本文主要是介绍利用图神经网络(GNN)的视频/图像分割模型总结(AGNN、Episodic Graph Memory Networks、Cas-GNN),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:Zero-shot VOS即为零样本视频对象分割,指在验证阶段不会向网络输入除待测视频本身以外的其他注释样本,下文记为 Z-VOS;One-shot VOS即为单样本视频对象分割,也可称为自监督或半监督视频对象分割(semi-supervised VOS),指在验证阶段向网络输入辅助分割的注释样本(通常是待测视频第一帧的真实分割结果掩模),下文记为 O-VOS;Semantic Object Segmentation即为语义对象分割,下文记为SOS。
Ⅰ、AGNN(Z-VOS)
Attentive Graph Neural Networks
Wang W, Lu X, Shen J, et al. Zero-shot video object segmentation via attentive graph neural networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 9236-9245.
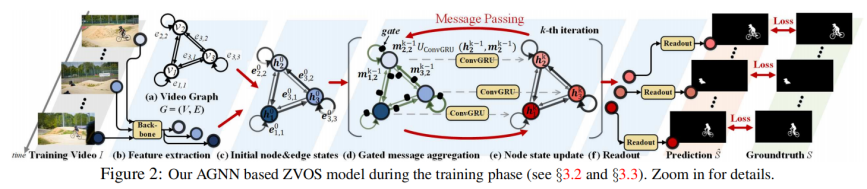
有loop-edge、intra-attention
v:结点,h:状态,g:门,m:消息
部分计算公式:

Ⅱ、Episodic Graph Memory Networks(O-VOS/Z-VOS)
Lu X, Wang W, Danelljan M, et al. Video object segmentation with episodic graph memory networks[C]//European Conference on Computer Vision. Springer, Cham, 2020: 661-679.
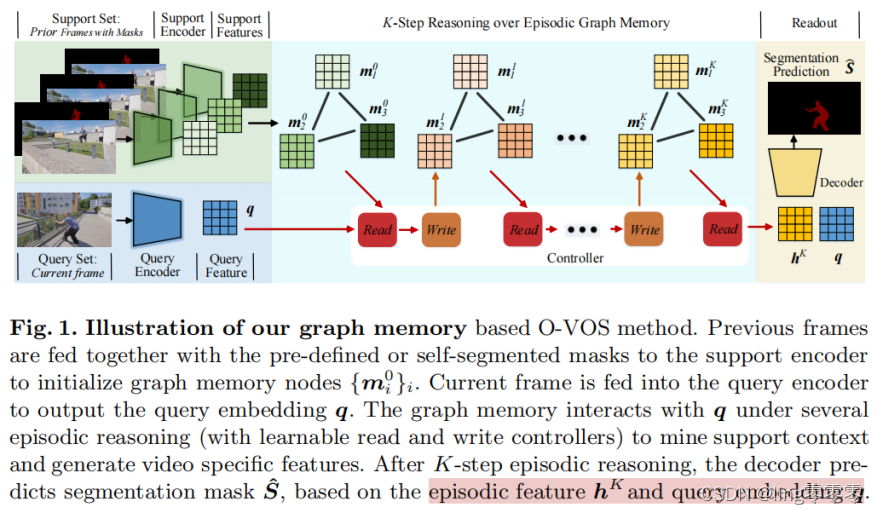
无loop-edge,
m:结点/消息,h:情景特征(状态),a:门
q:当前帧(自监督时)
部分计算公式:

论文里出现了一个词组,叫做 the label shuffling strategy(标签洗牌策略),它鼓励分割网络学习通过考虑当前的训练样本,而不是记忆目标和给定标签之间的特定关系,来区分当前框架中的特定实例
Ⅲ、Cas-GNN(SOS)
Cascade Graph Neural Networks
Luo A, Li X, Yang F, et al. Cascade graph neural networks for rgb-d salient object detection[C]//European Conference on Computer Vision. Springer, Cham, 2020: 346-364.
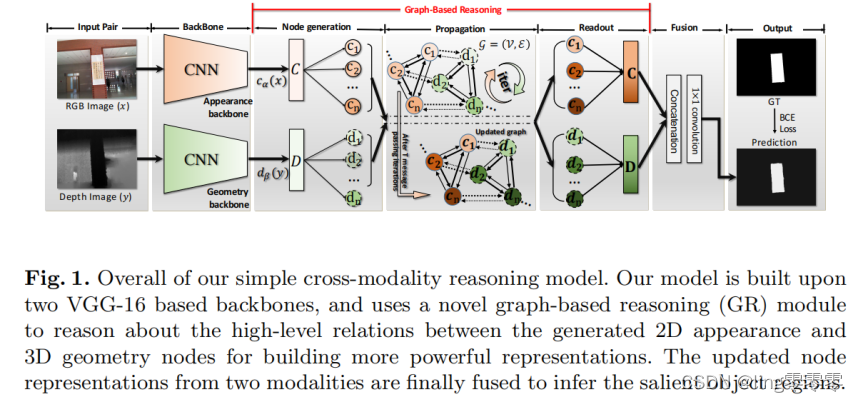
Node:多尺度颜色特征ci和深度特征di
Edge:1) ci或di之间,2) 相同尺度的ci和di之间
CNN:VNN-16,and use the dilated network technique(扩张网络技术) to ensure that the last two groups of VGG-16 have the same resolution
提取特征C和D后,用基于图的推理模型 Graph-based Reasoning (GR) module 推理跨模态的高阶关系,得到更强大的embeddings:

(比前两个多的一部分)
Hierarchical分层的GNN模型:由于它独立处理多层次推理过程,很难充分做到互利
Cascade Graph Reasoning (CGR) module 级联图推理模型:
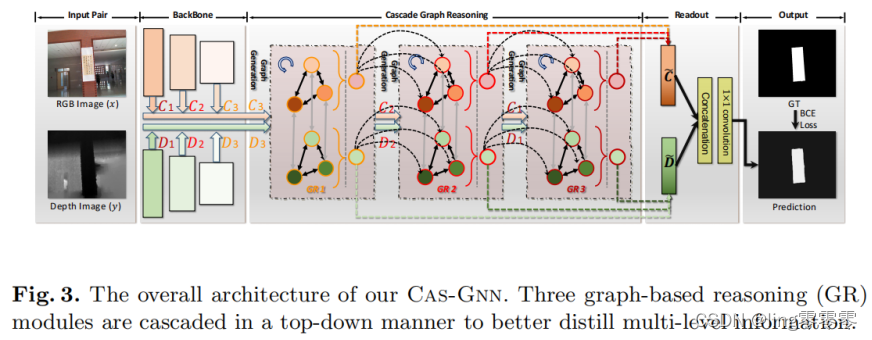
总结:
1、相同点:
流程(框架)基本相同:CNN提取特征(RGB/RGB+某一帧/RGB+D),用(视频片段的某几帧的特征/图片提取多尺度特征)表示成几个结点,(RGB自连+互连/RGB互连/RGB+D互连)形成图,迭代进行消息传递,最后的结点特征(状态)再读出成所要的S(预测)
2、不同点:
Ⅰ像是标配版
Ⅱ在Ⅰ的基础上加了自监督(O-VOS)(如果是Z-VOS感觉和Ⅰ差不多吧)
Ⅲ在Ⅰ的基础上加了级联图推理CGR
这篇关于利用图神经网络(GNN)的视频/图像分割模型总结(AGNN、Episodic Graph Memory Networks、Cas-GNN)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







