curiosity专题

Curiosity PIC32MZEF学习系列汇总
PIC32MZ EF系列新器件拥有频率高达250MHz的高性能内核、一个集成浮点运算单元(FPU)、丰富的外设以及包含控制器局域网(CAN)在内的各种功能卓越的连接选项。支持扩展级温度范围的新产品组合特别适用于汽车和工业领域的几种关键应用,因为这些应用都需要确保产品在更高温度条件下的可靠性能和稳定性。Curiosity PIC32MZEF+学习系列:开发环境建立Curiosity PIC32MZE
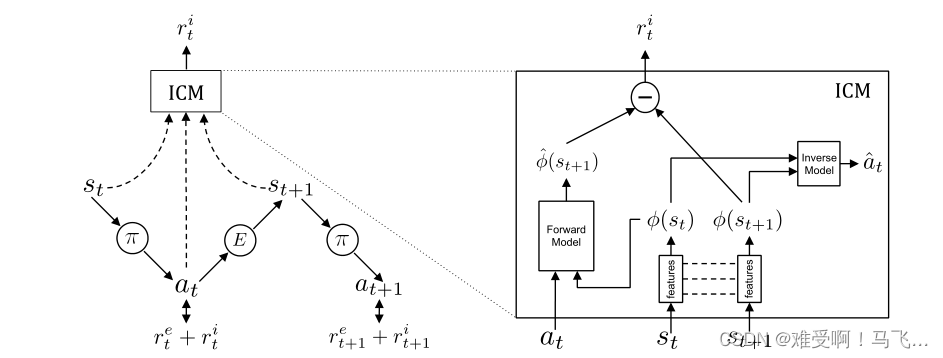
内在好奇心模型(Intrinsic Curiosity Module,ICM)-论文Curiosity-driven Exploration by Self-supervised Prediction
关于强化学习的稀疏奖励问题,主要的解决方案有: 1)塑形奖励函数,但是塑形奖励函数一般或多或少的带有设计者的个人主观因素,这可能会导致模型的最优策略发生偏移。目前,防止塑形奖励函数改变最优策略的方法是吴恩达的 Potential-Based Reward Shaping (没了解的可以搜索一下看看,有很多博客)。2)模仿学习,其实也就是使用专家演示数据引导训练,典型的代表就是DQN中使用的tra

(翻译)求知欲模式(Curiosity)
问题概述 当被一小撮有趣的信息吸引时,我们更渴望得到更多信息[1]。 示例 说明 公开足够多的信息,勾起用户的兴趣,吸引用户采取行动去获得更多的内容。用户想填补信息缺口,而你的工作是尽可能地拖延用户完成该行为,且不能带给用户太多不适。让用户将填补信息缺口的行为一直坚持下去。 原文地址:http://ui-patterns.com/patterns/curiosity [1]原
杭电1017 A Mathematical Curiosity
/******************************** * 日期:2011-2-9 * 作者:SJF * 题号:杭电1017 * 题目:A Mathematical Curiosity * 结果:AC ********************************/ #include<stdio.h> int ma
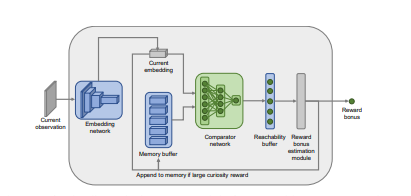
Episodic Curiosity through Reachability阅读笔记
在现实世界中,奖励很稀疏,而今天大多数的强化学习算法都在与这种稀疏性斗争。这个问题的一个解决方案是让智能体自己创造奖励,从而使奖励更加密集,更加适合学习。很多现实世界的任务都有稀疏的奖励,例如:寻找食物的动物可能需要走很多英里而没有来自环境的任何奖励。标准强化学习算法因为依赖简单的行动熵最大化作为探索行为的来源,所以在这些任务中表现挣扎。 很多现在的好奇心机制以意外最大化为目标,这种方法理论上很