本文主要是介绍寒武纪芯片MLU370-M8完成GLM2-6B多轮对话Ptuning-v2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、环境准备
- 1.云平台环境准备
- 2.私有库安装
- 3.快速模型下载
- 4.代码修改
- 二、开始运行
- 1.启动脚本
- 2.运行状态
- 总结
前言
前几篇讲到了有关大模型在寒武纪卡上推理,是不是觉得越来越简单了,接下来上干活知识,基于寒武纪卡完成大模型微调,以及后面还会讲到基于寒武纪卡完成数字人训练+推理,敬请期待。
废话不多说,我们现在开始
一、环境准备
1.云平台环境准备
云平台环境选择:(这里得夸一下现在云平台PLUS完美升级,可以直接平台vscode操作,方便的很)
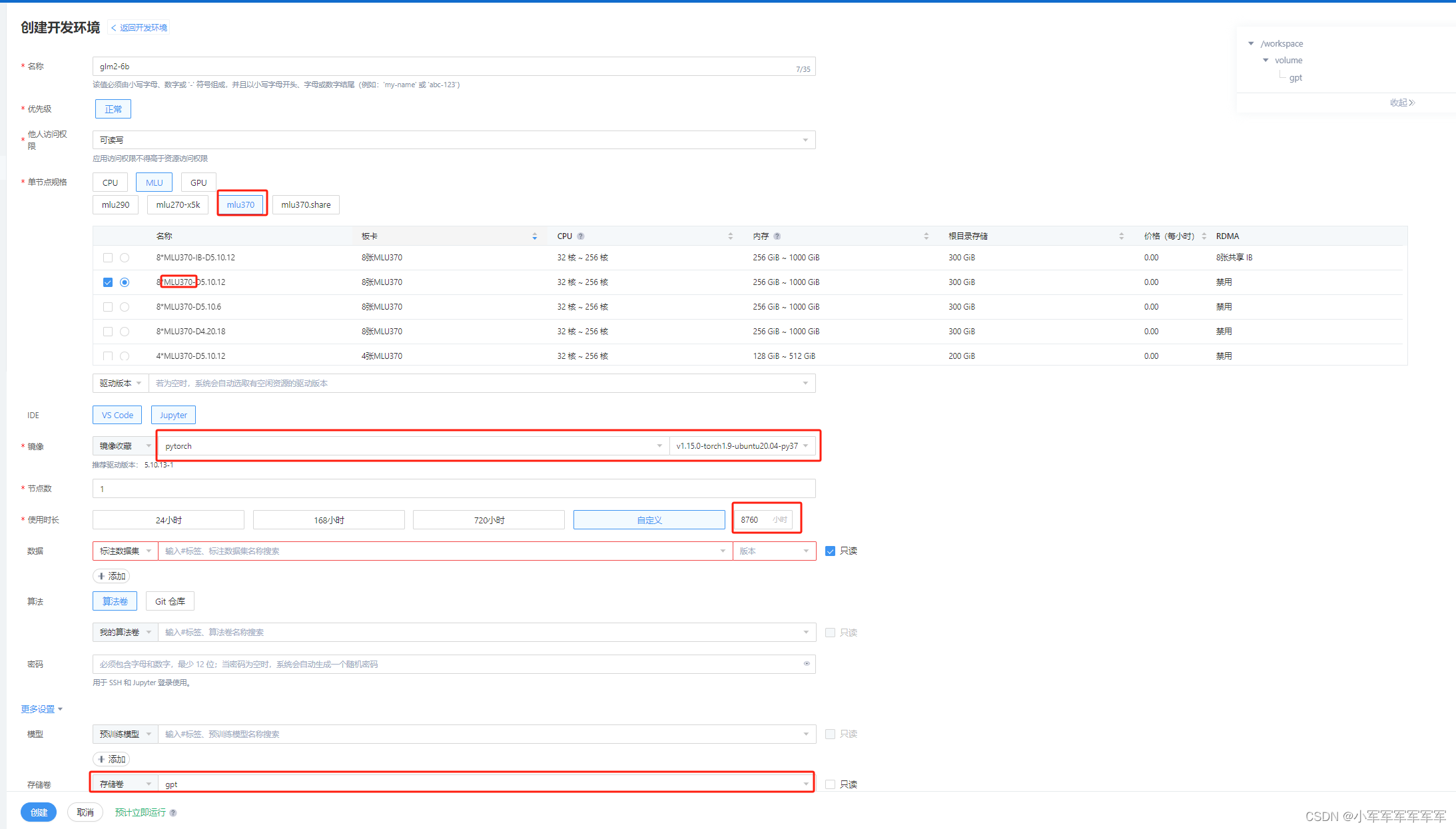
选择mlu370-M8卡 + pytorch 1.9 py3.7环境 存储卷记得挂哦,你问我平台在哪里?私聊我或者别的博客微信咨询
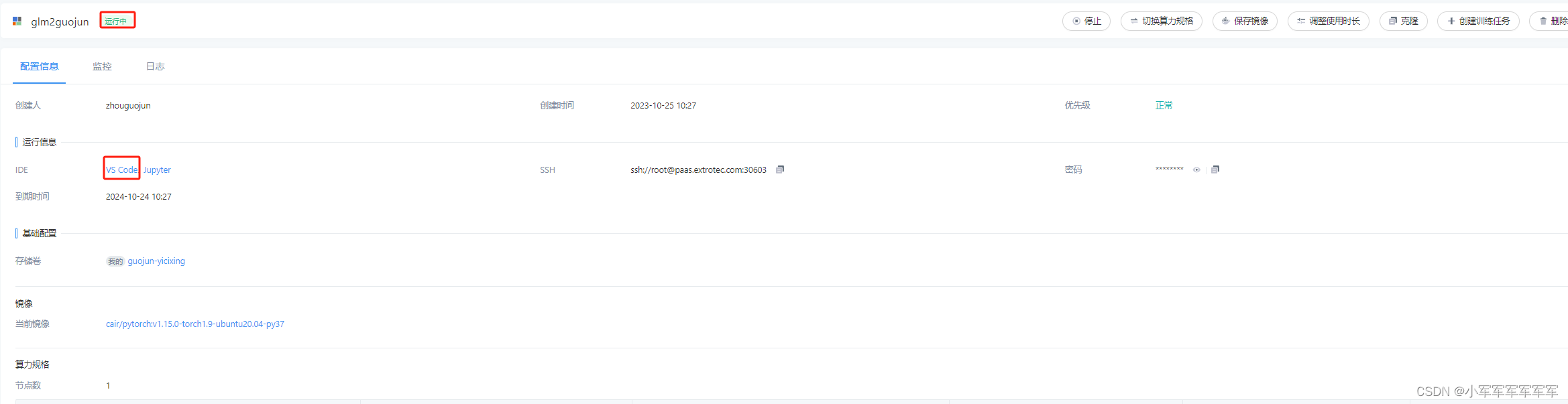
显示运行中,然后直接vscode运行就可以了
2.私有库安装
有时候我在想如果直接把编译好的库给大家是不是更方便,想想算了,还是教操作吧,感受国产卡得易操作上手
源码下载
git clone https://github.com/THUDM/ChatGLM2-6B.git
transformers==4.30.2安装
git clone https://github.com/huggingface/transformers.git #4.30.2
python /torch/src/catch/tools/torch_gpu2mlu.py -i transformers-4.30.2/ #算子转换
pip install -e ./transformers-4.30.2_mlu/ -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
accelerate安装
git clone https://github.com/huggingface/accelerate.git #0.20.2
python /torch/src/catch/tools/torch_gpu2mlu.py -i accelerate-0.20.2/ #算子转换的pip install -e ./accelerate-0.20.2_mlu/ -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
deepspeed 安装要联系me
常规库安装
pip install modelscope cpm_kernels rouge_chinese nltk jieba datasets sentencepiece -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
3.快速模型下载
用魔塔社区快速下载
# 备注:最新模型版本要求modelscope >= 1.9.0
# pip install modelscope -U from modelscope.utils.constant import Tasks
from modelscope import Model
from modelscope.pipelines import pipeline
model = Model.from_pretrained('ZhipuAI/chatglm2-6b', device_map='auto', revision='v1.0.12')模型存放位置位于/root/.cache/modelscope/hub/ZhipuAI/chatglm2-6b
模型下载完成即可,我们不用modelscope训练,后续报错可以不用管
4.代码修改
/root/.cache/modelscope/hub/ZhipuAI/chatglm2-6b/modeling_chatglm.py
注释 from torch.nn.utils import skip_init
改成:
def skip_init(module_cls, *args, **kwargs):if not issubclass(module_cls, torch.nn.Module):raise RuntimeError('Expected a Module; got {}'.format(module_cls))final_device = kwargs.pop('device', 'cpu')kwargs['device'] = 'meta'return module_cls(*args, **kwargs).to_empty(device=final_device)
.all()移到cpu运行
if(attention_mask is not None and not attention_mask.cpu().all()) or (past_key_values and seq_length != 1):full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
修改数据类型
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,# dtype=config.torch_dtypedtype = torch.float32)
注释这一块
# if sys.platform != 'darwin':
# torch._C._jit_set_profiling_mode(False)
# torch._C._jit_set_profiling_executor(False)
# torch._C._jit_override_can_fuse_on_cpu(True)
# torch._C._jit_override_can_fuse_on_gpu(True)
5.数据集制作
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
数据集要做多点喔,不然会运行报错的
二、开始运行
1.启动脚本
PRE_SEQ_LEN=128
LR=1e-2
export CNCL_MEM_POOL_MULTI_CLIQUE_ENABLE=1
export CNCL_MLU_DIRECT_LEVEL=1
export CNCL_SLICE_SIZE=2097152
export CNCL_MEM_POOL_ENABLE=0
export MLU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python -m torch.distributed.run --nnodes 1 --nproc_per_node 8 main.py \--do_train \--train_file /workspace/volume/guojun-yicixing/ChatGLM2-6B-main/ptuning/train.json \--validation_file /workspace/volume/guojun-yicixing/ChatGLM2-6B-main/ptuning/val.json \--preprocessing_num_workers 10 \--prompt_column prompt \--response_column response \--history_column history \--overwrite_cache \--model_name_or_path /root/.cache/modelscope/hub/ZhipuAI/chatglm2-6b \--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \--overwrite_output_dir \--max_source_length 256 \--max_target_length 256 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 16 \--predict_with_generate \--max_steps 3000 \--logging_steps 10 \--save_steps 1000 \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN \--fp162.运行状态
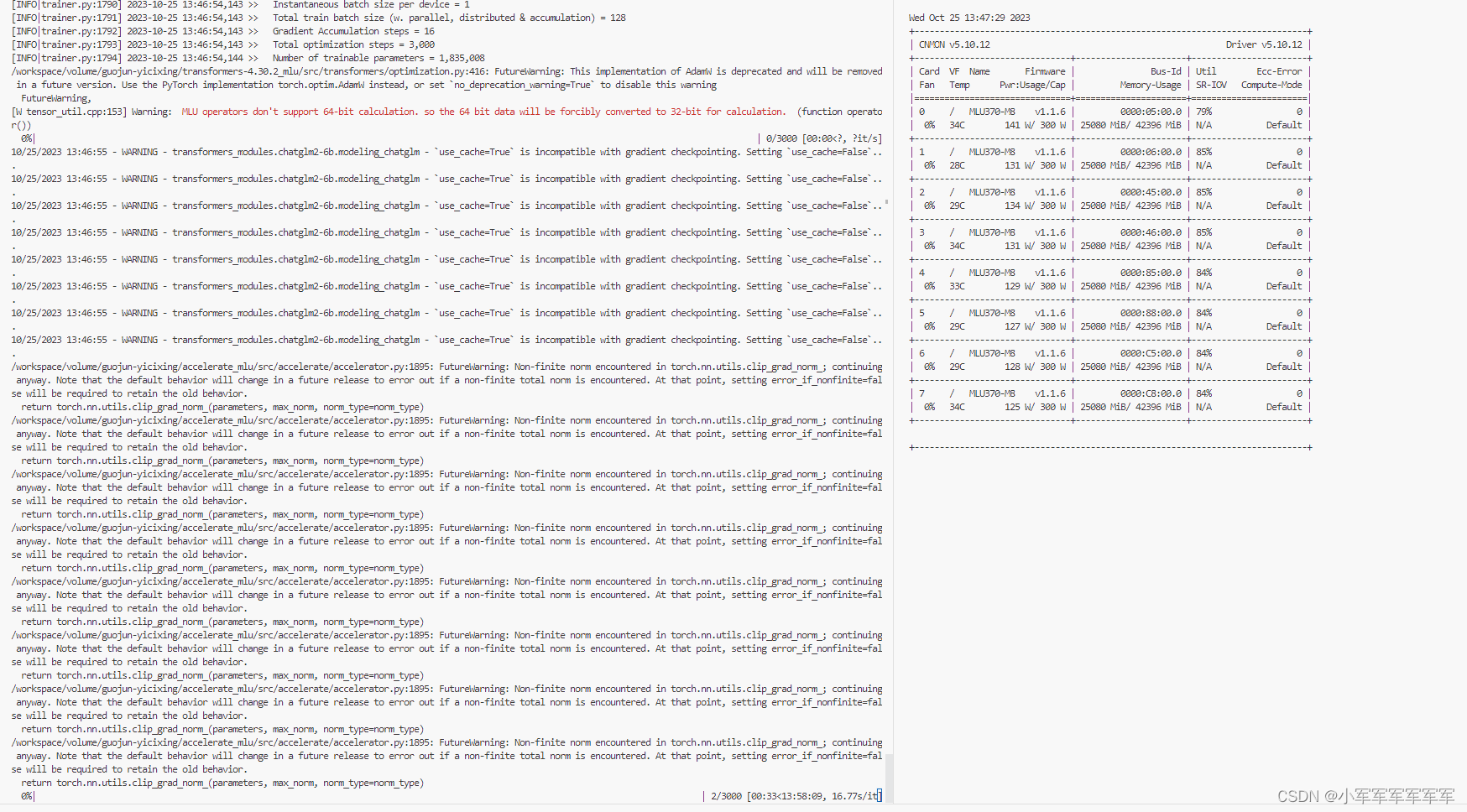
右侧显存及使用率正常,训练出来的模型和英伟达一致正常推理代码,将.cuda()改为.mlu()就可以了
总结
目前Mlu能跑几乎很多算法,下一期来一期数字人推理+数字人训练吧
这篇关于寒武纪芯片MLU370-M8完成GLM2-6B多轮对话Ptuning-v2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









