本文主要是介绍Rethinking ImageNet Pre-training 重新审视Imagenet预训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Rethinking ImageNet Pre-training 2018年ECCV
论文地址:https://arxiv.org/pdf/1811.08883.pdf
本论文是何凯明大神的一篇论文,主要是讨论了Imagenet预训练和随机初始化参数之间的区别。
论文摘要:
作者在COCO数据集上进行实例分割和检测测试,发现预训练+微调的效果和随机初始化的效果接近。并且随机初始化的网络训练有很强的的鲁邦性特别是在:1.使用10%的训练集 2.更深更复杂的网络结构中 3.使用多个任务和指标 这三种情况下。只是随机初始化需要更多的迭代次数。
论文引言:
深度卷积神经网络方法为计算机视觉领域带来了新的活力,换言之,是因为发现使用预训练任务中学到的特征表示,能够将其中有用的信息传递给另一目标任务。近年来,一个通用的方法(模式)是使用大规模数据(例如 ImageNet )对模型进行预训练,然后在具有较少训练数据的目标任务上对模型进行微调。预训练模型已经在许多任务上实现了最先进(state of the art)的结果,包括物体检测,图像分割和动作识别等任务。但这种方法(预训练加微调)真的能解决计算机视觉领域的问题吗?我们提出了质疑。因此,通过实验展示了在 COCO 数据集上,我们使用随机初始化方法训练取得了和使用 ImageNet 预训练方法相媲美的结果,而且我们还发现仅使用 10% 的COCO 数据也能训练到差不多的结果。
作者通过实验得到下面的三条结论:
1. Imagenet预训练在训练初期可以加速训练。但是预训练+微调的训练时间等同于随机初始化训练时间。
2. 预训练并不会提供更好的正则化效果。但训练数据集较小时,必须选择新的超参数来避免过拟合。
3. 基于分类的,类似 ImageNet 图片集的预训练任务和对局部敏感的目标任务,三者之间的差异可能会限制预训练方法发挥其功能。
论文实验设置:
正则化:
Batch Normalization(BN):在随机初始化的网络中的作用不大。BN 策略的引入虽然可以减少批量大小内存,但是小批量的输入会严重降低模型的准确性。 论文中引入的两种正则化方法,缓解小批量输入问题:
1. Group Normalization (GN):GN 方法的计算与输入的批量维度无关,因此引用该正则化方法时,模型准确性对输入的批量大小并不敏感。
2.Synchronized Batch Normalization (SyncBN): 可以统计多个设备的批量大小。当使用多个GPU 时,该正则化方法能够增加BN 的有效批量大小,从而避免小批量输入的问题。
实验表明 GN和SyncBN正则化策略是有效的。VGG再不需要GN和SycnBN的情况下效果也很好。
收敛性:

图中分别是图片,实例和像素三种情况下的对比。紫色的是随机初始化。浅绿色和绿色表示的是预训练+微调。图中可以看出来紫色的是绿色的三倍左右。但是预训练+微调都大于随机初始化。
实验结果:
实验设置:采用 Mask R-CNN,ResNet 或 ResNeXt,并采用特征金字塔网络(FPN)作为我们模型的主体结构,并采用端到端的方式(end-to-end)来训练 RPN 和 Mask R-CNN。此外,GN/SyncBN 代替所有 frozen BN 层(逐通道的仿射变换)。为了公平比较,在研究过程中我们对预训练模型同样采用 GN 或 SyncBN 正则化策略进行微调。
在 8 个 GPU 上,采用 synchronized SGD,每个 GPU 上 mini-batch 大小为 2,来训练所有模型。


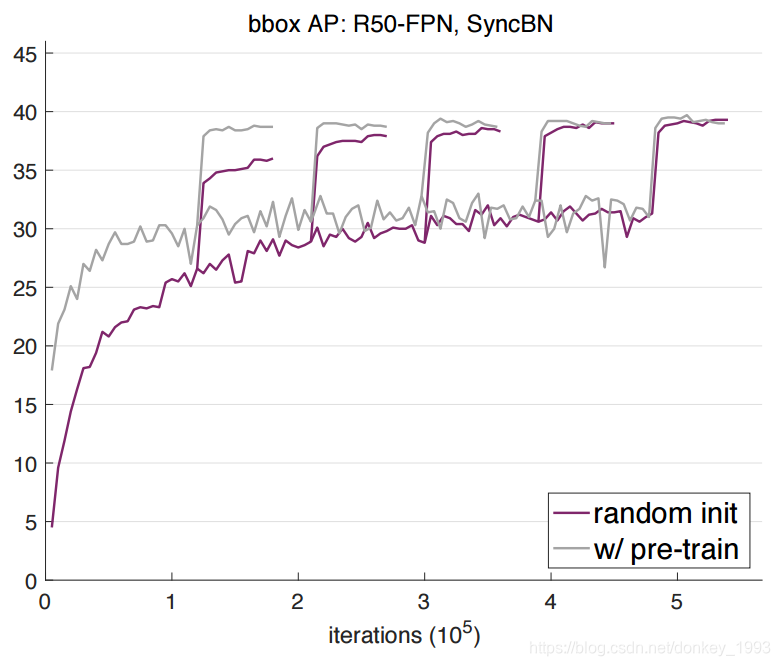
从结果可以看出来随着训练次数的迭代,预训练+微调的最终效果和随机初始化参数的效果基本接近。
作者还在文章的最后给大家做了一个总结:
ImageNet 预训练是否有必要?事实并非如此,如果我们有足够的目标数据和计算资源的话,也许我们可以不依赖 ImageNet 的预训练。我们的实验结果表明,ImageNet 预训练可以帮助模型加速收敛过程,但是并不一定能提高最终的准确性,除非数据集特别小(例如,<10k COCO images)。这表明,在未来的研究中,收集目标数据的标注信息(而不是预训练数据)对于改善目标任务的表现是更有帮助的。
ImageNet有用吗?确实是有用的。ImageNet 预训练一直以来是计算机视觉领域许多任务性能辅助工具。它能够减少了训练的周期,更容易获得有前途的结果,经预训练的模型能够多次使用,训练成本很低。此外,经预训练的模型能够有更快的收敛速度。我们相信 ImageNet 预训练仍然有助于计算机视觉研究。
我们需要大数据吗?的确需要。但如果我们考虑数据收集和清理的成本的话,一个通用的大规模分类的数据集并不是理想的选择。因为收集诸如 ImageNet 这样大数据集的成本被忽略掉了,而在数据集上进行预训练步骤的成本也是庞大的。如果在大规模的分类数据集上预训练的收益呈指数型下降减少,那么在目标域上收集数据将会是更有效的做法。
我们应该追求通用的模型性能吗?毫无疑问,我们的目标是模型能够学习到通用的特征表征。我们所取得的结果也没有偏离这一目标。其实,我们的研究表明在计算机视觉领域,我们应该更加注意评估预训练的特征(例如对于自监督过程的特征学习),就像现在我们学到的那样,即使是随机初始化过程也能得到出色的结果表现。
这篇关于Rethinking ImageNet Pre-training 重新审视Imagenet预训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







