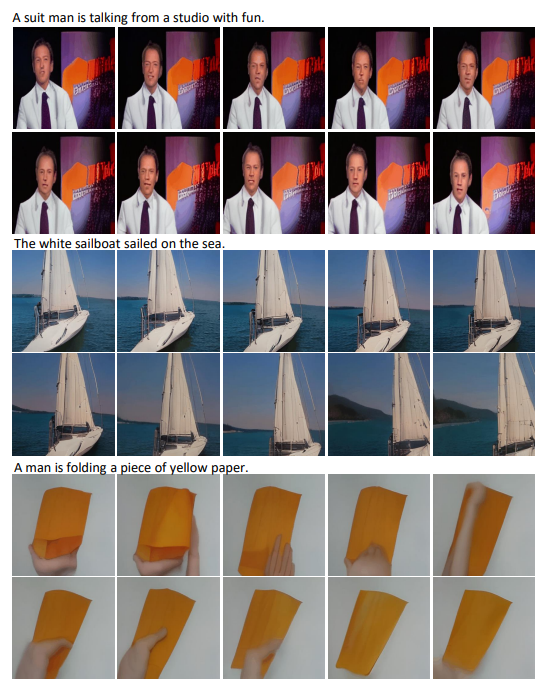
视频预测(Video Prediction,V2V)

草图转视频(Sketch-to-Video,S2V)

用文字指示修改视频(Text-Guided Video Manipulation,TV2V)

NÜWA为啥这么牛?
NÜWA模型的整体架构包含一个支持多种条件的adaptive编码器和一个预训练的解码器,能够同时使图像和视频的信息。
对于图像补全、视频预测、图像处理和视频处理任务,将输入的部分图像或视频直接送入解码器即可。
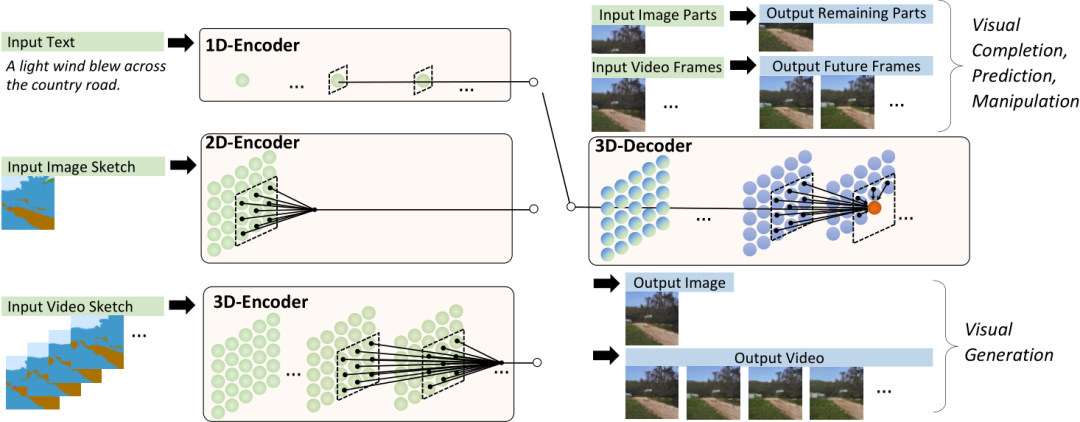
NÜWA的结构概述
模型支持所有文本、图像、视频输入,并将他们统一视作token输入,所以可以定义一个统一的向量表示X,维度包括高度h、宽度w,时间轴上的token数量s,每个token的维度d。
文本天然就是离散的,所以使用小写后的byte pair encoding (BPE)来分词,最终的维度为1×1×s×d中。因为文本没有空间维度,所以高度和宽度都为1。
图像输入是连续的像素。每个图像输入的高度为h、宽度为w和通道数为c。使用VQ-VAE训练一个编码把原始连续像素转换为离散的token,训练后B[z]的维度为h×w×1×d作为图像的表示,其中1 代表图像没有时序维度。
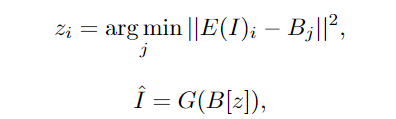
视频可以被视为图像的一种时序展开,最近一些研究如VideoGPT和VideoGen将VQ-VAE编码器中的卷积从2D扩展到3D,并能够训练一种针对视频输入的特殊表征。
但这种方法无法使图像和视频的表示统一起来。研究人员证明了仅使用2D VQ-GAN 就能够编码视频中的每一帧,并且能生成时序一致的视频,结果表示维度为h×w×s×d,其中s代表视频的帧数。
对于图像素描(image sketch)来说,可以将其视为具有特殊通道的图像。
H×W的图像分割矩阵中每个值代表像素的类别,如果以one-hot编码后维度为H×W×C,其中c是分割类别的数目。通过对图像素描进行额外的VQ-GAN训练,最终得到图像embedding表示维度为 h×w×1×d。同样地,对于视频草图的embedding维度为h×w×s×d。

基于统一的3D表示,文中还提出一种新的注意力机制3D Nearby Self-Attention (3DNA) ,能够同时支持self-attention 和cross-attention。
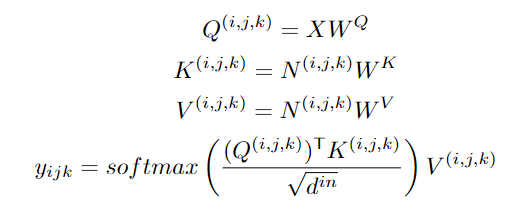
3DNA考虑了完整的邻近信息,并为每个token动态生成三维邻近注意块。注意力矩阵还显示出3DNA的关注部分(蓝色)比三维块稀疏注意力和三维轴稀疏注意力更平滑。
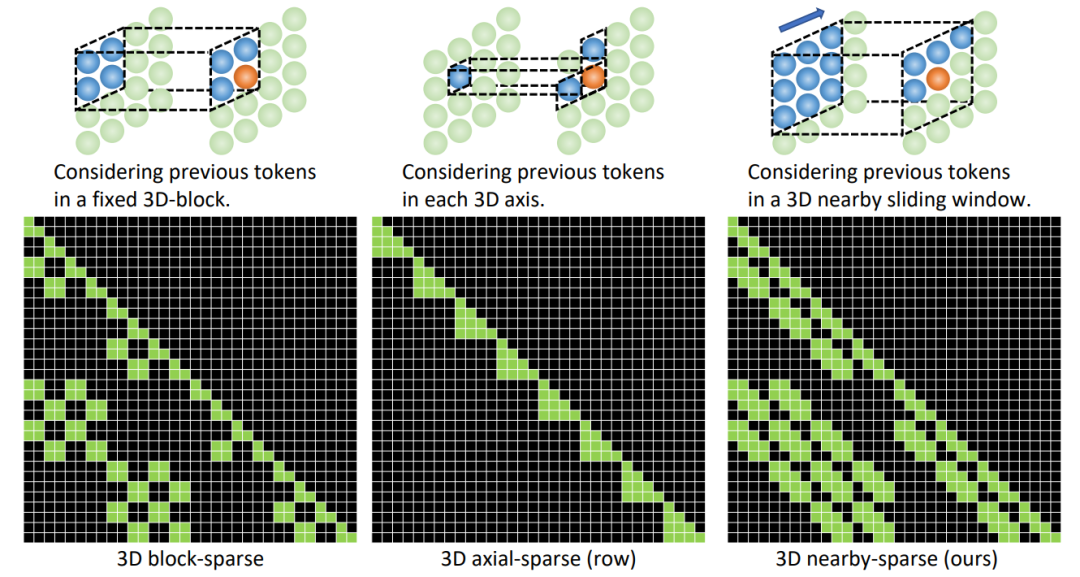
不同的三维稀疏注意力机制的比较
基于3DNA,文中还引入了3D encoder-decoder,能够在条件矩阵Y 为h'×w'×s'×d^{in}的情况下,生成h×w×s×d^{out} 的目标矩阵C,其中Y和C由三个不同的词典分别考虑高度,宽度和时序维度。
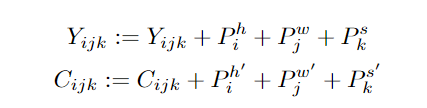
然后将条件C和一个堆叠的3DNA层输入到编码器中来建模自注意力的交互。
解码器也是由3DNA层堆叠得到,能够同时计算生成结果的self-attention和生成结果与条件之间的cross-attention。
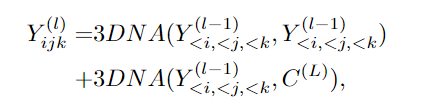
最终的训练包含了三个目标任务Text-to-Image(T2I), Video Prediction (V2V) 和Text-to-Video(T2V),所以目标函数包含三部分。
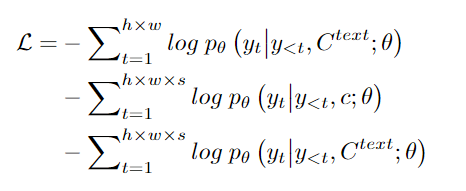
对于T2I和T2V任务,C^text表示文本条件。对于V2V任务,由于没有文本输入,所以c为一个常量,单词None的3D表示,θ表示模型参数。
实验结果
文本转图像(T2I)
作者使用FID-k和Inception Score(IS)来分别评估质量和种类,并使用结合了CLIP模型来计算语义相似度的CLIPSIM指标。
公平起见,所有的模型都使用256×256的分辨率,每个文本会生成60张图像,并通过CLIP选择最好的一张。
可以看到,NÜWA以12.9的FID-0和0.3429的CLIPSIM成绩,明显地优于CogView。
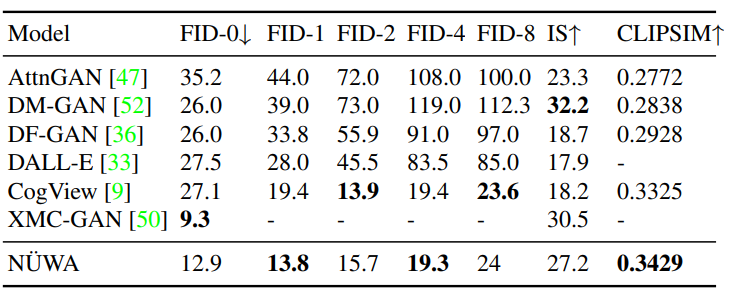
在MSCOCO(256×256)数据集上与SOTA的定量比较
尽管XMC-GAN的FID分数为9.3,但与XMC-GAN的论文中完全相同的样本相比,NÜWA生成的图像更加真实。特别是在右下角的那个例子中,男孩的脸更清晰,气球也是正确的。

在MSCOCO(256×256)数据集上与SOTA的定性比较
文本转视频(T2V)
作者在Kinetics数据集上与现有的SOTA进行了比较,其中,在FID-img和FID-vid指标上评估视觉质量,在生成视频的标签准确性上评估语义一致性。
显然,NÜWA在上述所有指标上都取得了SOTA。
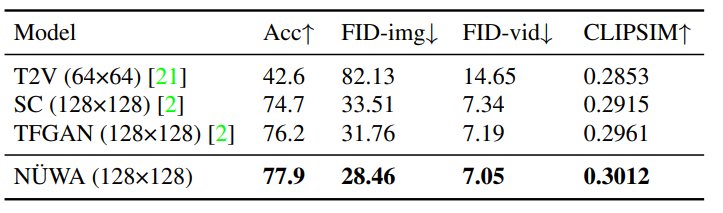
在Kinetics数据集上与SOTA的定量比较
此外,对于生成未见过的文本来说,NÜWA在定性比较中显示出了强大的zero-shot能力,如「在游泳池打高尔夫球」以及「在海上跑步」。

在Kinetics数据集上与SOTA的定性比较
图像补全(I2I)
作者定性地比较了NÜWA的zero-shot图像补全能力。
在只有塔的上半部分的情况下,与Taming Transformers相比,NÜWA在对塔的下半部分进行补全时,展现出更丰富的想象力,自主添加了建筑、湖泊、鲜花、草地、树木、山脉等等。

以zero-shot方式与现有SOTA进行定性比较
视频预测(V2V)
作者在BAIR数据集上进行了定量比较,其中,Cond.表示预测未来帧的帧数。
为了进行公平的比较,所有的模型都使用64×64的分辨率。尽管只给了一帧作为条件(Cond.),NÜWA仍将FVD的SOTA得分从94±2推至86.9。
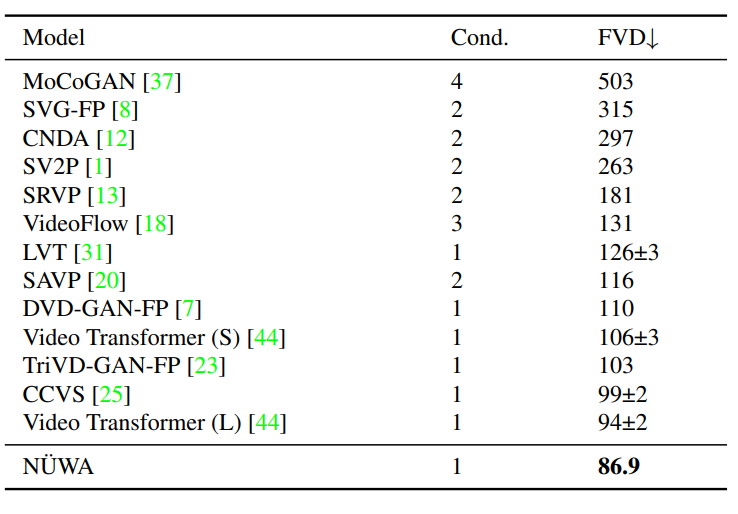
在BAIR(64×64)数据集上与SOTA的定量比较
草图转图像(S2I)
通过定性比较在MSCOCO上的表现可以看到,与Taming-Transformers和SPADE相比,NÜWA生成的图像种类更多,有的甚至连窗户上的反射也清晰可见。

在MSCOCO数据集上与SOTA的定性比较
用文本引导图像修改(TI2I)
作者以zero-shot的方式对NÜWA和现有SOTA进行了定性的比较。
与Paint By Word相比,NÜWA表现出了很强的编辑能力,在不改变图像其他部分的情况下,产生了高质量的结果。这得益于通过对各种视觉任务进行多任务预训练而学到的真实世界的视觉模式。
比如在第三个例子中,由NÜWA生成的蓝色卡车更加逼真,而且后方的建筑物也没有产生奇怪的变化。
另一个优点是NÜWA的推理速度,只需要50秒就能生成一幅图像,而Paint By Words在推理过程中需要额外的训练,并需要大约300秒才能收敛。

以zero-shot方式与现有SOTA进行定性比较
结论
文章提出了一种统一的预训练模型NÜWA,这个女娲不光能补天,也能造图,可以为8个视觉合成任务生成新的或操作现有的图像和视频。
还提出了一个通用的3D encoder-decoder框架,能够同时覆盖文本、图像和视频。能同时考虑空间和时序维度的3D nearby-sparse attention机制。
这也是迈向人工智能平台的重要一步,能够让计算机拥有视觉,并辅助内容创作者生成一些人类想象力以外的事。
ICCV和CVPR 2021论文和代码下载后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()
这篇关于这个「女娲」模型火了!怒刷8项SOTA!MSRA和北大提出NÜWA:图像、视频生成大一统!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






