本文主要是介绍相关系数从PCC到MIC(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一般来说,当谈到两个变量之间的相关性(correlation)时,在某种意义上是指他们的关系(relatedness)。
相关变量是包含彼此信息的变量,两个变量的相关性约强,其中一个变量可以透露给我们另一个变量的信息就越多。
相关性并不意味着因果关系
即使是两个变量之间有强相关性也不保证存在因果关系。观察到的相关性可能是由于隐藏的第三个变量的影响,或者完全是偶然的。也就是说,相关性确实允许基于另一个变量来预测一个变量。
从协方差到皮尔森PCC相关系数
皮尔逊相关系数(PCC, 或者 Pearson’s r)是一种广泛使用的线性相关性的度量,它通常是很多初级统计课程的第一课。从数学角度讲,它被定义为「两个向量之间的协方差,通过它们标准差的乘积来归一化」。
两个成对的向量之间的协方差是它们在均值上下波动趋势的一种度量,即衡量一对向量是否倾向于各自平均值的同侧或相反。
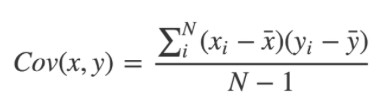
协方差的计算方法是从每一对变量中减去各自的均值。然后,将这两个值相乘。
- 如果都高于或低于均值,那么结果为正x正=正或负x负=正,均为正数。
- 如果在均值的不同侧,则为正x负=负,均为负数。
一旦我们为每一对变量都计算出这些值,将它们加在一起,并除以 n-1,其中 n 是样本大小。这就是样本协方差。如果这些变量都倾向于分布在各自均值的同一侧,协方差将是一个正数;反之,协方差将是一个负数。这种倾向越强,协方差的绝对值就越大。
如果不存在整体模式,那么协方差将会接近于零。这是因为正值和负值会相互抵消。
最初,协方差似乎是两个变量之间「关系」的充分度量。但是,请看下面的图:
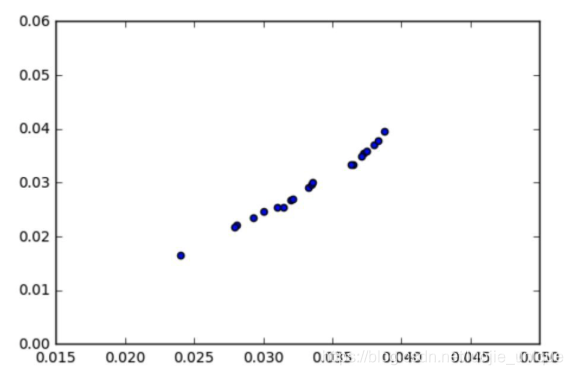
协方差 = 0.00003
看起来变量之间有很强的关系,对吧?那为什么协方差这么小呢(大约是 0.00003)?这里的关键是要认识到协方差是依赖于比例的。看一下 x 和 y 坐标轴——几乎所有的数据点都落在了 0.015 和 0.04 之间。协方差也将接近于零,因为它是通过从每个个体观察值中减去平均值来计算的。
为了获得更有意义的数字,归一化协方差是非常重要的。方法是将其除以两个向量标准差的乘积
即协方差与标准差的比值。
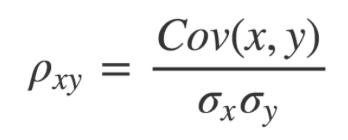
公式的分母是变量的标准差,这就意味着计算皮尔森相关性系数时,变量的标准差不能为0(分母不能为0),也就是说你的两个变量中任何一个的值不能都是相同的。如果没有变化,用皮尔森相关系数是没办法算出这个变量与另一个变量之间是不是有相关性的。
就好比我们想研究人跑步的速度与心脏跳动的相关性,如果你无论跑多快,心跳都不变(即心跳这个变量的标准差为0),或者你心跳忽快忽慢的,却一直保持一个速度在跑(即跑步速度这个变量的标准差为0),那我们都无法通过皮尔森相关性系数的计算来判断心跳与跑步速度到底相不相关。
因此它对数据要求比较高:
- 实验数据通常假设是成对的来自于正态分布的总体。因为我们在求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。
- 实验数据之间的差距不能太大,或者说皮尔森相关性系数受异常值的影响比较大。比如刚才心跳与跑步的例子,如果这个人突发心脏病,这时候我们会测到一个偏离正常值的心跳(过快或者过慢,甚至为0),如果我们把这个值也放进去进行相关性分析,它的存在会大大干扰计算的结果的。
皮尔森相关系数是衡量线性关联性的程度,p的一个几何解释是其代表两个变量的取值根据均值集中后构成的向量之间夹角的余弦。当两个向量完全相关时,两个向量之间协方差的最大值等于他们的标准差的乘积。这将相关系数限制在-1到+1之间。(相关系数越靠近0,相关性越弱,越靠近1表示正相关)
向量解释的PCC
现在,我们可以利用向量可以看做指向特定方向的「箭头」的事实。
例如,在 2-D 空间中,向量 [1,3] 可以代表一个沿 x 轴 1 个单位,沿 y 轴 3 个单位的箭头。同样,向量 [2,1] 可以代表一个沿 x 轴 2 个单位,沿 y 轴 1 个单位的箭头。
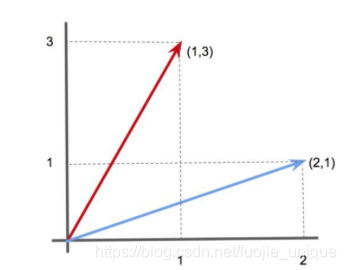
类似地,我们可以将数据向量表示为 n 维空间中的箭头(尽管当 n > 3 时不能尝试可视化)。
这些箭头之间的角度 ϴ 可以使用两个向量的点积来计算。定义为:
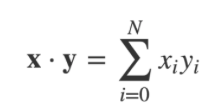
点积也可以被定义为:
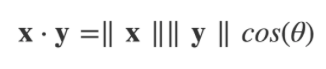
其中 || x || 是向量 x 的大小(或「长度」)(参考勾股定理),ϴ 是箭头向量之间的角度。我们通过将点积除以两个向量大小的乘积的方法得到 cos(ϴ)。
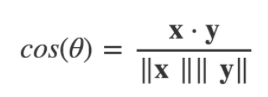
cos(ϴ) 的值将根据两个箭头向量之间的角度而发生变化。
- 当角度为零时(即两个向量指向完全相同的方向),cos(ϴ) 等于 1。
- 当角度为 -180°时(两个向量指向完全相反的方向),cos(ϴ) 等于 -1。
- 当角度为 90°时(两个向量指向完全不相关的方向),cos(ϴ) 等于 0。
那么——这正是它的解释!通过将数据视为高维空间中的箭头向量,我们可以用它们之间的角度 ϴ 作为相似度的衡量。该角度 ϴ 的余弦在数学上与皮尔逊相关系数相等。当被视为高维箭头时,正相关向量将指向一个相似的方向。负相关向量将指向相反的方向。而不相关向量将指向直角。
统计显著性
PCC 估计的置信区间不是完全直接的。这是因为 Pearson’s r 被限制在 -1 和 +1 之间,因此不是正态分布的。而估计 PCC,例如 +0.95 之上只有很少的容错空间,但在其之下有大量的容错空间。
幸运的是,有一个解决方案——用一个被称为 Fisher 的 Z 变换的技巧:
- 像平常一样计算 Pearson’s r 的估计值。
- 用 Fisher 的 Z 变换将 r→z,用公式 z = arctanh® 完成。
- 现在计算 z 的标准差。幸运的是,这很容易计算,由 SDz = 1/sqrt(n-3) 给出,其中 n 是样本大小。
- 选择显著性阈值,alpha,并检查与此对应的平均值有多少标准差。如果取 alpha = 0.95,用 1.96。
- 通过计算 z+(1.96 × SDz) 找到上限,通过计算 z - (1.96 × SDz) 找到下限。
- 用 r = tanh(z) 将这些转换回 r。
- 如果上限和下限都在零的同一侧,则有统计显著性!
当给定一个包含许多潜在相关变量的大数据集时,检查每对的相关性可能很吸引人。这通常被称为「数据疏浚」——在数据集中查找变量之间的任何明显关系。
如果确实采用这种多重比较方法,则应该用适当的更严格的显著性阈值来降低发现错误相关性的风险(即找到纯粹偶然相关的无关变量)。
一种方法是使用 Bonferroni correction。
下一节讲距离相关性
原文参考
这篇关于相关系数从PCC到MIC(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








