大一统专题

Mamba 2的发布是否可以撼动Transformer模型的AI大一统的江湖地位
Transformer模型 Transformer模型是深度学习领域的一种神经网络架构,特别适用于自然语言处理(NLP)任务。它由Vaswani等人在2017年的论文《Attention is All You Need》中提出。Transformer模型的关键创新在于其使用注意力机制,而不是传统的递归神经网络(RNN)或卷积神经网络(CNN)来处理序列数据。正是由于Transformer模型强大

语言图像模型大一统!Meta将Transformer和Diffusion融合,多模态AI王者登场
【导读】 就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了! Transformer和Diffusion,终于有了一次出色的融合。 自此,语言模型和图像生成大一统的时代,也就不远了! 这背后,正是Meta最近发布的Tran

OpenAi 免费GPT-4o来袭,音频视觉文本实现「大一统」
今天凌晨,即北京时间5月14日1点整,OpenAI 召开了首场春季发布会,CTO Mira Murati 在台上和团队用短短不到30分钟的时间,揭开了最新旗舰模型 GPT-4o 的神秘面纱,以及基于 GPT-4o 的 ChatGPT,均为免费使用。 此前,有传言称 OpenAI 将推出 AI 搜索引擎,旨在与谷歌明天举办的 I/O 开发者大会一较高下,一度引发了公众的热烈讨论。 不过 Sam
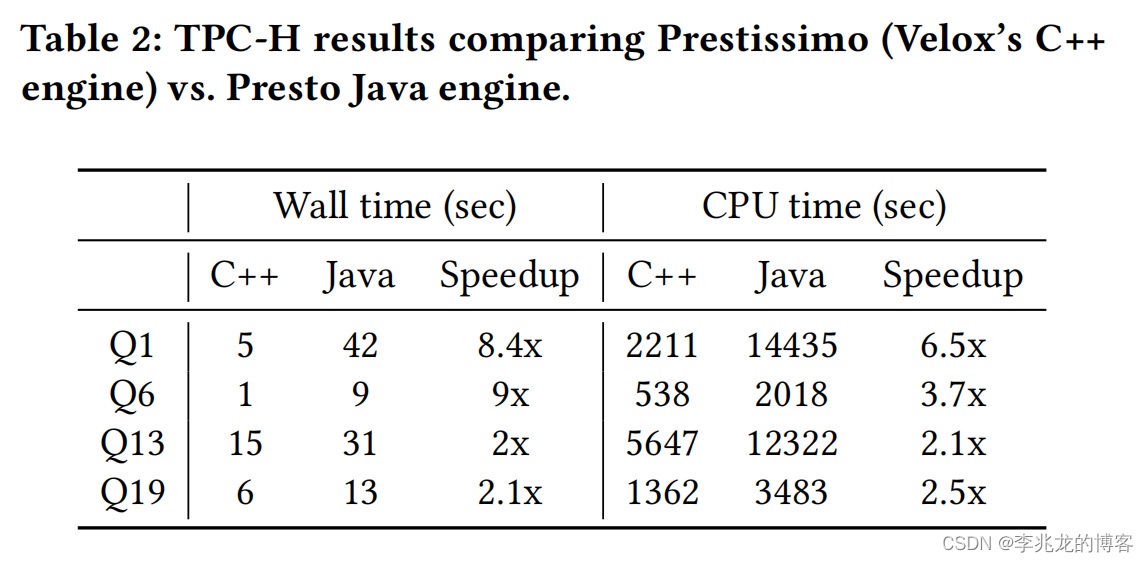
从一到无穷大 #26 Velox:Meta用cpp实现的大一统模块化执行引擎
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言业务案例PrestoSparkXStreamDistributed messaging systemData IngestionData PreprocessingFeature Engineering 组件T

【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录 一、像素级OCR统一模型:UPOCR1.1、为什么提出UPOCR?1.2、UPOCR是什么?1.2.1、Unified Paradigm 统一范式1.2.2、Unified Architecture统一架构1.2.3、Unified Training Strategy 统一训练策略 1.3、UPOCR效果如何? 二、OCR大一统模型前沿研究速览2.1、Donut:无需OCR的用于文档理

华为新系统鸿蒙加油,华为鸿蒙需加油,微软新系统win10X或要实现大一统了
众所周知,去年8月份,华为发布了万众瞩目的新系统鸿蒙系统,当时说这个系统是一个大一统的系统,支持手机、平板、电脑、自驾驾驶、物联网等等。 而在当时这个理念是非常先进的,因为不管是微软、还是谷歌的系统都没有实现这个功能,所以很多人认为这就是鸿蒙系统,也是华为的厉害之处。 不过后面华为鸿蒙基本上也只用在了一些边缘设备上,比如手表、电视等,在手机、电脑上并没有使用,预计还需要一些不短的时间才行。 后
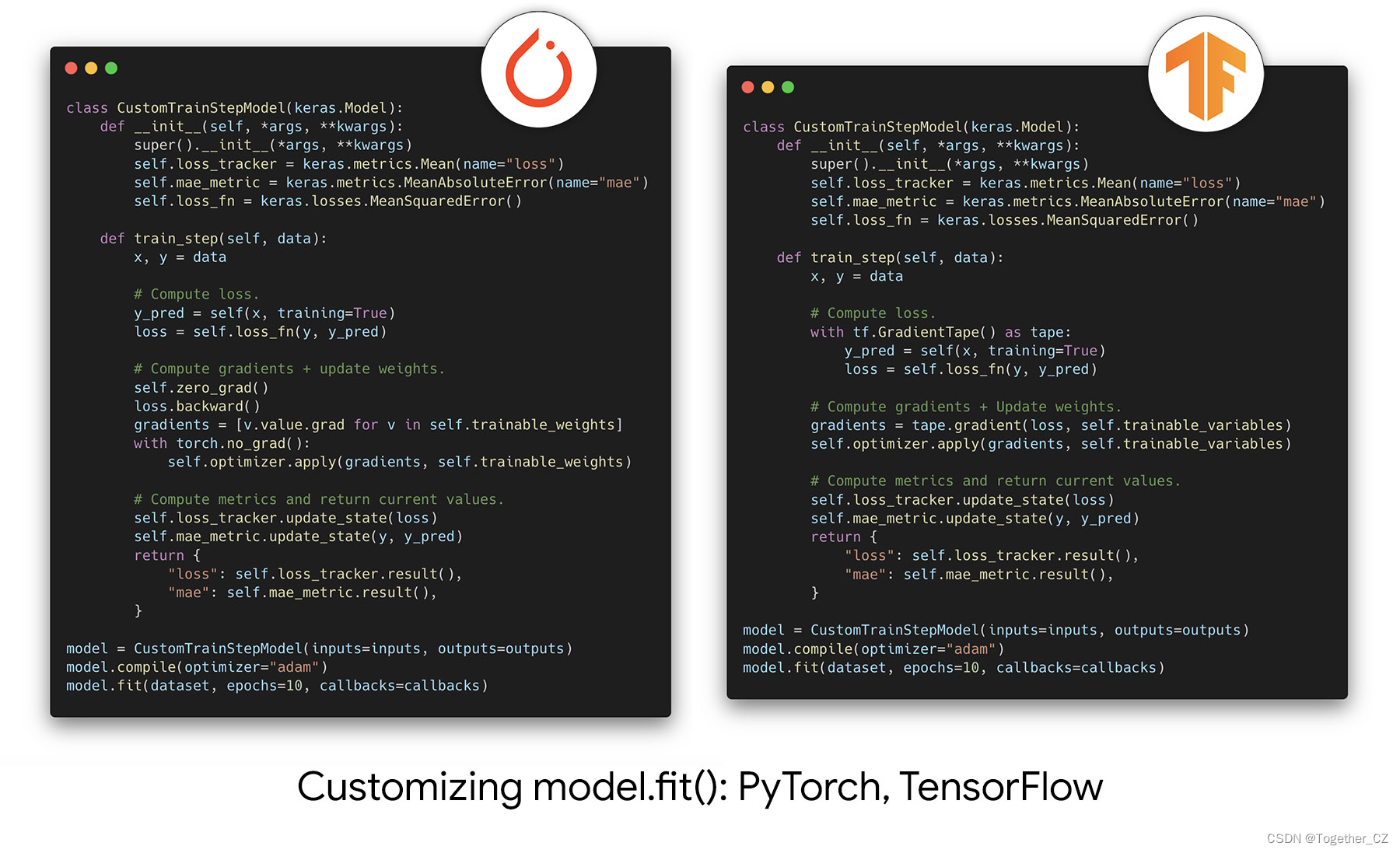
一觉醒来!Keras 3.0史诗级更新,大一统深度学习三大后端框架【Tensorflow/PyTorch/Jax】
不知道大家入门上手机器学习项目是首先入坑的哪个深度学习框架,对于我来说,最先看到的听到的就是Tensorflow了,但是实际上手做项目开发的时候却发现了一个很重要的问题,不容易上手,基于原生的tf框架来直接开发模总是有不小的难度,后来发现了Keras,简直就是深度学习的福音,本质上来讲,Keras是对后端深度学习框架的高级封装。 框架介绍 当涉及深度学习和机器学习时,TensorFlow、Py

大一统模型 Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记
Universal Instance Perception as Object Discovery and Retrieval 论文阅读笔记 一、Abstract二、引言三、相关工作实例感知通过类别名进行检索通过语言表达式的检索通过指代标注的检索 统一的视觉模型Unified Learning ParadigmsUnified Model Architectures 四、方法4.1 Pro

多模态大一统:通向全模态学习和通用人工智能的未来之路
随着AI技术的不断发展,研究者们正试图构建一种真正通用的人工智能,它能像人们那样以统一的方式处理和理解多种模态的信息。多模态大一统是这一愿景的关键,它旨在开启全模态LLM(深度学习语言模型)和通用AI时代的大门。在本文中,我们将详细探讨实现多模态模型的现有方法、面临的挑战以及建立全模态学习模型的潜在收益。 目前多模态实现的方法 目前,多模态模型的实现方法主要包括单独训练各领域模型、多任务学习、

多模态大一统:通向全模态学习和通用人工智能的未来之路
随着AI技术的不断发展,研究者们正试图构建一种真正通用的人工智能,它能像人们那样以统一的方式处理和理解多种模态的信息。多模态大一统是这一愿景的关键,它旨在开启全模态LLM(深度学习语言模型)和通用AI时代的大门。在本文中,我们将详细探讨实现多模态模型的现有方法、面临的挑战以及建立全模态学习模型的潜在收益。 目前多模态实现的方法 目前,多模态模型的实现方法主要包括单独训练各领域模型、多任务学习、

这个「女娲」模型火了!怒刷8项SOTA!MSRA和北大提出NÜWA:图像、视频生成大一统!...
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 本文转载自:新智元 编辑:好困 小咸鱼 LRS 【导读】微软亚洲研究院、北京大学强强联合提出了一个可以同时覆盖语言、图像和视频的统一多模态预训练模型——NÜWA(女娲),直接包揽8项SOTA。其中,NÜWA更是在文本到图像生成中完虐OpenAI DALL-E。5天github项目,已获得1000+ star! 太卷了,太卷

IRGAN:大一统信息检索模型的博弈竞争
2017年SIGIR一篇满分论文,论文链接: https://arxiv.org/abs/1705.10513 作者: 汪军 张伟楠等 主要思想:把gan用在信息检索上面,一个生成模型,一个判别对抗模型 摘要 统一了两大学术派理论:计算一个文档跟query的相关性,辨别query跟文档对的相关性;提出了一个最大最小理论来优化这两个模型,判别模型从标记数据以及未标记数据挖掘数据来

广告行业中那些趣事系列55:文本和图像领域大一统的UNIMO模型详解
导读:本文是“数据拾光者”专栏的第五十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍了百度在多模态学习领域的成果UNIMO模型,对多模态学习感兴趣并且希望应用到项目实践的小伙伴可能有所帮助。 欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。 知乎专栏:数据拾光者 公众号:数据拾光者 摘要:本篇主要介绍了百度在多模态学习领域