本文主要是介绍Semi-supervised medical image segmentation via uncertainty rectified pyramid consistency 半监督医学图像分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
↵
现在由于深度学习有监督分割基本也搞到头了,各种新网络新结构层出不穷,人们把精力主要放到了半监督分割任务上了。半监督学习旨在通过结合少量标记数据和大量未标记数据来取得可喜的结果,因此关键步骤是为未标记数据设计有效的监督。因此,已经提出了许多方法来有效地利用未注释的图像。今天看到一篇毕竟好的论文,整个思路并不复杂,给人感觉,原来还可以这么弄呀。
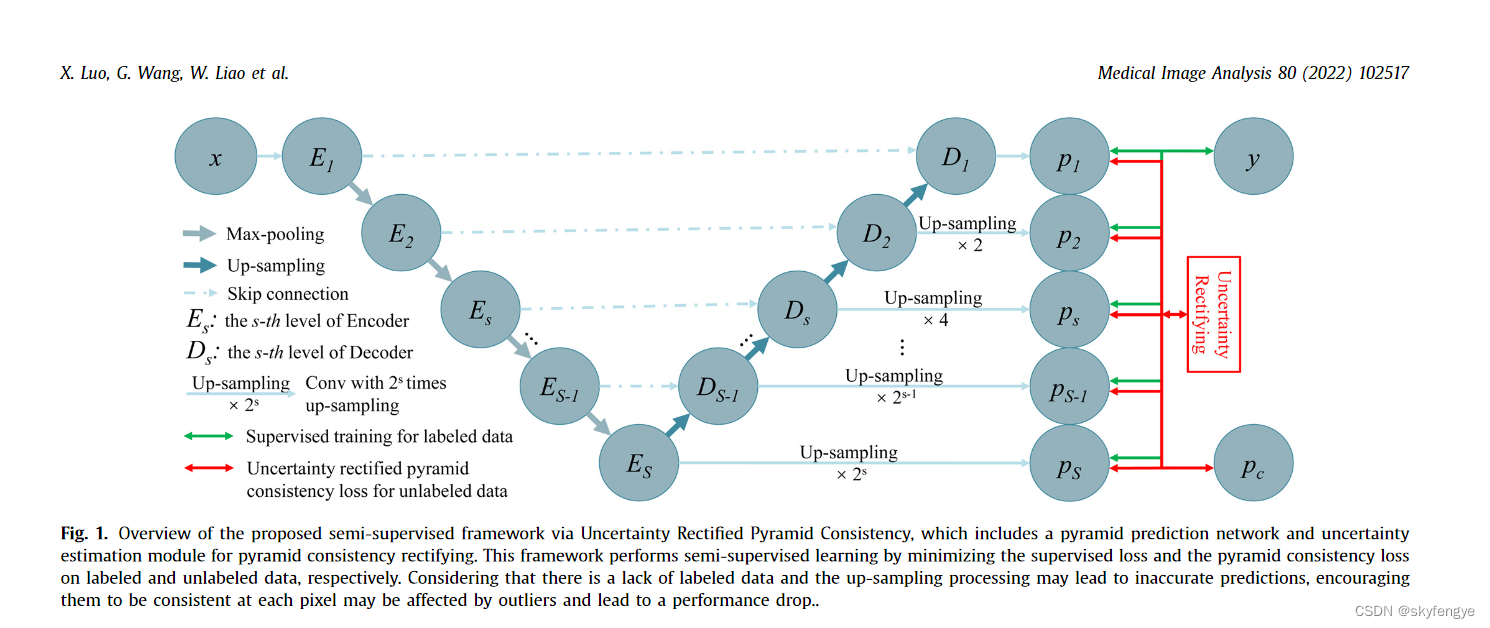
通过图片,我们可以发现,这是一个典型的UNet 神经网络,加了金字塔结构。其实网络可以弄的并不复杂。
这篇关于Semi-supervised medical image segmentation via uncertainty rectified pyramid consistency 半监督医学图像分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







