本文主要是介绍《Key Points Estimation and Point Instance Segmentation Approach for Lane Detection》翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《车道线检测的关键点预测和点实例分割方法-PINet》
- 一、摘要
- 1、体系结构
- 2、方法概述
- 3、方法优点
- 二、研究现状
- 三、实现方法
- 1、车道线点实例网络
- 2、后处理方法
- 四、实验结果
- 1、评价标准
- 2、实验
一、摘要
1、体系结构
包含共享的特征提取层和多个分支,用于检测和嵌入到车道线集群中。
2、方法概述
该方法能在车道线上生成精确的点,针对这些点,将聚类问题投射为点云实例分割问题。
3、方法优点
(1)该方法利用深度神经网络,能检测任意数量的车道线,
(2)错误率更低。
(3)轻量模型,生成点的数量比原始图片像素点少得多。
(4)消除离群值
二、研究现状
大部分传统的的车道线检测方法首先提取低级特征,手工标注出颜色,边缘信息等。这些低级特征通过霍夫变换和卡尔曼滤波连结起来,利用这些联合特征就可以将车道线分割出来。这些方法简单,且不用做大的修改就能适应不同的环境,但是会极度依赖光照、遮挡等条件。
深度学习在应对复杂环境时表现很好。在诸多的深度学习方法中,深度神经网络(CNN)专一用于计算机视觉领域。近期有许多研究运用CNN来做特征提取。语义分割方法经常应用于车道检测问题,以推断车道的形状和位置. 这些方法可以区分整个图像上的像素的实例和标签。由于它们采用多类方法来区分每个车道,因此只能将它们应用于包含固定数量的车道的场景。Neven et al.将该问题转化为实例分割。他们提出了LaneNet模型,该模型包含1个用于特征提取的编码器,2个解码器。其中一个解码器用于灰度图的车道线提取,另一个嵌入分支用于实例分割。由于LaneNet模型应用了实例分割方法,因此可以检测任意数量的车道线。Chen et al提出了一种网络,在每个车道线上,给定y坐标值可以直接预测出对应的x坐标值,但是该方法只能预测垂直的车道线。
我们提出的模型能预测比输入图像尺寸更小的车道线的精确点,并能分辨出每个实例的每一个像素。沙漏网络通常用于区域关键点估计,例如姿态估计和物体检测.沙漏网络模型通过先下采样再上采样,可以提取不同尺寸的目标信息。如果将一些沙漏网络堆叠在一起,则损失函数可以应用于每个堆叠的网络,可以使训练更加稳定。在计算机视觉领域,实例分割可以生成每个实例的像素簇。
漏检不会突然改变控制值,可以通过其他车道线的检测来修改控制值。而错捡会迅速改变控制值。信度、偏置和特征。置信度和偏置能预测车道线上的点,特征值能分辨出每个预测点属于哪个实例。最后,通过应用后处理模块消除离群值,生成平滑车道线。

总结来说,本文提出的框架有以下几个优点:
(1) 该方法的输出图像尺寸比实例分割方法小,紧凑的尺寸可以节省模块的内存。
(2) 加入应用后处理模块,消除离群值。
(3) 可以用于各种场景,可以预测垂直或水平的任意方向的、任意数量的车道线。
(4) 评价结果显示,该方法的误检率比其他方法低。
三、实现方法
网络名称PINet(Point Instance Network),能产生所有车道线上的点,并分辨每个实例包含的点。损失函数来自SPGN(Similarity Group Proposal Network),它是对3D点云进行实例分割的框架。本文提出的方法仅对于预测点而不是所有像素都需要嵌入,因此3D点云实例分割方法很适合我们的任务。
1、车道线点实例网络

本实验中,将输入图片压缩为6432和3216两种情况。特征提取层使用了堆叠沙漏网络,它在关键点预测任务中效果很好。PINet包括2个沙漏模块。每个沙漏模块有3个输出分支,并且输出网格的尺寸与经过压缩后输入的尺寸相同。堆叠沙漏网络的详细解释见此篇blog


批量归一化和Relu层在每个卷积层之后应用,除非它们在输出分支的末尾应用。输出分支中的过滤器数量由输出值确定。 例如,置信度分支为1,偏移分支为2,特征分支为4。
置信度分支:预测每个网格的置信度值。置信度分支的输出有1个通道,并被转发到下一个沙漏模块。以下是置信度分支的损失函数:

Ne,Nn代表有点存在和没有点存在的网格数量,G表示网格的集合,gc表示一个网格的输出置信度,gc*表示真实值,r表示各自的参数。
偏置分支:可以得出每个点的准确位置。偏置分支的输出是一个0~1之间的数字,表示与一个网格的相对位置。根据输入和输出尺寸的比率,1个网格对应8个或16个像素。偏置分支有2个通道以预测x坐标和y坐标的偏移。下面是偏移分支的损失函数:

特征分支:此分支来源于3D点云实例分割法SGPN。该特征意味着有关实例的信息,并且训练了分支以使同一实例中的网格特征更加接近。以下是特征分支的损失函数:

Cij表示点i和点j是否属于同一个实例,Fi表示网络预测的点i的特征,常数K>0。如果Cij=1,表示i和j是同一个实例,如果Cij=2表示i和j位于不同的车道线。当训练的时候,损失函数会使属于同一个实例的点特征更加接近,使不同实例的点被区分出来。我们可以通过基于距离的简单聚类技术辨认出每个实例的点。特征尺寸设置为4,经检测该尺寸对检测结果没有太大影响。
总损失函数是以上3个损失函数线性求和,整个网络通过端到端方法进行训练。

训练阶段初始化所有系数为1,在最后几个epochs,将a和rn加0.5.该损失函数可以适应端到端的沙漏模块,以使训练过程稳定。
2、后处理方法
网络的直接输出会存在一些错误,比如一个实例只能包含一条平滑的车道线。但是,有些离群值或其他车道线可以从视觉上区分。

应用后处理的流程如下:
步骤1:找6个起始点。起始点就是3个位于图片最下方的点和3个最左边或者最右边的点。如果预测的车道线位于图片中间偏左的位置,那么最左边的点就被选作起始点。
步骤2:选出3个距离起始点最近的且位置比起始点高的点。
步骤3:考虑一条直线,该直线连接在步骤1和2中选择的两个点。
步骤4:计算直线和其他点之间的距离。
步骤5:计算边缘以内点的数量,本文中边缘r设为12.
步骤6:选择数量大于阈值的最大数量的点作为起始点,考虑该点与起始点属于同一个实例。本文设置阈值为剩余点的20%。
步骤7:重复步骤2~步骤6,直到在步骤2中找不到点。
步骤8:对所有起始点重复步骤1~7,考虑将宽度最大的簇作为最终车道线。
步骤9:对所有预测的车道线重复步骤1~8.
四、实验结果
在tuSimple训练数据集上使用Adam优化器进行训练,初始学习率0.0002.在开始的1000个epochs里使用初始化的设置,在最后的200个epochs里,设置学习率0.0001,a=1.5,rn=1.5.其他超参数比如应用后处理中的边缘尺寸由实验方法决定。超参数的优化要根据训练结果做适当修改。实验中没有用到其他的数据集和训练好的权重,两种输出尺寸6432和3216都做了评估。测试硬件为NVIDIA RTX 2080Ti。
1、评价标准
精确率:

Cclip表示在给定的图片中,正确预测的点数量,Sclip表示图片中的真实点数量。
错误的正样本率和错误的负样本率:

Fpred表示预测错误的车道线数量,Npred表示预测的车道线总数量,Mpred表示没有检测到的车道线数量,Ngt表示真实的车道线数量。
2、实验
tuSimple数据集包含3626张标记训练图片,2782张标记测试图片。我们使用简单的数据扩容方法,比如翻转,平移,旋转,增加高斯噪声,改变亮度,增加阴影等方法来训练更加健壮的模型。tuSimple数据集根据场景中显示的车道数量具有不同的场景分布。

测试集中包含5个车道线的场景图片是训练集的2倍多,为了平衡这两种分布,我们在数据扩充步骤中设置了包含五个泳道的数据的生成比例,该车道线比其他车道线大。
评价时需要知道给定的y坐标对应的精确的x坐标值,我们使用简单的线性插值法来寻找y对应的x坐标。由于预测的点之间的距离很近,因此不需要使用复杂的曲线拟合算法。
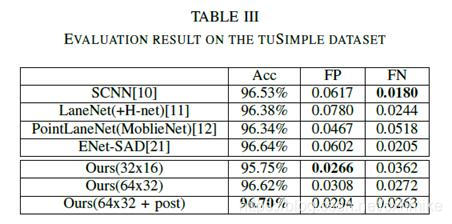
详细的评价结果见表3.三种情况下我们的方法都得到了最低的FP率。这说明PINet的误检率比其他方法低很多。
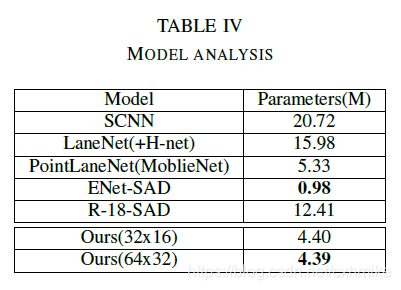
表四表示每种方法的参数数量,PINet是最轻量级的方法之一。PINet几乎所有的部分都是瓶颈层构建的,这种架构可以节省大量的内存。不经过应用后处理时,可以达到30FPS,使用应用后处理,帧率为10FPS。

在这项研究中,我们提出了一种新颖的车道线检测方法,它结合了点预测和点实例分割,可以达到实时性要求。该模型的FP率是最低的,保证了自动驾驶车辆的安全性。后处理显著地提高了检测效果,但是目前的执行版本耗费大量的计算资源,今后需要并行计算架构或者其他的优化方法来解决这一问题。
这篇关于《Key Points Estimation and Point Instance Segmentation Approach for Lane Detection》翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



