episodic专题
【博士每天一篇文献-算法】Gradient Episodic Memory for Continual Learning
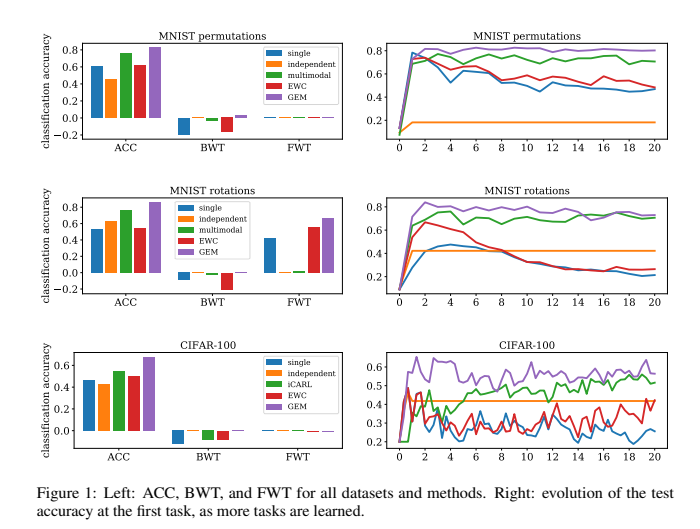
阅读时间:2023-10-26 1 介绍 年份:2017 作者:David Lopez-Paz, Marc’Aurelio Ranzato 期刊:Part of Advances in Neural Information Processing Systems 30 (NIPS 2017) 引用量:2044 针对持续学习中灾难性遗忘问题提出一种名为Gradient Episodic Memor

论文阅读笔记《Transductive Episodic-Wise Adaptive Metric for Few-Shot Learning》
小样本学习&元学习经典论文整理||持续更新 核心思想 本文提出了一种基于度量学习的小样本学习算法(TEAM),与其他基于度量学习的算法相比,本文在特征提取阶段采用了一种Task Internal Mixing (TIM)数据增强方法,设计了一种能够根据每个Episode进行自适应调整的距离度量方法Episodic-wise Adaptive Metric(EAM),并采用了一种双向相似性度
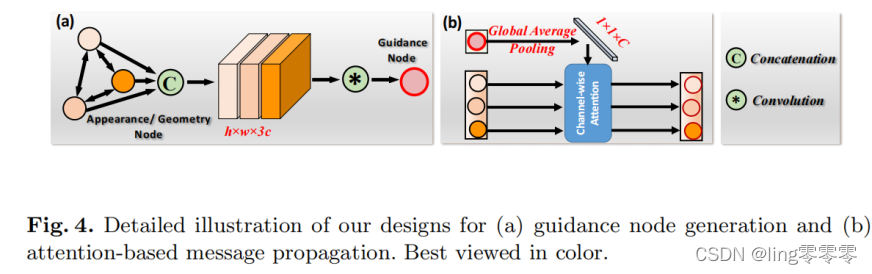
利用图神经网络(GNN)的视频/图像分割模型总结(AGNN、Episodic Graph Memory Networks、Cas-GNN)
注:Zero-shot VOS即为零样本视频对象分割,指在验证阶段不会向网络输入除待测视频本身以外的其他注释样本,下文记为 Z-VOS;One-shot VOS即为单样本视频对象分割,也可称为自监督或半监督视频对象分割(semi-supervised VOS),指在验证阶段向网络输入辅助分割的注释样本(通常是待测视频第一帧的真实分割结果掩模),下文记为 O-VOS;Semantic Object
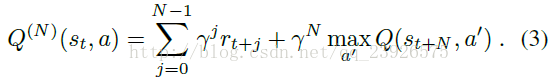
NEC:Neural Episodic Control 阅读
本文是google的DeepMind团队发布在arXiv上的文章,翻译过来是神经情景控制,相比于深度强化学习,可显著提高学习速度。 文章下载链接为:Neural Episodic Network 阅读本文需要了解的一些知识: 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端

Transductive Episodic-Wise Adaptive Metric for Few-Shot Learning 论文笔记
摘要 如何利用少量的数据学习到一个generalizable 的分类器目前仍旧是小样本学习的一个挑战,基于这个出发点,作者把元学习(meta-learning)和深度度量学习和归纳推理想结合,通过探索每个任务中成对约束和正则化,我们将适应过程明确地公式化为标准的半定规划问题。作者针对每个任务设计了一个情节性的(episodic-wise)度量矩阵来将通用的,任务不可知的编码空间转换到一个可判别性

神经情景控制(Neural Episodic Control)On arXiv By DeepMind
【声明:鄙人菜鸟一枚,写的都是入门级博客,如遇大神路过鄙地,请多赐教;内容有误,请批评指教,如有雷同,属我偷懒转运的,能给你带来收获就是我的博客价值所在。】 【声明】翻译:张永伟(系中国航天系统科学与工程研究院2016级研究生) 修订:博主 这期为大家推荐一篇2017年3月6日发表在 arXiv 上的文章,这篇文章介绍了一种”神经情景控制(Neural Episodic Control)“

论文阅读:Transductive Episodic-Wise Adaptive Metric for Few-Shot Learning(ICCV 2019)
论文阅读:Transductive Episodic-Wise Adaptive Metric for Few-Shot Learning(ICCV 2019) 三部分: 特征提取部分:运用了数据增强,将support set中所有样本处理一下(TIM),得到新的图片集,然后用CNN网络提取特征,query集也用同样的CNN网络提取特征。距离衡量部分:通过解决一个SDP问题来为
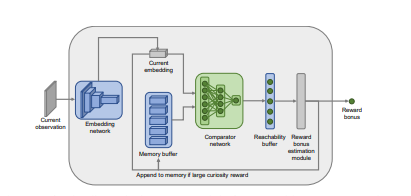
Episodic Curiosity through Reachability阅读笔记
在现实世界中,奖励很稀疏,而今天大多数的强化学习算法都在与这种稀疏性斗争。这个问题的一个解决方案是让智能体自己创造奖励,从而使奖励更加密集,更加适合学习。很多现实世界的任务都有稀疏的奖励,例如:寻找食物的动物可能需要走很多英里而没有来自环境的任何奖励。标准强化学习算法因为依赖简单的行动熵最大化作为探索行为的来源,所以在这些任务中表现挣扎。 很多现在的好奇心机制以意外最大化为目标,这种方法理论上很