本文主要是介绍OpenAi 免费GPT-4o来袭,音频视觉文本实现「大一统」,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天凌晨,即北京时间5月14日1点整,OpenAI 召开了首场春季发布会,CTO Mira Murati 在台上和团队用短短不到30分钟的时间,揭开了最新旗舰模型 GPT-4o 的神秘面纱,以及基于 GPT-4o 的 ChatGPT,均为免费使用。
此前,有传言称 OpenAI 将推出 AI 搜索引擎,旨在与谷歌明天举办的 I/O 开发者大会一较高下,一度引发了公众的热烈讨论。
不过 Sam Altman 随后在 X(原推特)上表示,要展示的并非 GPT-5 或搜索引擎,而是一些令人期待的创新成果,他本人对此充满期待,认为其像魔法一样神奇。
那么,GPT-4o 是否真的如 Sam Altman 所说,是 OpenAI 带来的「新魔法」呢?
1
多模态实时语音助手
更快更全更有情感
登台后,Mira Murati 宣布了 ChatGPT 的桌面版本和新 UI,紧接着就介绍了本场发布会的主角——GPT-4o 。
在发布会上,Mira Murati 与团队成员 Mark Chen、Barret Zoph一起,重点展示了基于 GPT-4o 的 ChatGPT 在不同任务中的实际表现,尤其展现了其语音能力。
若用关键词加以总结,搭载 GPT-4o 的 ChatGPT 可谓是又快、又全、又有情感。
与 ChatGPT 对话时,用户不必等 ChatGPT 说完,可以随时插话;模型能够实时响应,不存在尴尬的几秒延迟。
在 Mark 表示自己很紧张且捕捉到他急促的呼吸后,ChatGPT 还会提醒需要冷静情绪,识别其呼吸节奏并引导他做深呼吸。

模型能够以各种不同的风格生成声音。无论对话时让 ChatGPT 用唱歌的方式、机器人机械音还是戏剧化的语气讲故事,它都能迅速反应并输出。
基于 GPT-4o 强大的视觉能力,用户还可以语音让 ChatGPT 分析页面上的数据图表。
更强大的是,打开摄像头后写下一道数学题,ChatGPT 还会一步步引导该如何解下一步,其讲解的清晰度与耐心堪比幼教。

ChatGPT的「同传能力」也不容小觑,OpenAI 团队还在现场展示了一波英语和意大利语的实时互译,中间实现零延迟。
更有意思的是,ChatGPT 在对话中还会使用语气词,甚至是向 OpenAI 团队开玩笑和表达感谢。在「看到」他们写下「我爱 ChatGPT」的文字后,ChatGPT 甚至会在发出撒娇的声音后,再表扬其贴心。

ChatGPT 甚至还能和用户「视频聊天」。在演示中,Barret 让 ChatGPT 猜测自己的情绪,在他开始露出笑脸后,ChatGPT 直接语音回复「你看起来很开心,笑容灿烂,还有点激动。」

英伟达首席 AI 科学家 Jim Fan 曾讲述过当前实时语音助手(如 Siri )的困境,即很难创造出沉浸式的使用体验。
用户在和 AI 语音助手对话时要经历三个阶段:语音识别(ASR),将音频转换为文本,例如 Whisper;大语言模型(LLM)规划接下来的话语,将第一阶段的文本转换为新的文本; 语音合成(TTS),将新文本转换回音频,如 ElevenLabs 或 VALL-E 。
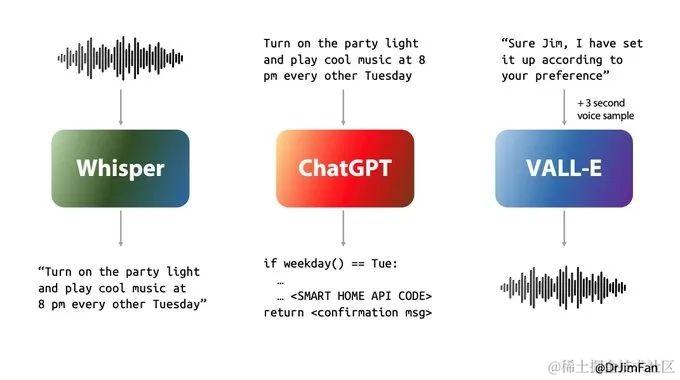
如果简单地按顺序执行,就会产生巨大的延迟,特别是当每一步都需要等待几秒时,用户体验就会急剧下降,哪怕合成的音频听起来非常真实,也会让用户格外「出戏」,就更别提沉浸式的使用体验了。
以往的 ChatGPT 语音模式也是如此,依赖三个独立模型工作,平均延迟时间为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4),语音助手也总会出现信息丢失,既不能判断语调、多个说话者或背景噪音,也不能输出笑声、唱歌或表达情感。
而现在,GPT-4o 的音频输入响应时间最短为232毫秒,平均响应时间为320毫秒,与人类在对话中的反应时间极为相似。
作为一个全新的单一模型,GPT-4o 能端到端地跨文本、视觉和音频,所有输入和输出都由同一个神经网络处理,直接一步到位,在用户输入后(文本、语音、图像、视频均可)直接生成音频回答。
2
GPT-4o
一款免费的全能 GPT-4
Mira Murati 在发布会上表示,GPT-4o 最棒的地方在于,它将 GPT-4 的智能提供给每个人,包括免费用户,将在未来几周内迭代式地在公司产品中推出。
GPT-4o 中的字母 o 指 omni,在拉丁语词根中是「全」的意思,是涵盖了文字、语音、图片、视频的多模态模型,接受任何模态的组合作为输入,并能生成任何模态的组合输出。
据 OpenAI 官网,GPT-4o 不仅在文本和代码处理的性能上与GPT-4 Turbo持平,而且在 API 调用上速度更快,价格更是降低了50%。
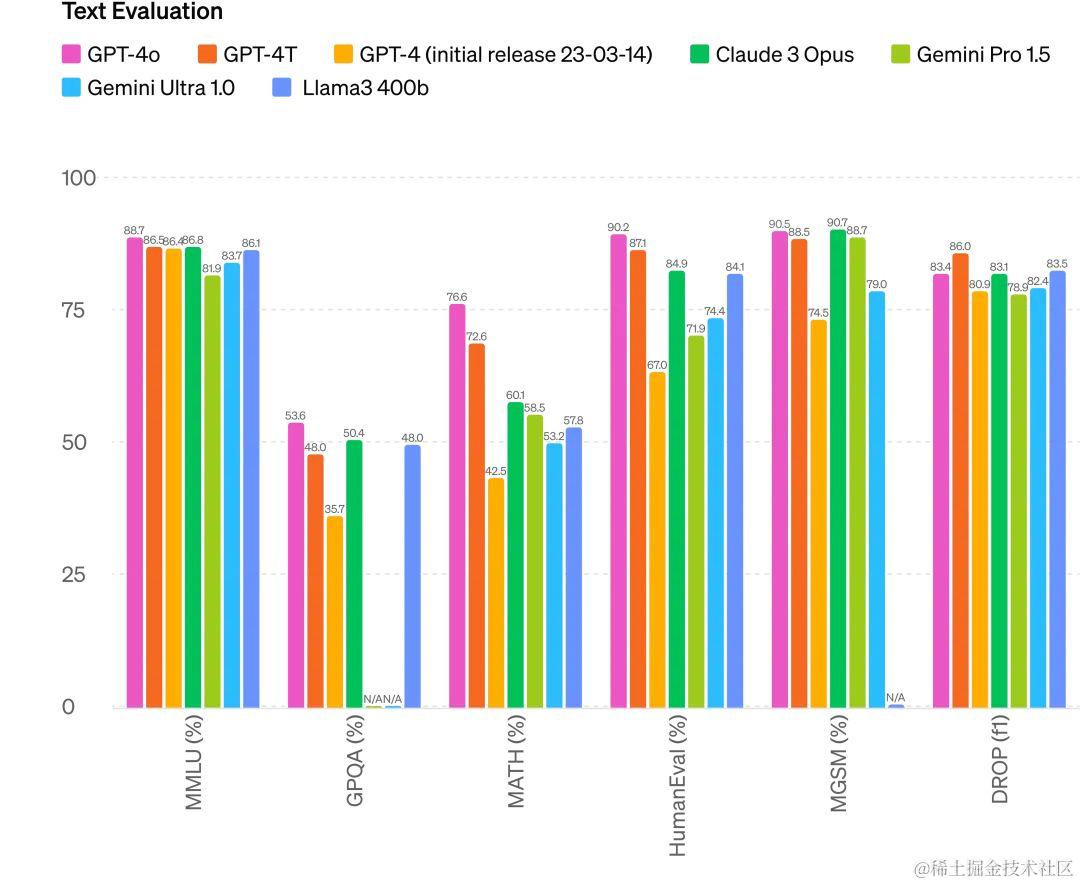
文本能力测试
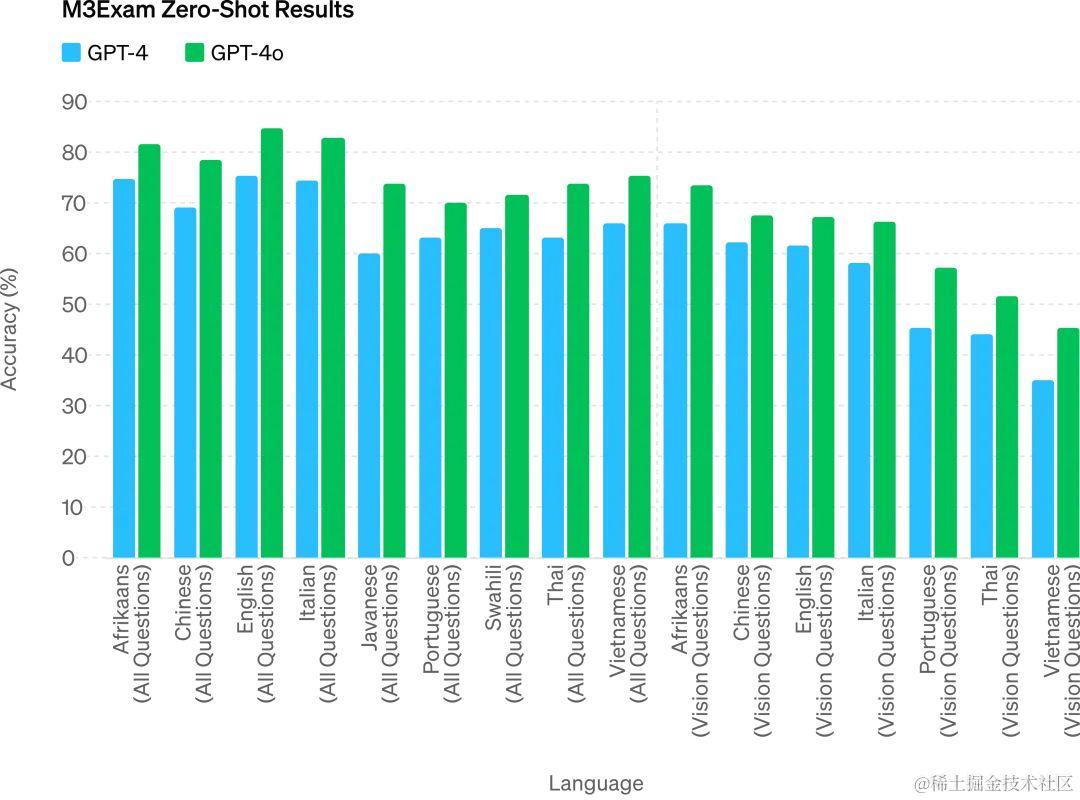
与GPT-4对比多语言考试能力
更重要的是,GPT-4o 的视觉理解能力在相关基准上取得了压倒性的胜利。
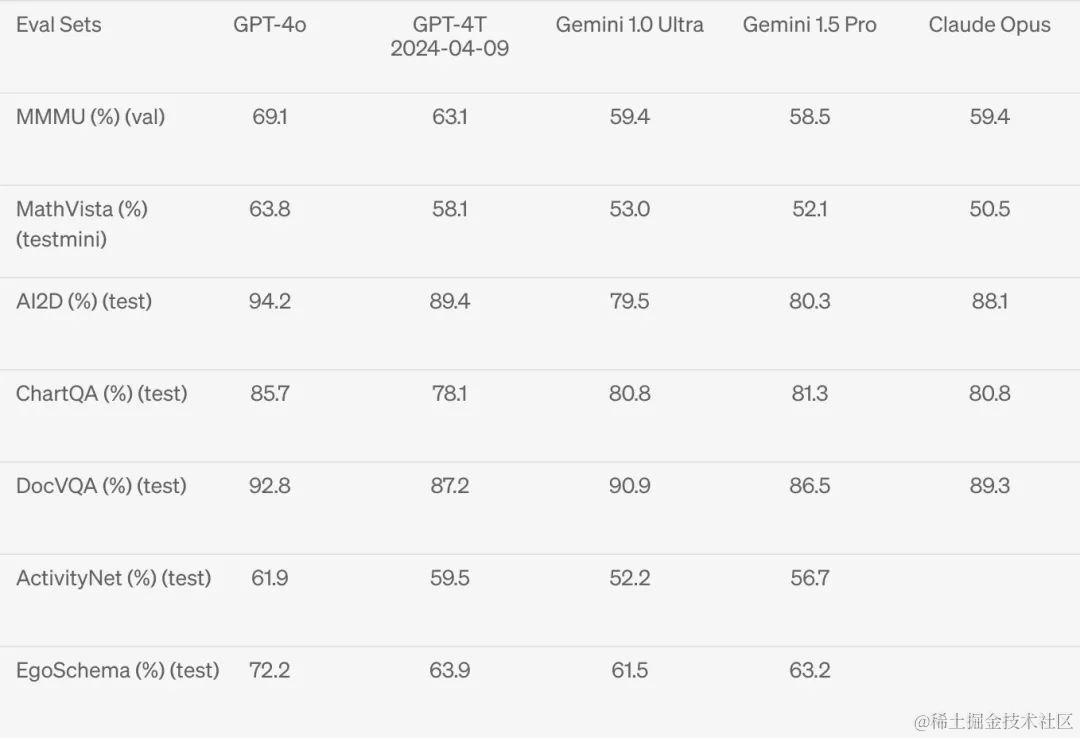
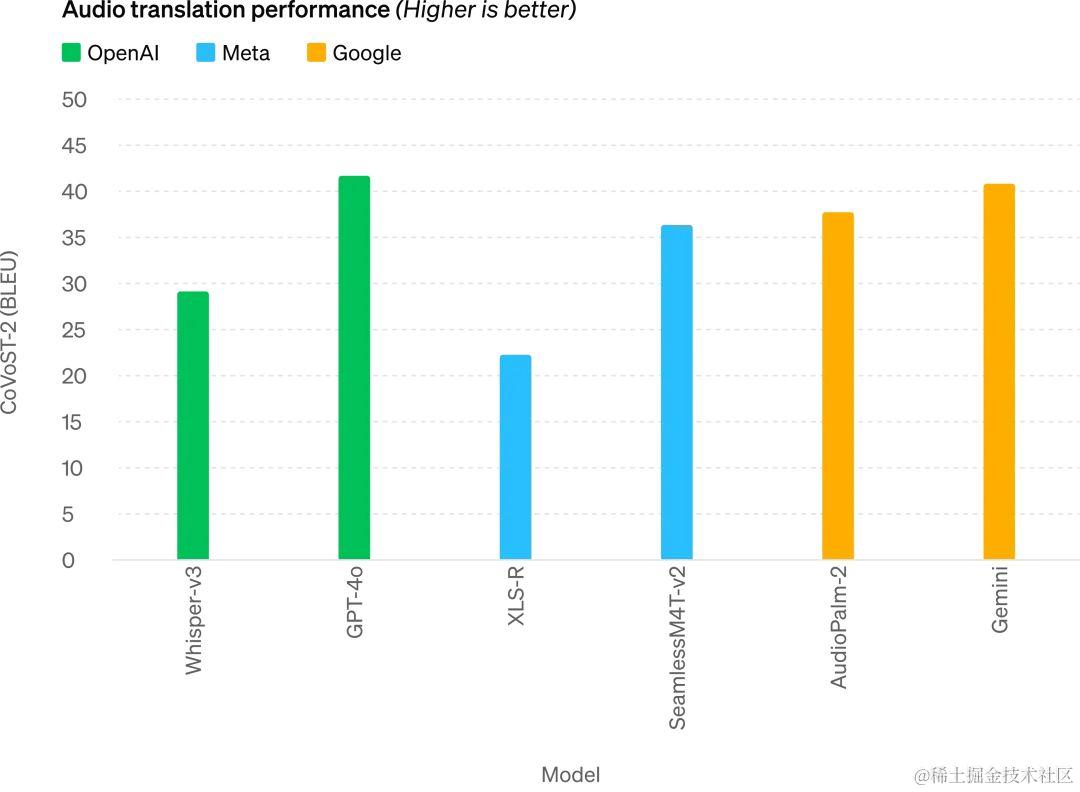
在音频方面,GPT-4o 的语音识别(ASR)也比 OpenAI 的语音识别模型 Whisper 性能更佳(越低越好)。

与 Meta、谷歌的语音转写模型相比,GPT-4o 同样领先(越高越好)。
若落实到实际生活的使用中,GPT-4o 究竟能给普罗大众带来什么变化呢?
OpenAI的官网展示了 GPT-4o 在海报创作、三维重建、字体设计、会议总结等等一系列充满可能性的应用。
比如,在输入人物图片、海报元素以及想要的风格后,GPT-4o 就能给用户生成一张电影海报。




或者,根据输入的诗歌文本,GPT-4o 能生成用手写体写着诗歌、画着画的单行本图片。


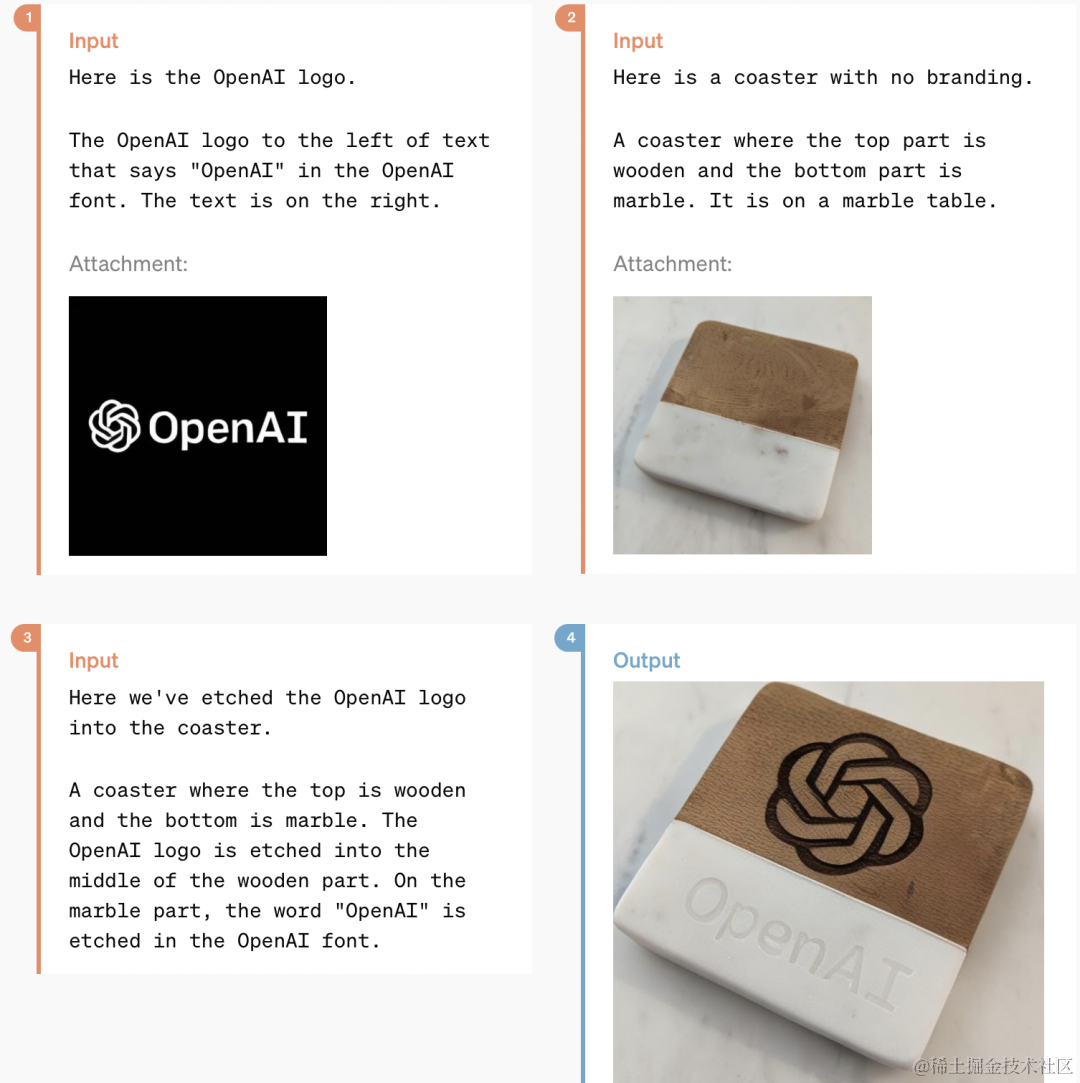
在输入6张 OpenAI 的 logo图后,GPT-4o 能三维重建出其立体动图。

甚至还可以让 GPT-4o 帮忙把 logo 印在杯垫上。
「今天,有 1 亿人使用 ChatGPT 来创作、工作、学习,以前这些高级工具只对付费用户可用,但现在,有了 GPT-4o 的效率,我们可以将这些工具带给每个人。」Mira Murati 如是说道。
3
写在后面
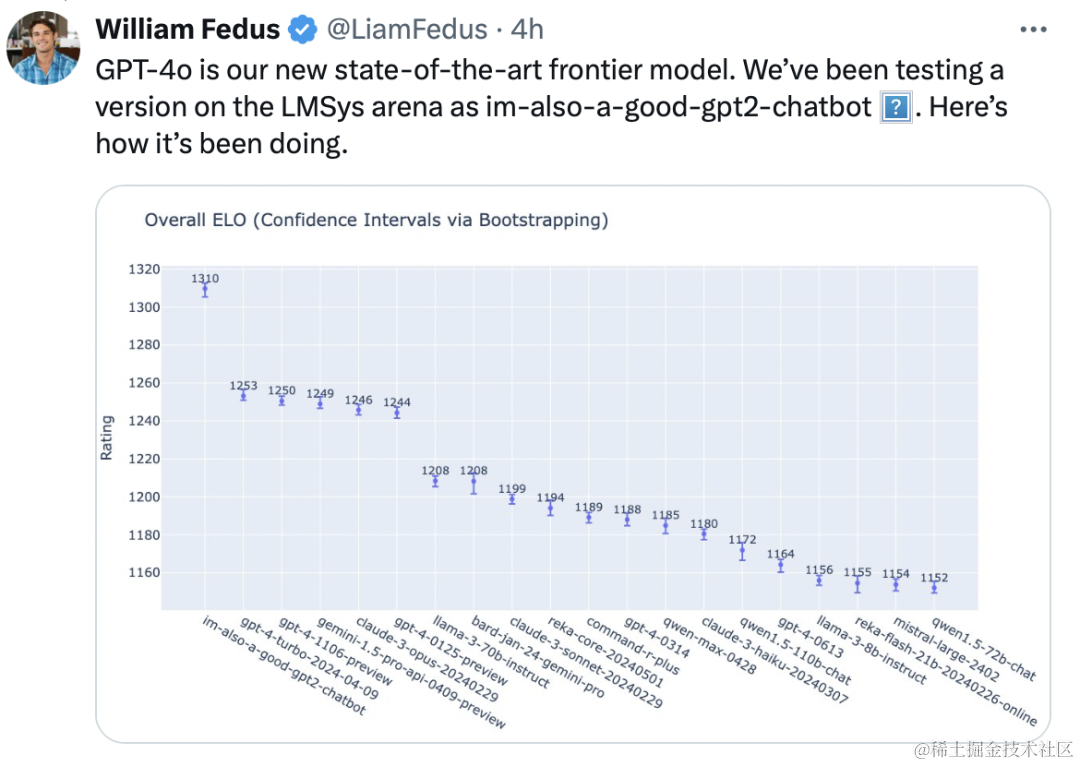
发布会之外,OpenAI 研究员 William Fedus 透露,此前在大模型竞技场参与A/B测试并碾压全场的模型「im-also-a-good-gpt2-chatbot」,就是本次登场的 GPT-4o 。
截至2024年3月,OpenAI 在不到十年的运营时间内,已经完成了10轮的融资,累计筹集资金超过了140亿美元,其估值在2月的融资交易中已经飙升至800亿美元。
伴随着狂飙的市值,OpenAI 的技术版图已经横跨了多个 AI 的关键领域,形成了一个全面而深入的产品矩阵。
API 产品线提供了包括 GPT 模型、DALL·E 模型、Whisper 语音识别模型在内的多样化服务,并通过对话、量化、分析、微调等高级功能,为开发者提供技术支持;ChatGPT 为核心的产品线分别推出了个人版和企业版。
在音乐生成领域,OpenAI 也有一定的技术积累,比如经过训练的深度神经网络 MuseNet,可预测并生成 MIDI 音乐文件中的后续音符,以及能生成带人声音乐的开源算法 Jukebox。
再加上年初春节假期期间毫无征兆推出的 AI 视频生成大模型 Sora,更是让网友们感叹「现实,不存在了。」
毋庸置疑,OpenAI 是大模型这场擂台赛中当之无愧的擂主,其技术与产品的迭代更是整个行业的风向标,不少大模型创业者都遇过「OpenAI 不做,没人投;OpenAI 一做,人人投」的融资奇观。
但随着 Claude 3 和 Llama 3 的紧追与 GPT Store 上线2个月惨遭「滑铁卢」,不少 AI 行业从业者开始对 OpenAI 祛魅,认为「大模型护城河很浅,一年就赶上了。」
现在看来,OpenAI 果然还是 OpenAI。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

这篇关于OpenAi 免费GPT-4o来袭,音频视觉文本实现「大一统」的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




