本文主要是介绍广告行业中那些趣事系列55:文本和图像领域大一统的UNIMO模型详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读:本文是“数据拾光者”专栏的第五十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍了百度在多模态学习领域的成果UNIMO模型,对多模态学习感兴趣并且希望应用到项目实践的小伙伴可能有所帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇主要介绍了百度在多模态学习领域的成果UNIMO模型。首先是背景介绍,针对当前主流多模态学习模型存在训练语料少和模态缺失导致模型效果下降的问题,百度提出了UNIMO统一学习模型;然后重点介绍了UNIMO模型,主要包括UNIMO如何解决训练数据稀少和模态缺失问题、UNIMO模型输入、跨模态对比学习的UNIMO、UNIMO中视觉学习和文本学习以及UNIMO模型效果;最后介绍了UNIMO开源项目工程。对多模态学习感兴趣并且希望应用到项目实践的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:
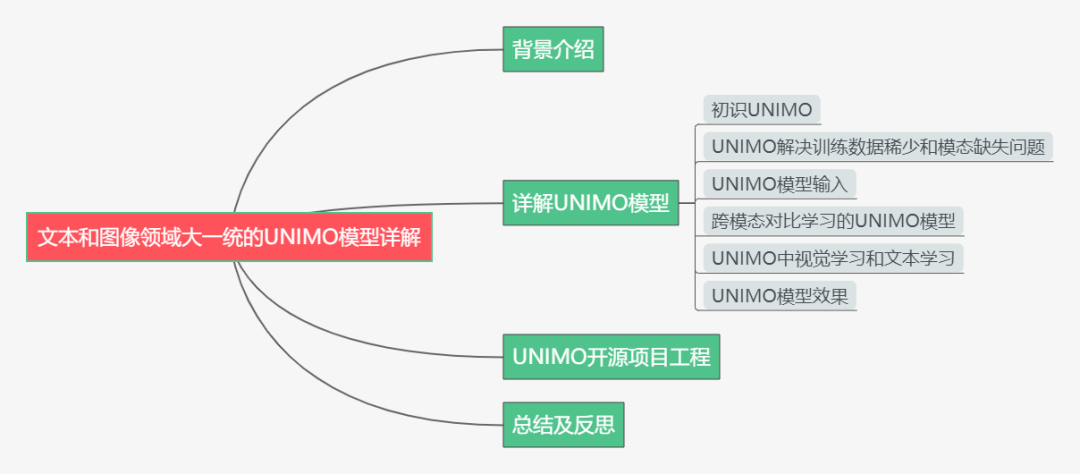
01
背景介绍
上一篇《广告行业中那些趣事系列54:从理论到实践学习当前超火的多模态学习模型》介绍了当前比较主流的多模态学习模型,包括VisualBERT、Unicoder-VL、VL-BERT和ViLT等,这一类模型虽然在多模态领域效果较好,但是也存在明显的缺点:一方面,训练数据只能用图像-文本对数据,而实际情况是高质量的图像-文本对数据比较少,导致模型可用的训练语料较少,限制模型的通用性和效果;另一方面,这一类模型在模态缺失的情况下效果下降非常明显。针对传统多模态学习模型存在的问题,业界希望得到一个真正意义上的多模态学习模型,可以统一学习文本和图像知识,不仅能很好的应对模态缺失的问题,而且能更好的利用图像和文本的知识超过单模模型。
02
详解UNIMO模型
2.1 初识UNIMO
UNIMO是百度2022年3月在《UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning》论文中提出来的,核心是提出了一个统一模态预训练框架,利用海量的文本和图像数据,通过跨模态的对比学习方法将文本和图像映射到统一空间中,从而提升视觉和文本的理解能力。
2.2 UNIMO解决训练数据稀少和模态缺失问题
前面说过传统的多模态学习模型使用的训练语料是文本-图像对数据,虽然高质量的文本-图像对数据非常少,但是单模的文本数据和图像数据非常多,如果可以利用海量的单模数据,将文本和图像映射到统一空间中,提升视觉和文本的理解能力,则可以大大提升多模态学习模型的效果。举例说明,对于下图中的问答任务来说,根据图像的内容来回答给定的问题,通过单模文本语料数据(比如wikipedia)额外提供的知识可以大大提升模型在问答任务中的效果。下面是问答任务使用单模文本语料辅助任务示例:

图1 问答任务使用单模文本语料辅助任务示例
为了使用海量文本和图像数据,同时解决模态缺失带来的模型效果下降问题,UNIMO提出了统一模态预训练框架,可以同时支持文本、图像和文本-图像对三种不同类型的数据输入,使用统一堆叠的Transformer模型,将文本和图像表示映射在统一表示空间中,下面是UNIMO统一模态预训练框架图:

图2 UNIMO统一模态预训练框架图
2.3 UNIMO模型输入
为了将文本和图像表示映射在统一表示空间中,UNIMO模型输入主要包括三部分内容:
文本输入:UNIMO文本输入和BERT类似,通过字节对编码(BPE, Byte Pair Encoder)将文本转化成token embedding,开始和结束分别添加【CLS】和【SEP】标志,得到序列{h[CLS], hw1, ..., hwn, h[SEP]};
图像输入:将图片采用Faster R-CNN算法提取兴趣图像区域的特征,通过自注意力机制得到上下文相关的区域特征embedding表征序列{h[IMG], hv1, ..., hvt};
文本-图像对输入:和传统多模态学习模型类似,将文本-图像对数据(V,W)分别得到文本对应的textual embed和图像对应的visual embed,然后进行拼接得到序列{[IMG], v1, ..., vt, [CLS], w1, ..., wn, [SEP]},获取文本-图像对数据的embedding如下图所示:
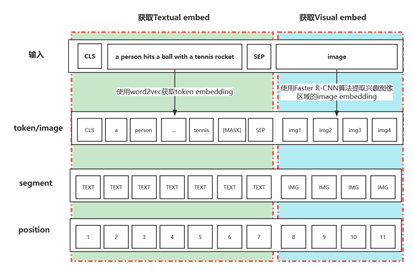
图3 获取文本-图像对数据的embedding
2.4 跨模态对比学习的UNIMO模型
UNIMO使用了海量的单模和多模数据解决了语料规模受限问题,同时为了更好的兼容单模和多模数据,将对比学习应用到跨模态场景中。关于对比学习的相关介绍小伙伴可以看下之前写过的一篇文章《广告行业中那些趣事系列34:风头正劲的对比学习和项目实践》。传统的基于负例的对比学习主要是通过batch内采样获取负例,这样只能学习到粗粒度的文本和图像相似特征,而UNIMO将对比学习泛化到了跨模态层面,通过文本改写和文本/图像检索来提升正负例的质量和数量,下面是UNIMO跨模态对比学习介绍:

图4 UNIMO跨模态对比学习介绍
UNIMO模型提出的跨模态对比学习(Cross-Modal Contrastive Learning,CMCL)核心思想是将含义相同的文本-图像对数据作为正例,含义不同的文本-图像对数据作为负例,通过构造相似实例和不相似实例获得一个表示学习模型,通过这个模型可以让相似的实例在投影的向量空间中尽可能的接近,不相似的实例尽可能的远离。UNIMO为了提升CMCL中的正负例的质量,主要使用了文本改写和文本/图像检索两种策略:
(1)文本改写
为了增加CMCL中正负例的质量,UNIMO将图片的描述从语句、短语和词三个粒度进行改写。从语句粒度来看,通过回译技术增加正例,将图片对应的描述翻译成多条语义一致语言表示形式略有不同的样本从而达到样本增强的目的。同时基于tfidf相似度检索算法得到字面词汇重复率高但是语义不同的样本来增加负例;从短语和词粒度来看,随机替换语句中的object、attribute、relation和对应的组合信息从而增加负例;
(2)文本/图像检索
为了进一步增加CMCL正负例的质量,UNIMO从海量的单模数据中检索相似文本或者图像,从而组成弱相关文本-图像对数据用于对比学习,通过这种方式可以增加大量的训练语料。
2.5 UNIMO中视觉学习和文本学习
UNIMO相比于传统多模态学习模型来说,不仅使用了多模数据,而且还使用了图像和文本等单模数据。对于单模数据来说,UNIMO通过检索技术获取相似图像和文本构成弱相关文本-图像对数据用于对比学习增加训练语料,同时对大量的单模数据进行视觉学习和文本学习,通过视觉学习和文本学习可以避免遗忘问题,迫使模型适应文本和图像单模数据源,提升多模态学习模型的泛化能力。
(1)视觉学习
UNIMO中的视觉学习和BERT的MLM任务一致,将多个兴趣区域的图像随机进行掩码操作,使用未被掩码的图像区域去还原被掩码的图像。
(2)文本学习
文本学习也采用和BERT的MLM任务一致,随机掩码一部分连续的token,利用上下文还原被掩码的token。不仅如此,为了更好的支持理解类和生成类任务,UNIMO文本学习的损失函数包括两部分内容,包括双向预测(Bidirectional prediction)和 序列生成(Seq2Seq Generation)两种损失函数。
UNIMO在模型训练的时候是图像、文本和图像-文本对三种数据源混合训练,也就是说一个batch内同时包含三种数据,论文中设置的混合数据比例为1:1:5。
2.6 UNIMO模型效果
UNIMO分别在单模文本理解、单模文本生成、多模理解和多模生成任务上验证模型效果,下面是在各大任务上使用的数据集:
单模文本生成任务:生成式对话问答数据集CoQA、问题生成数据集SQuAD-1.1、摘要数据集CNNDM和句子压缩数据集Gigaword
单模文本理解任务:情感分类数据集SST-2、自然语言推断数据集MNLI、语言可接受度分类数据集CoLA和语义相关性数据集STS-B
多模理解任务:经典的视觉问答数据集VQA-2.0、视觉蕴含SNLI-VE和图文检索数据集Flickr30K
多模生成任务:MS-COCO图像描述生成
在多个多模任务中,UNIMO达到了SOTA效果,下面是UNIMO在多模任务中的模型效果图:
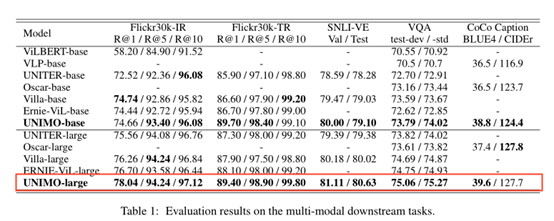
图5 UNIMO在多模任务中的模型效果
UNIMO不仅在多模任务中表现出色,而且在单模任务中也达到了不错的效果,下面是UNIMO在单模任务中的模型效果:
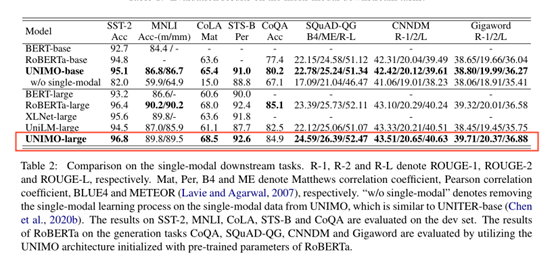
图6 UNIMO在单模任务中的模型效果
下面通过可视化展示了UNIMO模型在文本和图像检索任务中的模型效果,可以看出UNIMO相比于baseline来说对于细节的把握和理解更加出色:

图6 UNIMO模型在文本和图像检索任务中的模型效果
03
UNIMO开源项目工程
UNIMO项目目前已经开源,github地址如下:
https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
UNIMO项目需要以下依赖:
python 3.7.4
paddlepaddle-gpu==1.8.4.post107
pyrouge==0.1.3 regex==2020.7.14百度目前已经训练了四个版本的UNIMO预训练模型,小伙伴可以在训练好的模型上微调满足下游任务:

图7 百度公开的4种UNIMO预训练模型
04
总结及反思
本篇主要介绍了百度在多模态学习领域的成果UNIMO模型。首先是背景介绍,针对当前主流多模态学习模型存在训练语料少和模态缺失导致模型效果下降的问题,百度提出了UNIMO统一学习模型;然后重点介绍了UNIMO模型,主要包括UNIMO解决训练数据稀少和模态缺失问题、UNIMO模型输入、跨模态对比学习的UNIMO、UNIMO中视觉学习和文本学习以及UNIMO模型效果;最后介绍了UNIMO开源项目工程。对多模态学习感兴趣并且希望应用到项目实践的小伙伴可能有所帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们点赞和分享。
这篇关于广告行业中那些趣事系列55:文本和图像领域大一统的UNIMO模型详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





