本文主要是介绍Episodic Curiosity through Reachability阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在现实世界中,奖励很稀疏,而今天大多数的强化学习算法都在与这种稀疏性斗争。这个问题的一个解决方案是让智能体自己创造奖励,从而使奖励更加密集,更加适合学习。很多现实世界的任务都有稀疏的奖励,例如:寻找食物的动物可能需要走很多英里而没有来自环境的任何奖励。标准强化学习算法因为依赖简单的行动熵最大化作为探索行为的来源,所以在这些任务中表现挣扎。
很多现在的好奇心机制以意外最大化为目标,这种方法理论上很有道理,但是远非完美,在某些场景中无法有效预测未来。想象一下,智能体被置于一个3D迷宫中,迷宫某处有一个宝贵的目标,会给予大的奖励。环境中还有一台电视,智能体可以控制电视并换台。电视上的频道有限(每个频道的节目不同),遥控器上的每个按键可转换到随机频道。智能体在这样的环境中会有什么行为呢?对于基于意外的好奇心,换频道将带来大的奖励,因为每次换台的结果是不可预测、令人惊讶的。关键是,即使在所有频道换过一遍之后,随机频道选择也能确保之后的每次换台结果出人意料,智能体会对换台后的频道做出预测,预测很可能是错误的,并带来惊讶。重要的是,即使智能体已经看过每个频道的节目,换台结果仍然是不可预测的。因此,基于意外的好奇心的智能体将一直待在电视前面,而不是去寻找高奖励的物体。

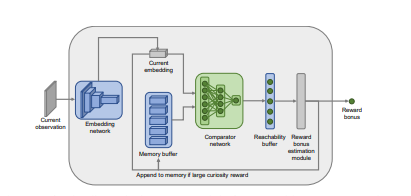
我们通过可达性来定义新奇,蓝色节点已经在内存中,绿色节点可以在k=2步之内从内存到达(不是新奇),橙色节点距离更远,需要超过k步才能到达(新奇)。在实践中,完整的可能性转换图是没有提供的,因此我们训练神经网络逼近器来预测观察点之间的步数是大于k,还是小于k。
还是上文电视机的例子,如果智能体在更改电视频道后知道观察结果,那么在此之前距离观察仅一步之遥,改变频道就不会那么容易带来意外了(太容易了)。这种方式可以形式化为只为那些需要付出努力的观察给予奖励到达(在已探索的环境部分之外)。
因此本文提出了一种新的思路,通过内存存储已经出现的场景,做出决策前,首先智能体会检查过去的信息,通过训练后的深度神经网络来衡量两种体验的的相似度,进而给出奖励。这里神经网络的训练是通过给定两个观察,预测分开它们需要多少步。
EPISODIC CURIOSITY

实习繁忙,待续,转载请注明。
这篇关于Episodic Curiosity through Reachability阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








