kmeans专题

Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apache.spark.ml.clustering包下,其过程大致如下: 1.根据给定的k值,选取k个样本点作为初始划分中心;2.计算所有样本点到每

R语言kmeans实例
说明:根据table(iris$Species, kmeans$cluster);可以看出setosa花成功聚为1类(图中绿o),但是versicolor花和virginica有16个分错交叉,但主体部分还是分的较明显的 > df<-iris[,c(1:4)]> set.seed(252964) # 设置随机值,为了得到一致结果 > (kmeans <- kmeans(na.omit(df),

【机器学习】(5.2)聚类--Kmeans
无监督模型。 聚类算法需要度量样本间的距离,距离度量的方式可以参考【机器学习】(5)聚类--距离度量_mjiansun的博客-CSDN博客 一般会使用欧氏距离。 1. K-means 1.1 基本思想 1.2 算法步骤 注意点与思考: 1. 初始值该怎么选择? 共有如下几种选择方式: (1)根据人的先验知识得到K个初始值,比如男女身高,假定男性身高175cm,女性165cm

程序猿成长之路之数据挖掘篇——Kmeans聚类算法
Kmeans 是一种可以将一个数据集按照距离(相似度)划分成不同类别的算法,它无需借助外部标记,因此也是一种无监督学习算法。 什么是聚类 用官方的话说聚类就是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。用自己的话说聚类是根据不同样本数据间的相似度进行种类划分的算法。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。 什么是K-m

Kmeans算法原理及Python实现
K-means算法是一种广泛使用的聚类算法,其原理相对简单且易于实现,属于无监督学习的一种。以下是对K-means算法原理的详细解析: 一、基本思想 K-means算法的基本思想是将数据集划分为K个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的数据点则尽可能不相似。算法通过迭代的方式,不断调整簇的中心点,直到满足某个终止条件为止。 二、算法步骤 指定聚类数目K:首先,用户需要指

机器学习 | 基于wine数据集的KMeans聚类和PCA降维案例
KMeans聚类:K均值聚类是一种无监督的学习算法,它试图根据数据的相似性对数据进行聚类。无监督学习意味着不需要预测结果,算法只是试图在数据中找到模式。在k均值聚类中,我们指定希望将数据分组到的聚类数。该算法将每个观察随机分配到一个集合,并找到每个集合的质心。然后,该算法通过两个步骤进行迭代:将数据点重新分配到质心最近的聚类。计算每个簇的新质心。重复这两个步骤,直到集群内的变化不能进一步减少。聚类

调用WEKA包进行kmeans聚类(java)
所用数据文件:data1.txt [plain] view plain copy print ? @RELATION data1 @ATTRIBUTE one REAL @ATTRIBUTE two REAL @DATA 0.184000 0.482000 0.152000 0.540000 0.152000 0.5

004、KMeans和DBSCAN的比较
KMeans 聚类 工作原理 选择K个初始中心点(可以随机选择或使用其他方法)。迭代过程: 分配每个数据点到最近的中心点:计算每个数据点到所有中心点的距离,将数据点分配到最近的中心点所属的簇。更新中心点:计算每个簇内所有数据点的均值,将该均值作为新的中心点。 停止条件:当中心点不再变化或达到预设的最大迭代次数时停止迭代。 优缺点 优点: 简单易理解,容易实现。计算速度快,适合大规模数据集。

【数学与算法】KMeans聚类代码
KMeans聚类是根据各点距离聚类中心的距离来把所有点分类到不同类别的无监督算法。 对于聚类,就是两点: 1.分类所有样本点:遍历每个数据样本点,分别计算该样本点与K个聚类中心的距离,把该样本点的类别重新分类为距离最小的那一类。2.更新聚类中心:所有样本点都按第一步重新分类后,把各类别的点重新计算聚类中心(求平均值的方法),更新K个类别的聚类中心值。3.重复前面两步,直到聚类中心点更新幅度小于
Matlab|基于手肘法的kmeans聚类数的精确识别【K-means聚类】
主要内容 在电力系统调度研究过程中,由于全年涉及的风、光和负荷曲线较多,为了分析出典型场景,很多时候就用到聚类算法,而K-means聚类就是常用到聚类算法,但是对于K-means聚类算法,需要自行指定分类数,如果没有方法支撑、纯自行确定分类数的话,显得随意性较大,很难令人信服,本次介绍一个方法——手肘法。 方法介绍 手肘法,很形象的命名方式,通过该方法得到的误差曲线类似手肘曲线,

【聚类】基于位置(kmeans)层次(agglomerative\birch)基于密度(DBSCAN)基于模型(GMM)
原博文: 一、聚类算法简介 聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别使得内内相似性大,内间相似性小。有时候作为监督学习中稀疏特征的预处理(类似于降维,变成K类后,假设有6类,则每一行都可以表示为类似于000100、010000)。有时候可以作为异常值检测(反欺诈中有用)。 应用场景:新闻聚类、用户购买模式(交
KMeans聚类分析星
1. datasample initial_centroids = datasample(data, k, 'Replace', false); 是MATLAB中的命令,用于从数据集data中随机抽取k个样本作为初始聚类汇总新,并且抽取时不放回。 datasample:是MATLAB中的函数,用于从数组中随机抽取样本data:是你想要进行聚类分析的数据集,通常是包含了所有待分类样本特征

基于Kmeans+Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示)
基于Kmeans+Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示) 聚类(Clustering)就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。 一、Kmeans+Canopy聚类算法实现原理

Kmeans聚类算法实现(输出聚类过程,分布图展示)
Kmeans聚类算法实现(输出聚类过程,分布图展示) Kmeans聚类算法是聚类算法中最基础最常用的聚类算法,算法很简单,主要是将距离最近的点聚到一起,不断遍历点与簇中心的距离,并不断修正簇中心的位置与簇中的点集合,通过最近距离和遍历次数来控制输出最终的结果。初始的簇中心、遍历次数、最小距离会影响最终的结果。具体的聚类算法过程不详细讲解,网上资料很多,本文主要是java语言实现,1000
基于用户评分Kmeans聚类的协同过滤推荐算法实现(附源代码)
基于用户评分Kmeans聚类的协同过滤推荐算法实现 一:基于用户评分Kmeans聚类的协同过滤推荐算法实现步骤 1、构建用户-电影评分矩阵: public Object readFile(String fileName){ List<String> user = new ArrayList<String>(); double[][] weight = new doub

利用KMeans进行遥感NDWI进行聚类分割
(1)解释 KMeans算法是一种非监督式的聚类算法,于1967年由J. MacQueen提出,聚类的依靠是欧式距离,其核心思想就是将样本划分为几个类别,类里面的数据与类中心的距离最小。类的标签采用类里面样本的均值。 这里利用KMeans进行遥感NDWI归一化水体指数进行简单的聚类分析,主要目的就是聚类出流域和非流域,簇类数为2。手动分割阈值为-0.06,效果和KMeans差不多,若是
【聚类】kmeans文本聚类实施过程
1、训练词向量 参考资料url:http://www.52nlp.cn/中英文维基百科语料上的word2vec实验①准备数据,这里假设使用wiki百科的1G数据,其中需要做一个繁体转简体,转格式为utf8,分词过程,参见上面的博客,这里我已经转好了,下载地址见百度网盘:https://pan.baidu.com/s/1htn3gig passwd:d6ss。②安装好python以及对应的模块
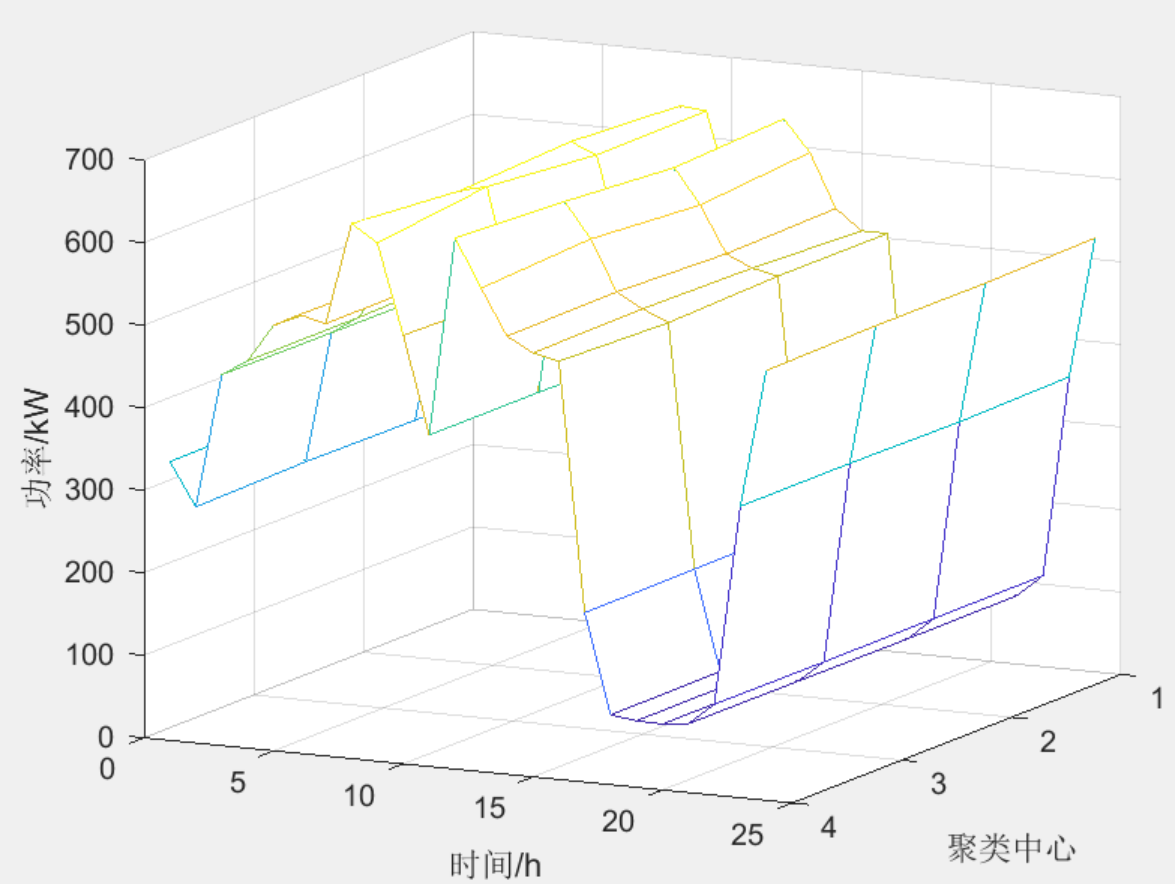
基于DTW距离测度的Kmeans时间序列聚类算法
原理介绍 基于DTW距离测度的Kmeans时间序列聚类算法代码获取戳这里代码获取戳这里代码获取戳这里代码获取戳这里代码获取戳这里 DTW距离: 当两个时间序列不等长时,传统的欧氏距离难以度量它们的相似性。DTW通过调节时间点之间的对应关系,能够寻找两个任意长时间序列中数据之间的最佳匹配路径。DTW算法的基本思想是通过将时间序列进行弯曲、拉伸等变换,找到它们之间的最佳匹配路径,从而
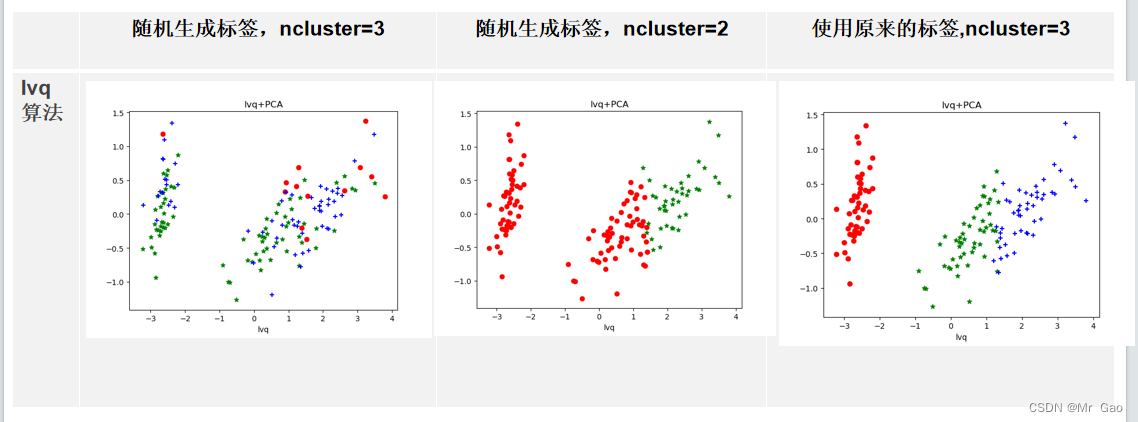
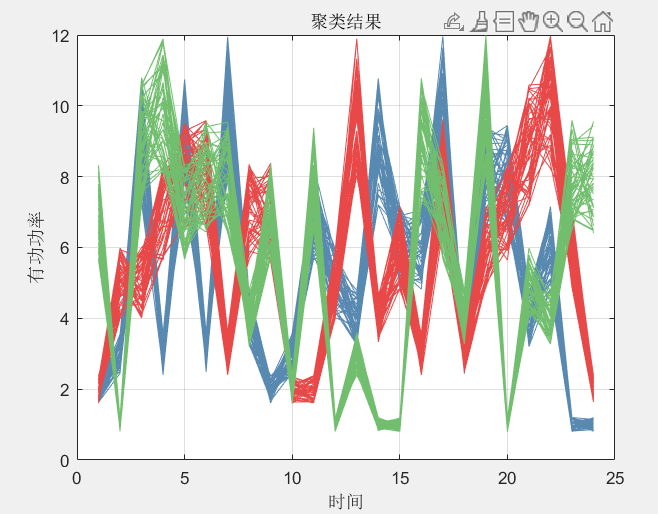
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比 注:下面的代码可能需要做一点参数调整,才得到所有我的运行结果。 kmeans算法: import matplotlib.pyplot as plt # 导入matplotlib的库import numpy as np # 导入numpy的包from sklearn import datase
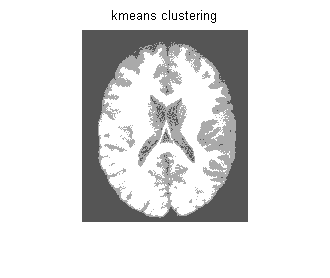
kmeans算法分割图像
算法 Input an image: Step1: Initialize: Step2: Repeat until convergence:{ }算法与Matlab比较 代码和实验结果 clearclcimg = imread('brainweb91.tif');img = rgb2gray(img);im = double(img);k=3;[mu,mask]
Kmeans和KNN算法的异同
Kmeans和KNN(K近邻)算法是聚类cluster中经典的算法,两者既有类似性也存在不同点。 两个算法的缺点:无法自行自动确定样本分类数量,需要先验知识! K-means是无监督学习,而KNN(K近邻)是监督学习,需要样本标注! Kmeans算法的思想: 随机给出数据的k个类的初始点,然后遍历所有的数据点,样本到各个初始点的距离(欧拉或者曼哈顿距离),距离最小的则将该样本归为当前
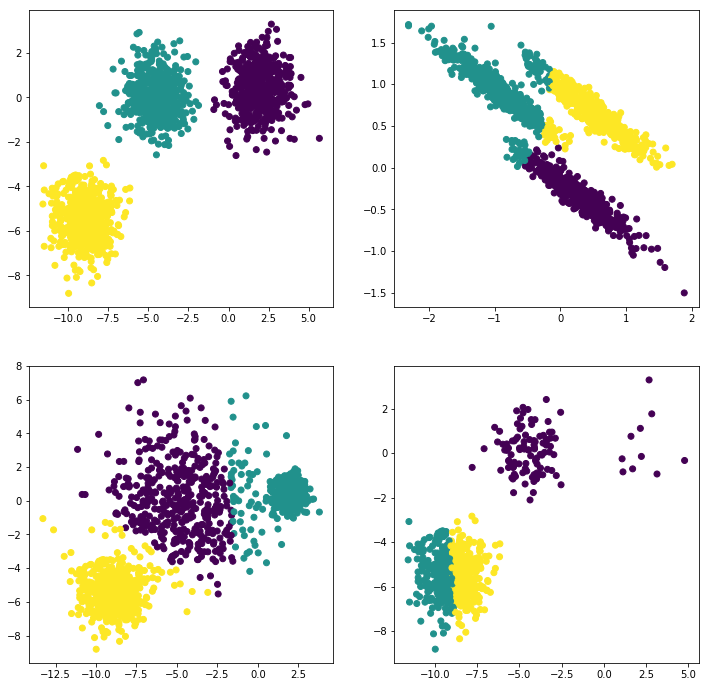
17行代码实现kmeans
恩,当然是用库了。计算点与点之间距离,用scipy中的cdist,这点是半年前吧看的一篇代码学的。 kmeans原理就不介绍了,很简单的。代码如下: def kmeans(k,data):length = len(data)# width = len(data[0])zeros = np.array([0]*length)new_data = np.column_stack((data,z
PCL 基于马氏距离KMeans点云聚类
文章目录 一、简介二、算法步骤三、代码实现四、实现效果参考资料 一、简介 在诸多的聚类方法中,K-Means聚类方法是属于“基于原型的聚类”(也称为原型聚类)的方法,此类方法均是假设聚类结构能通过一组原型刻画,在现实聚类中极为常用。通常情况下,该类算法会先对原型进行初始化,然后再对原型进行迭代更新求解。采用不同的原型表示、不同的求解方式,也将会产生不同的算法。 K-Mea
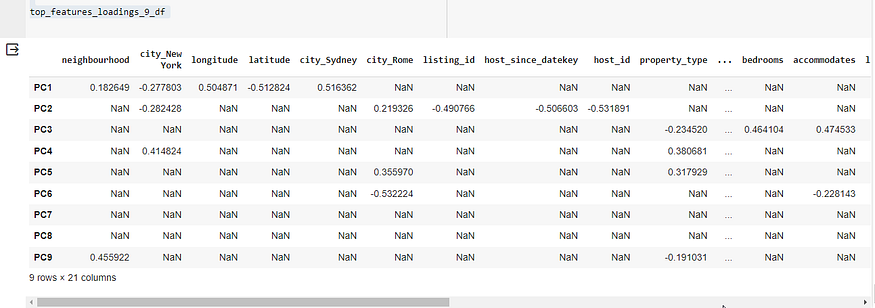
数据挖掘中的PCA和KMeans:Airbnb房源案例研究
目录 一、PCA简介 二、数据集概览 三、数据预处理步骤 四、PCA申请 五、KMeans 聚类 六、PCA成分分析 七、逆变换 八、质心分析 九、结论 十、深入探究 10.1 第 1 步:确定 PCA 组件的最佳数量 10.2 第 2 步:使用 9 个组件重做 PCA 10.3 解释 PCA 加载和特征贡献 10.4 9项常设仲裁法院的分析与解读 10.5 如何进行主题分析
基于kmeans的聚类微博舆情分析系统
第一章绪论 1.1研究背景 如今在我们的生活与生产的每个角落都可以见到数据与信息的身影。自从上十世纪八十年代的中后期开始,我们使用的互联网技术已经开始快速发展,近些年来云计算、大数据和物联网等与互联网有相领域的发展让互联网技术达到了史无前例的高度,信息技术与金融、科研、交通等各个方面也都产生了很多交集与融合,它催生了数量级数据的极速增长,因此人类也就进入到了大数据的时代。在互联网领域中数据迅速

电商-广告投放效果分析(KMeans聚类、数据分析-pyhton数据分析
电商-广告投放效果分析(KMeans聚类、数据分析) 文章目录 电商-广告投放效果分析(KMeans聚类、数据分析)项目介绍数据数据维度概况数据13个维度介绍 导入库,加载数据数据审查相关性分析数据处理建立模型聚类结果特征分析与展示数据结论 项目介绍 数据 假如公司投放广告的渠道很多,每个渠道的客户性质也可能不同,比如在优酷视频投广告和今日头条投放广告,效果可能会有差异。现