本文主要是介绍基于YOLOV8+移动窗口切片(完整版)+OnnxRuntime+KMeans+Zbar+传统图像处理算法的大图片小目标光伏产线条码检测研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1 项目背景
- 2 训练YOLOV8的一维码检测模型
- 3 读取测试图片
- 3.1 调整首窗口位置
- 4 创建滑动窗口,窗口大小为(640,640),移动距离为160,对不足(640,640)的窗口进行填充
- 5 创建Onnxruntime推理引擎并测试
- 5.1推理测试
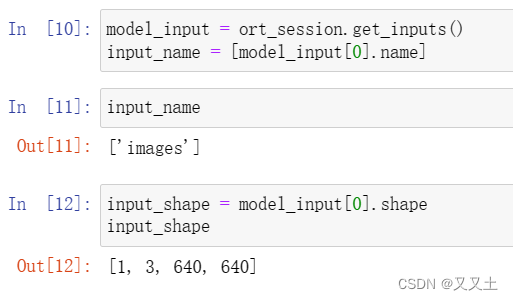
- 5.2获得ONNX模型输入层(输出层)和数据维度
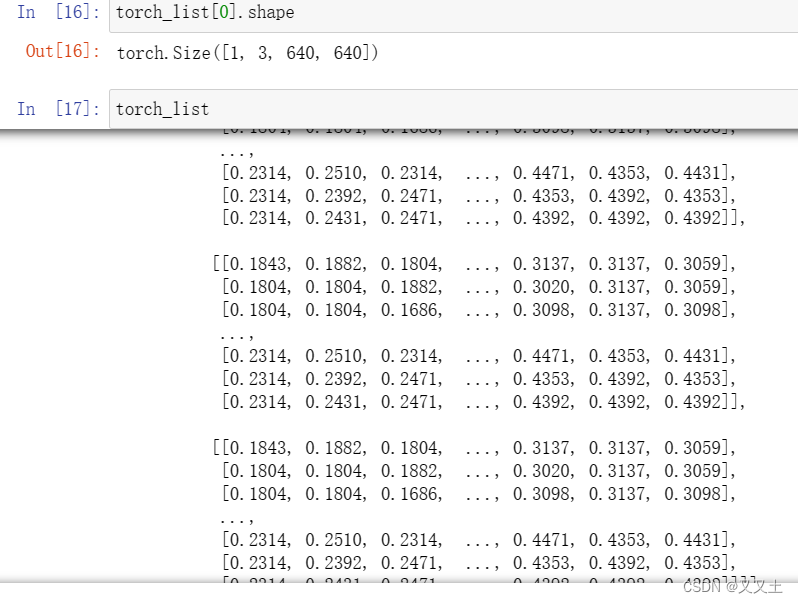
- 5.3 预处理-构造输入张量 torch_list
- 6 执行推理预测
- 7 后处理-置信度过滤、NMS过滤
- 8 重构preds_dict坐标
- 8.1 把目标的坐标还原回原图的坐标
- 9 去重——用KMeans将检测目标分成15类
- 10 opencv 可视化
- 10.1 用Zbar识别二维码
- 10.2 ZBar解码
- 10.3 绘制检测框
- 总结
- 相关文章
前言
关于条码检测方案,一共有三部曲:
[1] 基于Opencv+Kmeans+Zbar的条码检测与基于锐化+双边高斯滤波+Zbar的条码检测在工业光伏产线上的检测效果研究
[2]大图像中的小目标检测——基于YOLOV8+OnnxRuntime部署+滑动窗口+Zbar的条码检测研究
本文是最后一篇,本专题三篇是步步深入的,因此如果觉得本文比较难,可以先看前两篇。这个专题的研究大概持续一个月左右,从传统学习到深度学习再到将传统机器学习算法和深度学习相结合,如今已经十分贴近工业应用的场合了,甚至超过了一般工业所见的条码场合的。
本文可以用在:
前提是完全理解本文在的算法和思维角度。
- 应届生简历(难度很大,但一定是加分项,本人做过公司硕士的面试官,但是没有遇见特别亮眼的项目)
- 进阶深度学习的素材(适合对yolov8+传统算法都要有基础的伙伴)
- 毕业课题(专硕是可以使用qt封装本算法,之后做几个实验基本是没问题的)
本文以条码检测为引,但本文作用不仅仅局限于此。本文记录了本人思考问题的过程,可以尝试问一下自己,在面对那些问题的时候,你会用什么方式处理。
声明:本项目是原创且开源的,本项目旨在帮助对cv深度学习感兴趣的伙伴,如要转载请注明出处。也希望大家帮忙支持点一下赞,谢谢。
1 项目背景
条码检测是常见的工业应用场合,在国内可以用visionpro、halcon等一些软件自带的条码检测软件来实现。最近出现了国外项目,一些国内可以用的软件在国外都需要版权了,懂的都懂。因此opencv开发就显得十分重要了。本文采用目标检测用的是yolov8,解码器用的是Zbar,这两个包工程化都很好,可以大大缩短项目的开发周期。通过查阅资料以及自己试验,Zbar无法实现对复杂的工业环境的条码检测,问题主要出现在图像分辨率、环境光源,因此为了实现更准确更有效的的工业条码检测,本文基于YOLOV8+移动窗口切片(完整版)+OnnxRuntime+KMeans+Zbar+传统图像处理算法对大图片小目标光伏产线条码检测进行了研究。
2 训练YOLOV8的一维码检测模型
- 关于如何训练模型不是本文的重点,可以根据这篇文章简单训练一个模型(YOLOV8目标检测——最全完整的模型训练记录)
- 如果需要本人训练好的模型可以在这里下载( 文章顶部文件包:best.pt、best.onnx、 数据集、实验图片)
3 读取测试图片
import cv2
import numpy as np
from PIL import Imageimport onnxruntimeimport torch
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')import matplotlib.pyplot as plt
%matplotlib inline
# 显示图片
image = cv2.imread("D:/yolov5-6/data/images/Pic_2023_04_18_104022_3.bmp")
plt.imshow(image[:,:,::-1])
image_1 = image.copy()

3.1 调整首窗口位置
img_test = image[340:980,0:640]
plt.imshow(img_test[:,:,::-1])

4 创建滑动窗口,窗口大小为(640,640),移动距离为160,对不足(640,640)的窗口进行填充
-
win_coordinate记录了窗口切片在原图中的位置,所以为什么要这么做呢?
-
思考一个问题:我们用yolov8检测出了条码,那么在画检测框是在原图上画好,还是在窗口切片上画好呢?
-
先带着这个疑问看下去。
win = 0
image_list = [] # 用来存储滑动窗口
win_coordinate = []#记录窗口左上角坐标 [x,y],图片横向为x轴与笛卡尔坐标系一样
while(win<4000):img_test = image[340:980,win:win+640]win_coordinate.append([win,340])if img_test.shape[1]<640:top = 0bottom = 0left = 0right = 640-img_test.shape[1]img_test = cv2.copyMakeBorder(img_test,top,bottom,left,right,cv2.BORDER_CONSTANT,value=[255,255,255]) image_list.append(img_test)win = win + 160

- 看一下窗口切片
- 15个条码,这里每个窗口里的条码加起来50个左右,也就是肯定有检测重复的条码
- 思考一个问题:如何去除重复的条码
for i in range(len(image_list)):plt.subplot(5,8,i+1)plt.imshow(image_list[i][:,:,::-1])
plt.show()

5 创建Onnxruntime推理引擎并测试
ort_session = onnxruntime.InferenceSession('E:/ultralytics/runs/detect/train4/weights/best.onnx', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])5.1推理测试
x = torch.randn(1, 3, 640, 640).numpy()
ort_inputs = {'images': x}
ort_output = ort_session.run(['output0'], ort_inputs)[0]
ort_output
输出了结果,说明onnxruntime引擎没有问题。

5.2获得ONNX模型输入层(输出层)和数据维度

5.3 预处理-构造输入张量 torch_list
这里是标准的yolov8输入图像的预处理模式
# 有 GPU 就用 GPU,没有就用 CPU
torch_list = []
for i in range(len(image_list)):
# 预处理-归一化image = image_list[i][:,:,::-1]image = image / 255# 预处理-构造输入 Tensorimage = np.expand_dims(image, axis=0) # 加 batch 维度image = image.transpose((0, 3, 1, 2)) # N, C, H, Wimage = np.ascontiguousarray(image) # 将内存不连续存储的数组,转换为内存连续存储的数组,使得内存访问速度更快image = torch.from_numpy(image).to(device).float() # 转 Pytorch Tensor# input_tensor = input_tensor.half() # 是否开启半精度,即 uint8 转 fp16,默认转 fp32 torch_list.append(image)
可以查看一下相关数据
6 执行推理预测
当你在对切片处理的时候,还需要用字典去标记切片的,即:{切片:目标检测结果}。这个字典是贯穿始终的,能够保证最后把检测之后的切片,贴到原图的时候,知道那个预测结果是哪个窗口预测得来的。
preds_dict = {}for i in range(len(torch_list)):# ONNX Runtime 推理预测ort_output = ort_session.run(output_name, {input_name[0]: torch_list[i].cpu().numpy()})[0]# 转 Tensorpreds = torch.Tensor(ort_output)preds_dict[str(i)] = preds

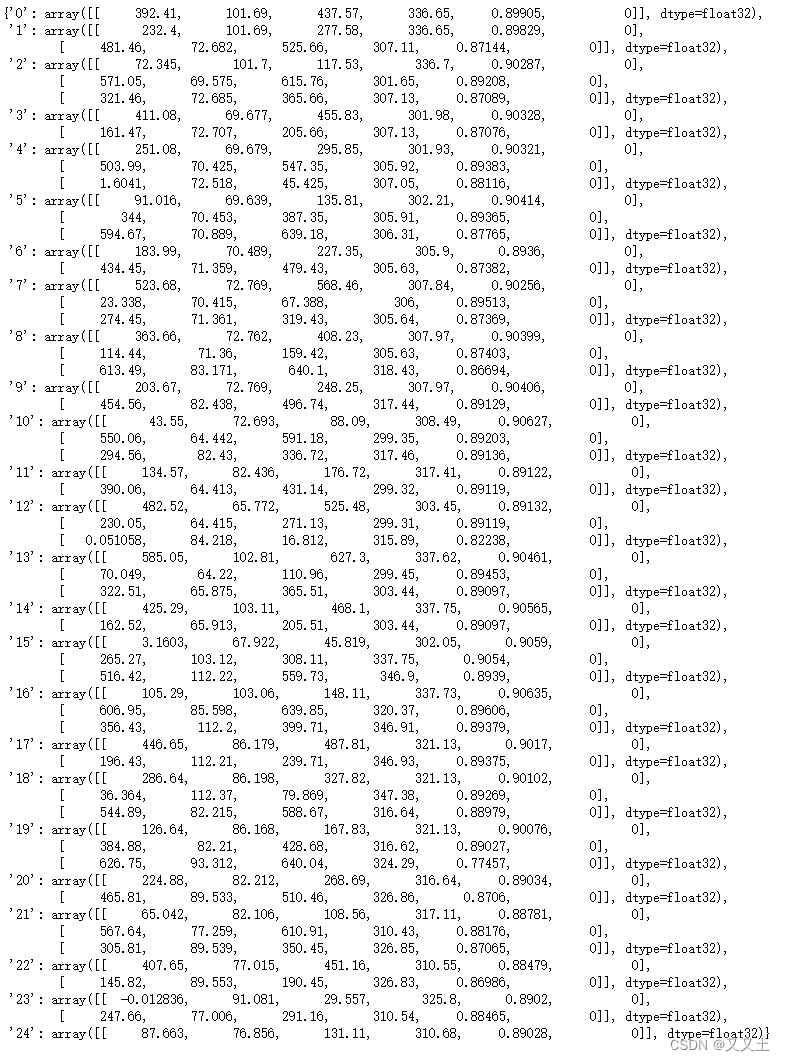
7 后处理-置信度过滤、NMS过滤
from ultralytics.utils import ops
for i in range(len(preds_dict)):pred = ops.non_max_suppression(preds_dict[str(i)], conf_thres=0.7, iou_thres=0.7, nc=1)preds_dict[str(i)] = pred[0]
经过非极大值抑制,条码基本都被标记出来了。
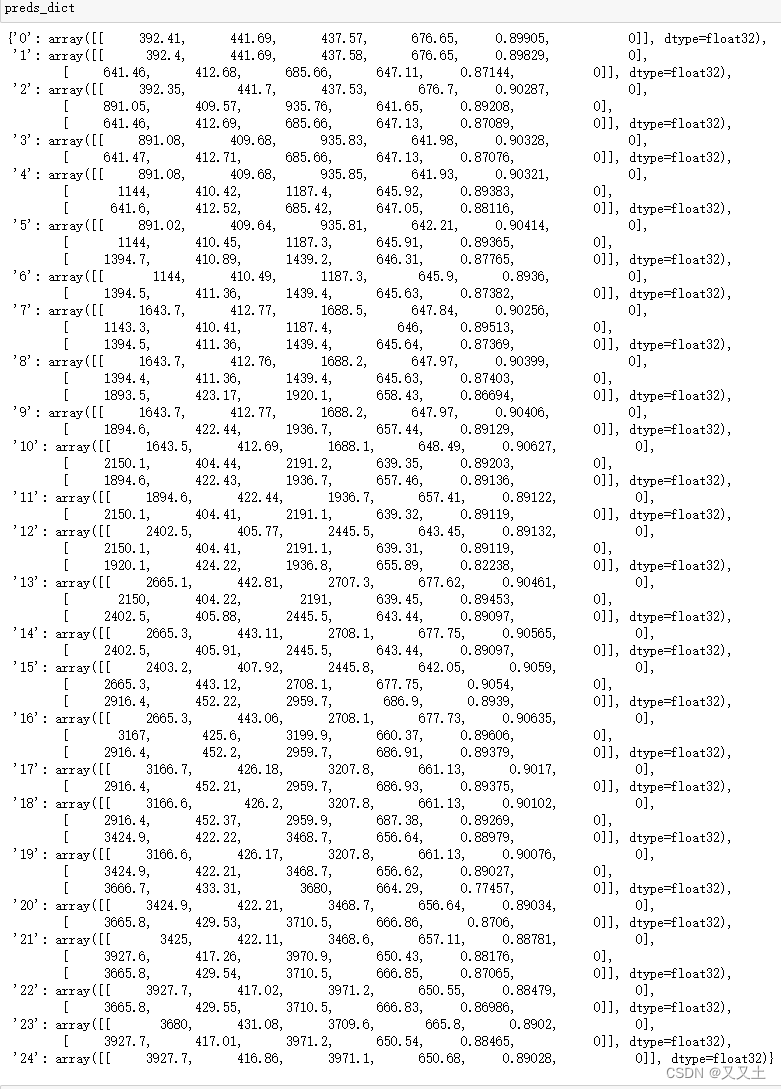
8 重构preds_dict坐标
8.1 把目标的坐标还原回原图的坐标
- 目标检测预测结果:左上角X、左上角Y、右下角X、右下角Y、置信度、类别ID
- 这里可以回答:为什么要用win_coordinate记录窗口坐标
rect_array = [] # 提取出所有框
for i in range(len(preds_dict)):for j in range(len(preds_dict[str(i)])):preds_dict[str(i)][j][0] += win_coordinate[i][0]preds_dict[str(i)][j][2] += win_coordinate[i][0]preds_dict[str(i)][j][1] += win_coordinate[i][1]preds_dict[str(i)][j][3] += win_coordinate[i][1]rect_array.append(preds_dict[str(i)][j])
- 重构之后的效果
9 去重——用KMeans将检测目标分成15类
- 回答使用什么方法去除重复的检测框
from sklearn.cluster import KMeans
k_means = KMeans(init="k-means++", n_clusters=15, n_init=10)
k_means.fit(rect_array)
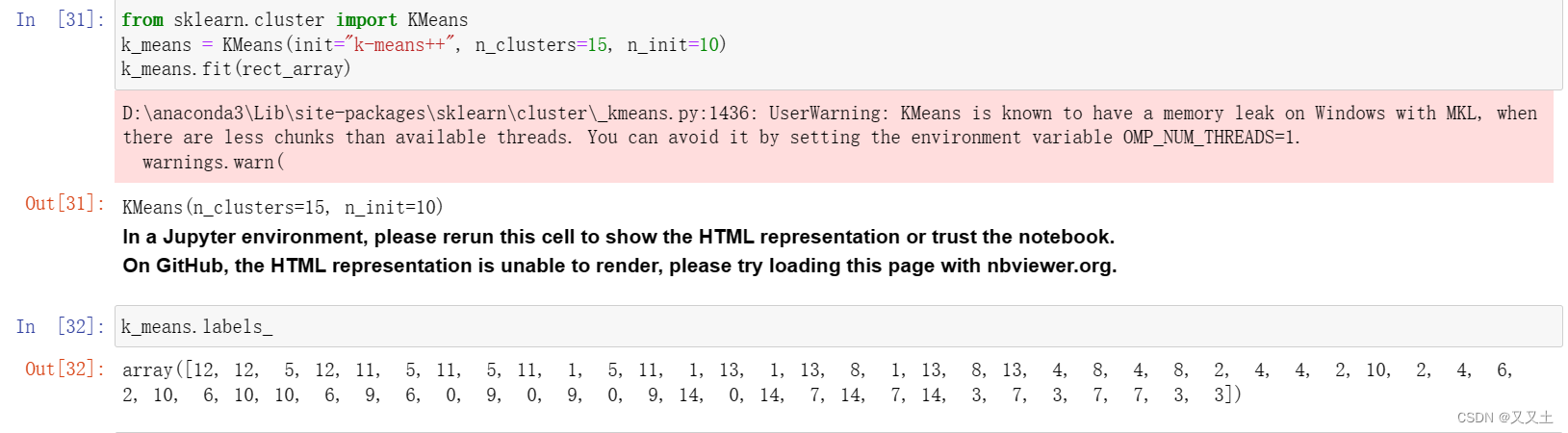
- 重新处理预测结果,数据真漂亮
list_right = []
list_right_1 = []
label = k_means.labels_
for i in range(len(label)):if label[i] not in list_right:list_right.append(label[i])list_right_1.append(i)
new_preds = []
for i in list_right_1:new_preds.append(list(rect_array[i]))
new_preds
new_preds = np.array(new_preds, dtype = "uint32")
new_preds

10 opencv 可视化
# 框(rectangle)可视化配置
bbox_color = (150, 0, 0) # 框的 BGR 颜色
bbox_thickness = 6 # 框的线宽# 框类别文字
bbox_labelstr = {'font_size':1, # 字体大小'font_thickness':1, # 字体粗细'offset_x':0, # X 方向,文字偏移距离,向右为正'offset_y':-10, # Y 方向,文字偏移距离,向下为正
}
10.1 用Zbar识别二维码
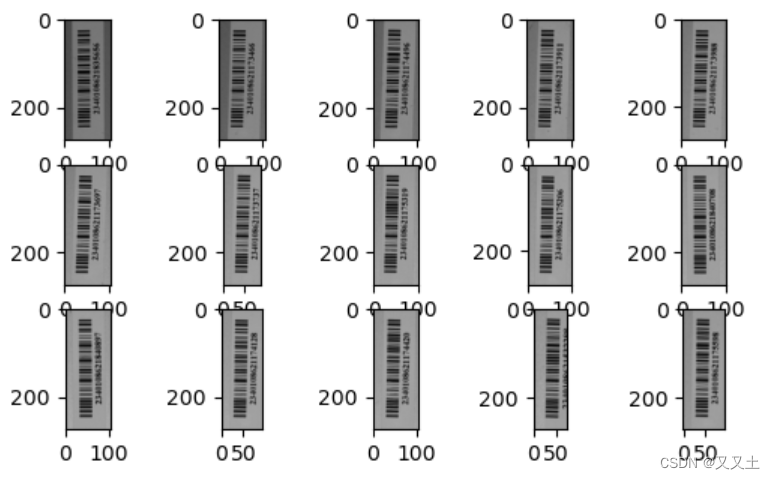
- 条码剪切+锐化+双边滤波
def cv_filter2d(img):kernel = np.array([[0, -1, 0],[-1, 5, -1],[0, -1, 0]])img = cv2.filter2D(img, -1, kernel)return imgcodes = []
for bbox_xyxy in bboxes_xyxy: code = image_1[bbox_xyxy[1]-20:bbox_xyxy[3]+20,bbox_xyxy[0]-20:bbox_xyxy[2]+40] # 主要是要考虑你画出框是不是比较合适。yolov8的框也是可以微调的code = cv_filter2d(code)code = cv2.bilateralFilter(src=code, d=5, sigmaColor=255, sigmaSpace=15)codes.append(code)
codes
- 双边滤波参数介绍一波

# 展示一下提取到的条码图片
for i in range(len(codes)):plt.subplot(4,5,i+1)plt.imshow(codes[i],cmap="gray")
plt.show()
10.2 ZBar解码
from pyzbar import pyzbar
res_1=[]
for i in range(len(codes)):res = pyzbar.decode(codes[i])res_1.append(res)
res_1

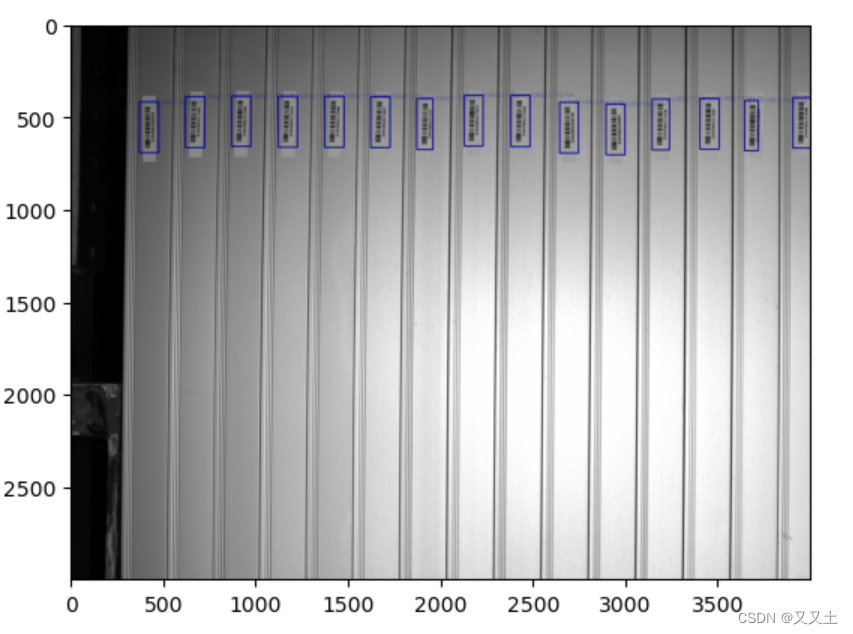
10.3 绘制检测框
- 回答一下上述问题:我们用yolov8检测出了条码,那么在画检测框是在原图上画好,还是在窗口切片上画好呢?
- 个人觉绘制在原图上会比较好。
- 检测框上标注的lable是解码数字,每个条码都能被被清楚定位和解码。
for i in range(len(res_1)):# 获取框的预测类别(对于关键点检测,只有一个类别)bbox_label = str(res_1[i][0].data,encoding="utf-8")# 画框image_1 = cv2.rectangle(image_1, (bboxes_xyxy[i][0]-20, bboxes_xyxy[i][1]-20), (bboxes_xyxy[i][2]+40, bboxes_xyxy[i][3]+20), bbox_color, bbox_thickness)# 写框类别文字:图片,文字字符串,文字左上角坐标,字体,字体大小,颜色,字体粗细image_1 = cv2.putText(image_1, bbox_label, (bboxes_xyxy[i][0]+bbox_labelstr['offset_x'], bboxes_xyxy[i][1]+bbox_labelstr['offset_y']), cv2.FONT_HERSHEY_SIMPLEX, bbox_labelstr['font_size'], bbox_color, bbox_labelstr['font_thickness'])plt.imshow(image_1[:,:,::-1])
总结
市面上有很多条码、二维码检测的算法,最让人印象深刻的就是腾讯微信扫码——基于SSD和超分算法的二维码检测方式。本文深受启发,将SSD的提取网络换成YOLOV8,将二维码的提取换成一维码。总的来说,试一次不错的体验。
本人是一名计算机视觉应用工程师,喜欢将算法应用于实际当中,这是自己的乐趣,如有什么需要讨论,欢迎评论区留言。
如您百忙之中还看到了这里,那是缘分。想来您和我一样对深度学习的应用深有兴趣,还请您帮忙点个赞,以便于更多的你我这样的人发现本文章,谢谢。
相关文章
[1] 基于Opencv+Kmeans+Zbar的条码检测与基于锐化+双边高斯滤波+Zbar的条码检测在工业光伏产线上的检测效果研究
[2]大图像中的小目标检测——基于YOLOV8+OnnxRuntime部署+滑动窗口+Zbar的条码检测研究
这篇关于基于YOLOV8+移动窗口切片(完整版)+OnnxRuntime+KMeans+Zbar+传统图像处理算法的大图片小目标光伏产线条码检测研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









