rethinking专题

姿态估计Rethinking on Multi-Stage Networks for Human Pose Estimation论文梗概及代码解读
2018年COCO关键点检测冠军算法MSPN,姿态估计,Top-down的技术路线 应该是截止2019年10月26日时开源的最好的姿态估计算法之一了 旷世出品 代码链接点这,是基于Pytorch的 论文链接点这 摘要 姿态估计方法以基本形成one-stage 和 multi-stage两个路线 多阶段看上去更适合任务,但是现在多阶段的性能还是不如单阶段的 我们论文就来研究这个问题,我们讨论当下

【模型裁剪】——Rethinking the Value of Network Pruning
论文:https://arxiv.org/pdf/1810.05270.pdf code:https://github.com/Eric-mingjie/rethinking-network-pruning 转载自:https://blog.csdn.net/zhangjunhit/article/details/83506306 网络模型裁剪价值的重新思考 当前的深度学习网络模型一般都
Rethinking overlooked aspects in vision-language models
探讨多模态视觉语言模型的一些有趣结论欢迎关注 CVHub!https://mp.weixin.qq.com/s/zouNu-g-33_7JoX3Uscxtw1.Introduction 多模态模型架构上的变化不大,数据的差距比较大,输入分辨率和输入llm的视觉token大小是比较关键的,适配器,VIT和语言模型则不是那么关键。InternVL-1.5,Qwen-VL-Max和De

18-Rethinking-ImageNet-Pre-training
what 在目标检测和实例分割两个领域,我们使用随机初始化方法训练的模型,在 COCO 数据集上取得了非常鲁棒的结果。其结果并不比使用了 ImageNet 预训练的方法差,即使那些方法使用了 MaskR-CNN 系列基准的超参数。在以下三种情况,得到的结果仍然没有降低: 仅使用 10% 的训练数据;使用更深和更宽的模型使用多个任务和指标。 ImageNet 预训练模型并非必须,ImageNe

模型剪枝——RETHINKING THE VALUE OF NETWORK PRUNING
1.概述 神经网络的过度参数化是众所周知的,导致在推理时计算成本高,内存占用大。作为解决办法,网络剪枝被认为是提高有限计算预算应用中深度网络效率的有效技术。典型的剪枝算法包括三个阶段:训练(一个大型模型)、剪枝和微调。 普遍信念的挑战: 大模型训练的必要性:普遍认为从大型网络开始训练是重要的,因为它可以生成高性能模型。但研究发现,对于结构化剪枝方法,直接训练目标模型可以获得同

CVPR 2024 - Rethinking the Evaluation Protocol of Domain Generalization
CVPR 2024 - Rethinking the Evaluation Protocol of Domain Generalization 论文:https://arxiv.org/abs/2305.15253原始文档:https://github.com/lartpang/blog/issues/8 这篇文章主要讨论了领域泛化评估协议的重新思考,特别是如何处理可能存在的测试数据信息泄

Rethinking eventual consistency论文部分段落翻译
这篇论文貌似有两页格式不大友好,导致翻译软件无法识别,现在提供这部分的中文翻译(我也是自己弄的,质量不一定佳,需者自取) 链接: Rethinking eventual consistency论文部分段落翻译

论文笔记:UNDERSTANDING PROMPT ENGINEERINGMAY NOT REQUIRE RETHINKING GENERALIZATION
ICLR 2024 reviewer评分 6888 1 intro zero-shot prompt 在视觉-语言模型中,已经取得了令人印象深刻的表现 这一成功呈现出一个看似令人惊讶的观察:这些方法相对不太受过拟合的影响 即当一个提示被手动工程化以在给定训练集上达到低错误率时(从而使得该方法实际上不再是零次学习),该方法在保留的测试数据上仍然表现良好。论文试图从理论上解释这一点 使用了经典的

论文解读:Rethinking Generalization in Few-Shot Classification
文章汇总 问题 ImageNet[38]这样流行的计算机视觉数据集总是给出单一标签来描述整张图片,而这样的标签只能正确地描述实际图像的一小部分,这不利于模型的训练;特别在测试期间,不属于训练类集合的实体,可能被认为是不相关的实体,很可能是测试类集合的一部分。 动机 参考文章近年来,小样本学习取得重大进展了吗? - 知乎 解决单label的annotation问题,比如 一张图60%
18-Rethinking-ImageNet-Pre-training
what 在目标检测和实例分割两个领域,我们使用随机初始化方法训练的模型,在 COCO 数据集上取得了非常鲁棒的结果。其结果并不比使用了 ImageNet 预训练的方法差,即使那些方法使用了 MaskR-CNN 系列基准的超参数。在以下三种情况,得到的结果仍然没有降低: 仅使用 10% 的训练数据;使用更深和更宽的模型使用多个任务和指标。 ImageNet 预训练模型并非必须,ImageNe
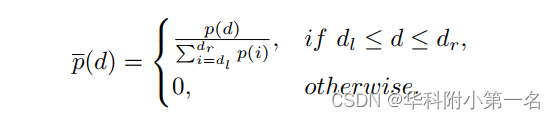
【论文简述】Rethinking Cross-Entropy Loss for Stereo Matching Networks(arxiv 2023)
一、论文简述 1. 第一作者:Peng Xu 2. 发表年份:2023 3. 发表期刊:arxiv 4. 关键词:立体匹配,交叉熵损失,过渡平滑和不对准问题,跨域泛化 5. 探索动机:立体匹配通常被认为是深度学习中的一个回归任务,通常采用平滑L1损失结合Soft-Argmax估计器来训练网络,达到亚像素级的视差精度。然而,平滑L1损失缺乏对代价体的直接约束,在训练过程中容易出现过拟合。S

论文阅读002-Inception V3-Rethinking the Inception Architecture for ComputerVision
Inception v3 使用场景 内存和计算量有限的情况,比如移动设备 设计原则(作者强调了以下原则并不是一定正确,要结合实际运用场景来评估) 1、Avoid representational bottlenecks, especially early in the network. 个人理解是不要一开始就给图像特征降维,要不然会丢失信息?还有就是不能只通过特征维度来理解图像。 2、Highe
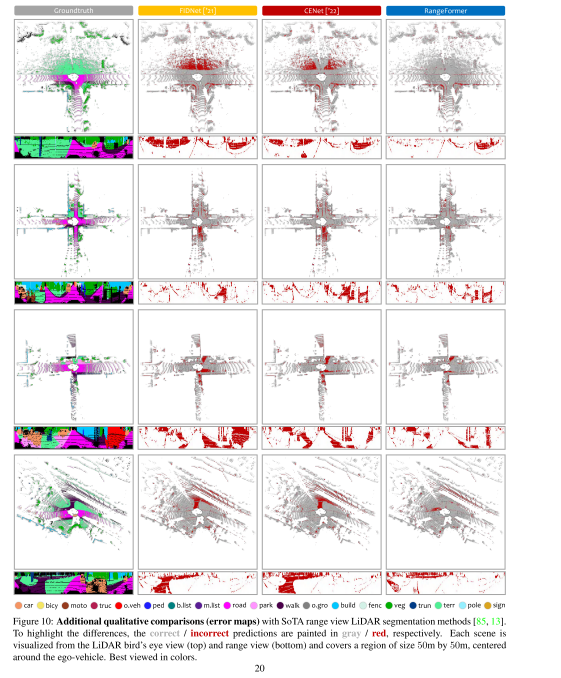
论文阅读:Rethinking Range View Representation for LiDAR Segmentation
来源ICCV2023 0、摘要 LiDAR分割对于自动驾驶感知至关重要。最近的趋势有利于基于点或体素的方法,因为它们通常产生比传统的距离视图表示更好的性能。在这项工作中,我们揭示了建立强大的距离视图模型的几个关键因素。我们观察到,“多对一”的映射,语义不连贯性,形状变形的可能障碍对有效的学习从距离视图投影。我们提出的RangeFormer -一个全周期的框架,包括跨网络架构,数据增强和后处理的
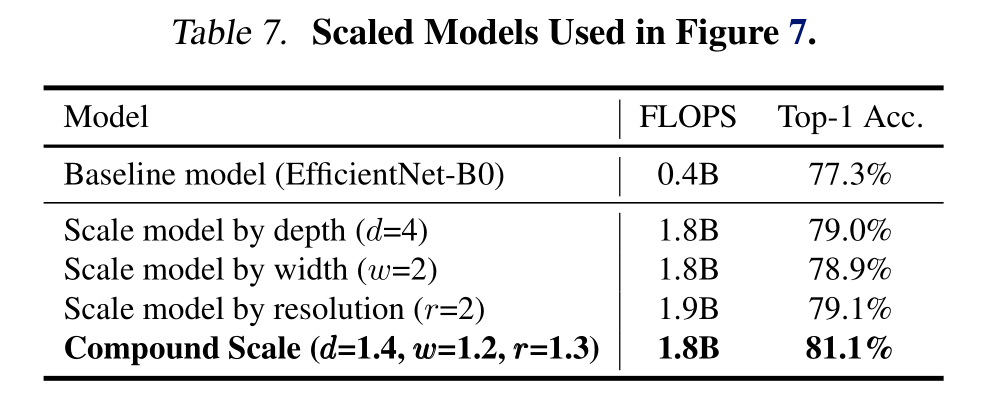
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(2020)
文章目录 -Abstract1. Introductiondiss former methodour method 2. Related Work3. Compound Model Scaling3.1. 问题公式化3.2. Scaling Dimensions3.3. Compound Scaling 4. EfficientNet Architecture5. Experiments6

深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现
深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现 Rethinking “Batch” in BatchNorm PDF: https://arxiv.org/pdf/2105.07576.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代码: https://

【深度学习】语义分割-论文阅读:( CVPR 2021)SETR:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspe
这里写目录标题 0.详情1. 摘要2. 引言2.1 原来的模型:FCN2.2 使用transformers2.3 主要贡献 3. 相关工作-语义分割模型发展3.1 以前基于FCN的改进3.2 基于transformer的改进 4. 方法4.1 基于FCN的语义分割4.2 SETR4.3 解码器设计 5 总结6.实验-复现 0.详情 名称:Rethinking Semantic S
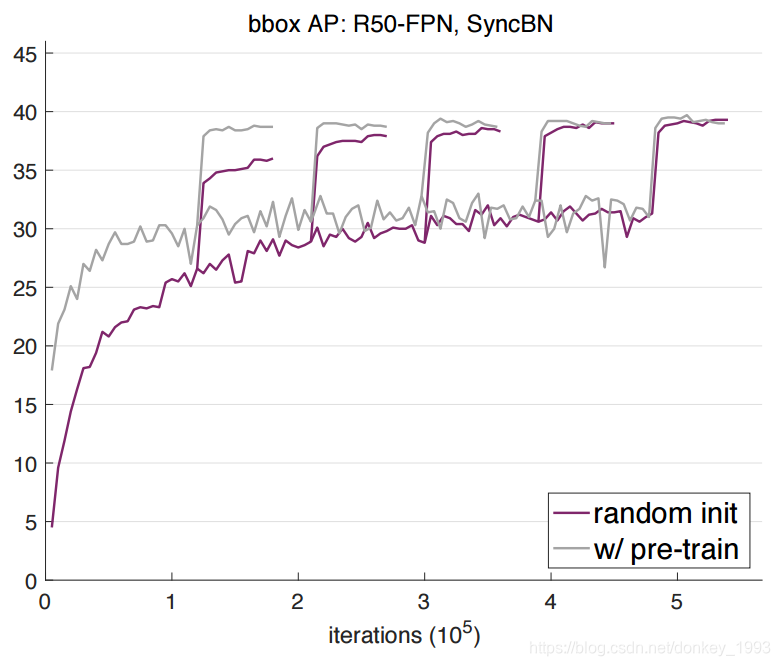
Rethinking ImageNet Pre-training 重新审视Imagenet预训练
Rethinking ImageNet Pre-training 2018年ECCV 论文地址:https://arxiv.org/pdf/1811.08883.pdf 本论文是何凯明大神的一篇论文,主要是讨论了Imagenet预训练和随机初始化参数之间的区别。 论文摘要: 作者在COCO数据集上进行实例分割和检测测试,发现预训练+微调的效果和随机初始化的效果接近。并且随机初始化的网络

Rethinking SIMD Vectorization for In-Memory Databases 论文阅读笔记
Rethinking SIMD Vectorization for In-Memory Databases 论文阅读笔记 基本操作 selective store 将 vector lane 的一部分(根据 mask)写入连续内存 selective load 从连续内存读入到 vector lane 的一部分(根据 mask) selective gather 从非连续内存
论文阅读:Rethinking Range View Representation for LiDAR Segmentation
来源ICCV2023 0、摘要 LiDAR分割对于自动驾驶感知至关重要。最近的趋势有利于基于点或体素的方法,因为它们通常产生比传统的距离视图表示更好的性能。在这项工作中,我们揭示了建立强大的距离视图模型的几个关键因素。我们观察到,“多对一”的映射,语义不连贯性,形状变形的可能障碍对有效的学习从距离视图投影。我们提出的RangeFormer -一个全周期的框架,包括跨网络架构,数据增强和后处理的
论文阅读:Rethinking Range View Representation for LiDAR Segmentation
来源ICCV2023 0、摘要 LiDAR分割对于自动驾驶感知至关重要。最近的趋势有利于基于点或体素的方法,因为它们通常产生比传统的距离视图表示更好的性能。在这项工作中,我们揭示了建立强大的距离视图模型的几个关键因素。我们观察到,“多对一”的映射,语义不连贯性,形状变形的可能障碍对有效的学习从距离视图投影。我们提出的RangeFormer -一个全周期的框架,包括跨网络架构,数据增强和后处理的
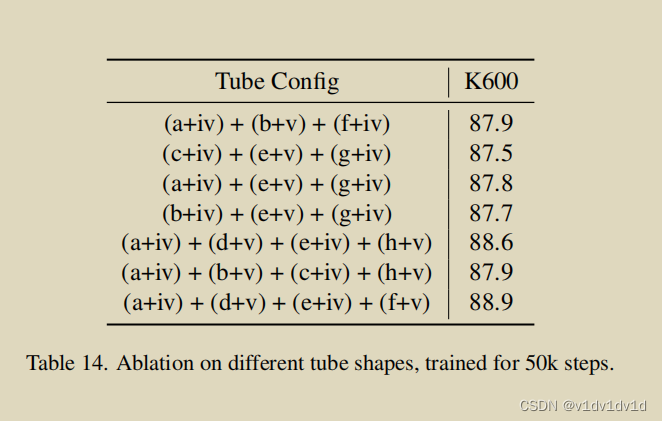
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning(TubeViT论文翻译)
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning AJ Piergiovanni Weicheng Kuo Anelia Angelova 论文链接 Abstract 我们提出了一个将ViT编码器变成一个有效的视频模型的方法,它可以无缝地处理图像和视频输入。通过对输入进行稀疏采样,该模型能
【点云处理之论文狂读前沿版1】——Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP
重新审视点云处理中的网络设计和局部几何结构——一个简单的残差MLP框架 1.摘要2.引言2.相关工作3.方法3.1 Revisiting point-based methods3.2 PointMLP的框架结构3.3 Geometric Affine Module3.4 计算复杂度和Elite版 4.实验4.1 Shape classification on ModelNet4.2 Shap

Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach 重新思考文本分割:一种新的数据集和文本细化方法 代码地址:https://github.com/SHI-Labs/Rethinking-Text-Segmentation 作者模型测试结果: 自己训练模型测试结果: 摘要