本文主要是介绍科研上新 | 第2期:可驱动3D肖像生成;阅读文本密集图像的大模型;文本控制音色;基于大模型的推荐智能体,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
本期内容速览
01. AniPortraitGAN:可驱动的真实感3D肖像生成
02. KOSMOS-2.5:阅读文本密集图像的多模态大型语言模型
03. PromptTTS 2:利用文本描述创造语音合成的音色和风格
04. InteRecAgent:基于大型语言模型的交互式推荐智能体
arXiv精选
AniPortraitGAN:可驱动的真实感3D肖像生成

论文链接:https://arxiv.org/pdf/2309.02186.pdf
项目链接:https://yuewuhkust.github.io/AniPortraitGAN/
自动创建可驱动的 3D 人物角色已经成为一个越来越重要的话题,其应用范围涵盖视频会议、电影制作和游戏等等。近年来,一些方法基于对抗网络进行了真实感三维人像的生成与驱动,但这些方法主要关注头部或全身生成。然而,仅生成头部类的方法在实际场景中的适用性较低,生成全身类的方法则难以取得较好的面部区域生成质量。为此,研究员们提出了一种专注于人类头部和肩部的真实感 3D 肖像生成方法。该方法利用多人 2D 图像集进行无监督对抗学习训练,无需三维数据、多视角图片或者视频。生成的 3D 肖像逼真且可进行相机视角、头部姿态、肩膀姿态、以及面部表情的驱动,更适合于视频会议、虚拟演示等实际应用。
针对这个新任务,研究员们提出了利用 3D 参数模型提供先验神经辐射场的生成方法。该方法基于 3D 感知生成对抗网络框架,以 GRAM 为基础三维表达,分别利用 3D 可形变模型(3DMMs)和 SMPL 人体参数模型为先验,指导人脸表情控制和头部肩部运动学习。为了处理由于头部位置变化和人体朝向变化而造成的复杂图像分布,研究员们提出了基于双相机渲染的对抗学习方案,来提高面部渲染质量。此外,仅简单使用 SMPL 线性混合蒙皮策略指导头部形变学习,在头部旋转时,头发区域会出现锐利的不连续性,导致明显的伪影。针对这一问题,研究员们进一步提出了姿态变形处理模块来学习更合理的形变场,稳定生成对抗训练,从而产生视觉上合理的结果。

图1:AniPortraitGAN 3D 肖像生成结果
实验结果表明,AniPortraitGAN 可以生成具有灵活控制的多样化和高质量 3D 肖像图像,可以实现对面部表情和头肩姿势等不同属性的细粒度控制。研究员们相信在该项研究向着自动创建适用于实际应用的视频化身,迈出了坚实一步。
KOSMOS-2.5:阅读文本密集图像的多模态大型语言模型

论文链接:https://arxiv.org/abs/2309.11419
现有的大型语言模型(LLMs)主要集中在文本信息上,无法理解视觉信息。而多模态大型语言模型(MLLMs)领域的进展旨在解决这一限制,MLLMs 可以将视觉和文本信息融合到一个基于 Transformer 的单一模型中,使该模型能够根据这两种模态学习和生成内容。不过,现有的 MLLMs 主要关注分辨率较低的自然图像,对于文本密集图像的 MLLM 研究还不多见,因此充分利用大规模多模态预训练来处理文本图像是 MLLM 研究的一个重要的研究方向。本篇论文介绍了将文本图像纳入训练过程并开发基于文本和视觉信息的模型 KOSMOS-2.5,开辟了涉及高分辨率文本密集图像的多模态应用的新可能性。
KOSMOS-2.5 是微软亚洲研究院的研究员们开发的一个基于文本密集图像的多模态大型语言模型,它在 KOSMOS-2 的基础上发展而来,突出了对于文本密集图像的多模态阅读和理解能力(Multimodal Literate Model)。KOSMOS-2.5 的目标是在文本丰富的图像中实现无缝的视觉和文本数据处理,以便理解图像内容并生成结构化的文本描述。
作为一个多模态模型,KOSMOS-2.5 使用了统一的框架处理两个紧密相关的任务。第一个任务涉及生成具有空间感知的文本块,即同时生成文本块的内容与坐标框。第二个任务涉及以Markdown格式生成结构化的文本输出,同时捕捉各种样式和结构。两个任务利用共享的Transformer架构与任务特定的提示。KOSMOS-2.5 将基于 ViT(Vision Transformer)的视觉编码器与基于 Transformer 架构的解码器相结合,通过一个重采样模块连接起来。
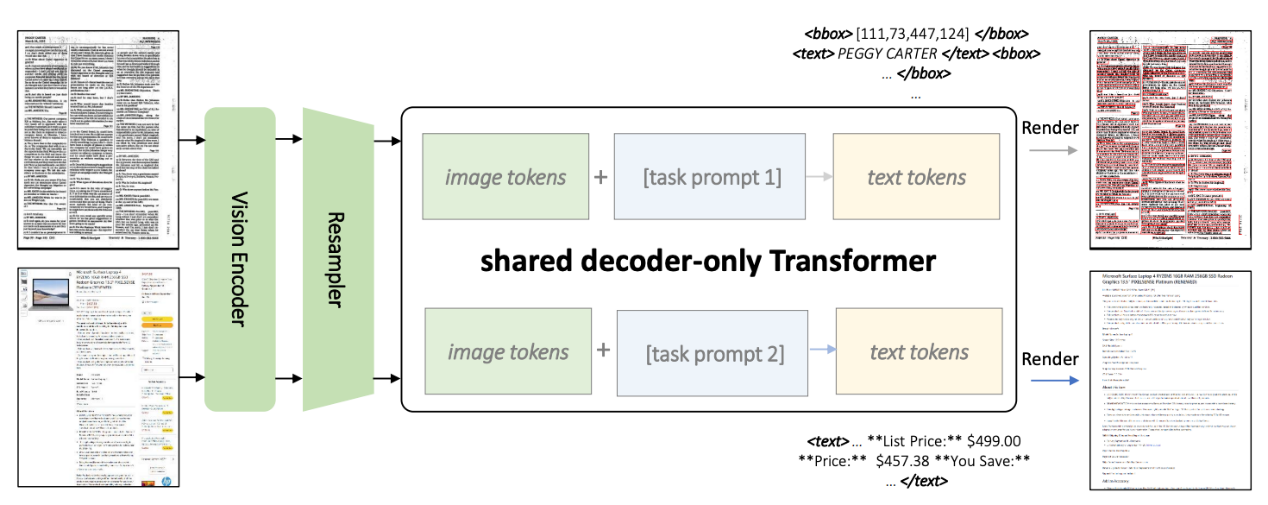
图2:KOSMOS-2.5 架构图
为了训练这个模型,研究员们准备了一个庞大的共3.2亿的数据集进行预训练。该数据集包含各种类型的文本密集图像,其中包括带有边界框的文本行和纯文本的 Markdown 格式。
KOSMOS-2.5 在两个任务上进行了评估:端到端的文档级文本识别和从图像中生成的 Markdown 格式文本。实验结果展示了 KOSMOS-2.5 在理解文本密集的图像任务方面的出色表现。此外,KOSMOS-2.5 在少样本学习和零样本学习的场景中也展现了有前景的能力,使其成为处理文本丰富图像的实际应用的多功能工具。研究员们希望该研究最终可以开发出一种能有效解释视觉和文本数据的模型,并在更多文本密集型多模态任务中进行推广。
PromptTTS 2:利用文本描述创造语音合成的音色和风格

论文链接:https://arxiv.org/abs/2309.02285
Demo链接:https://speechresearch.github.io/prompttts2
语音合成系统近年来在可识别度和自然度方面都取得了巨大进展,除了语音合成的内容,还能通过模仿参考语音的风格和音色,生成与其风格一致的语音。然而,获得合适的参考语音并不容易,因此使用文本描述(Text Prompt)来控制音色是一种更加便捷的方法,可用于语音助手、虚拟主持和有声书籍等领域。
基于文本描述控制语音合成的音色和风格目前主要面临两个挑战:第一个挑战是一对多的问题,因为描述文本无法涵盖所有语音细节,这就导致训练集中对应同一个文本描述的语音可能在音色和风格上有差异,会影响模型训练;第二个挑战是数据量,对语音的音色和风格描述的数据非常稀少,需要大量人工编写文本描述,增加成本。
为了解决这些问题,微软亚洲研究院的研究员们提出了 PromptTTS 2。它包含一个变异网络(variation network)来预测文本描述中缺失的细节变化性信息,从而支持生成多个符合文本描述但在音色和风格上不同的声音。为了解决数据量问题,PromptTTS 2 还包括自动文本描述生成工具,通过语音理解模型和大型语言模型(LLMs)自动产生文本描述,提高语音合成质量。
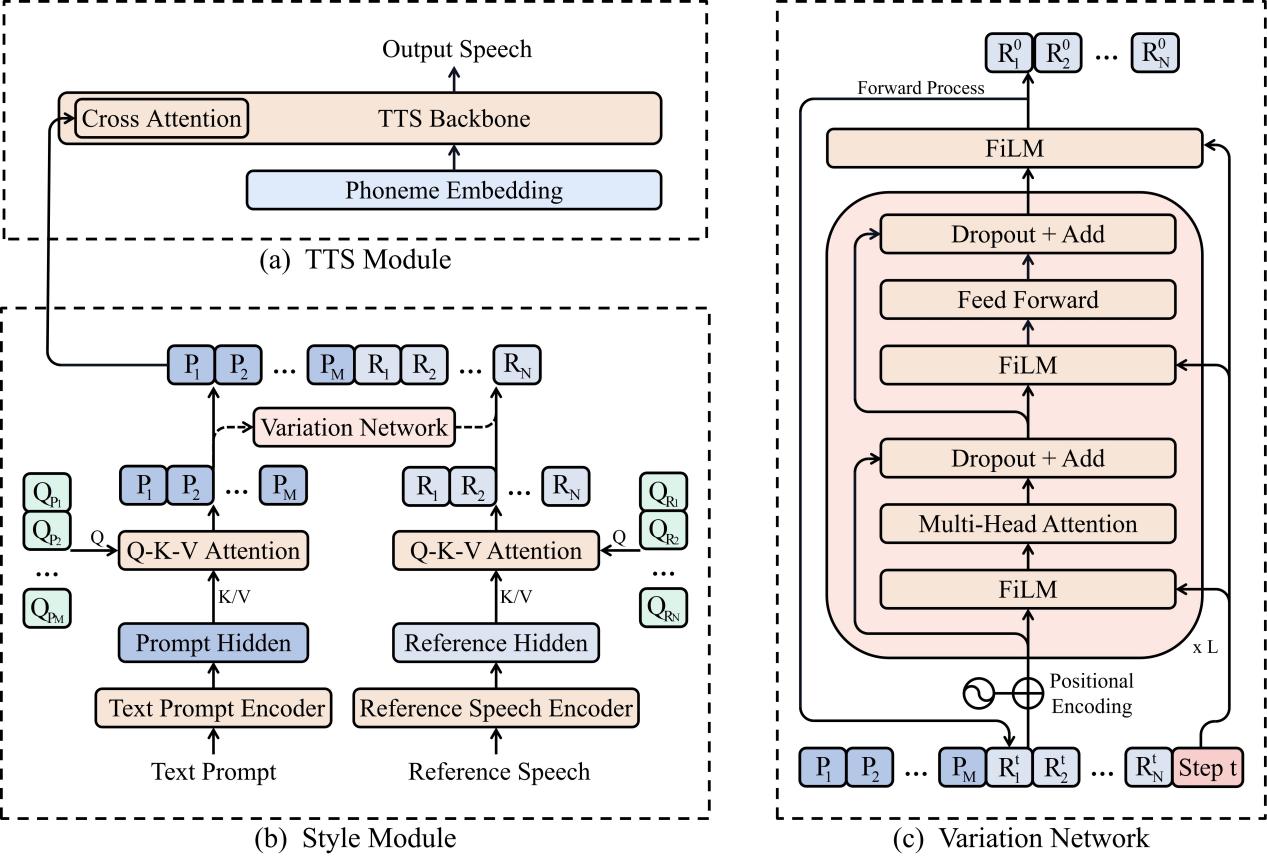
图3:PromptTTS 2 中的 TTS 系统
图3展示了 PromptTTS 2 中的 TTS 系统。图3(a)是一个用于合成语音的 TTS 模块,合成结果的风格和音色由一个风格模块(style module)控制。图3(b)详细介绍了风格模块的结构。它包含两个编码器,可以从文本描述和参考语音中提取控制特征。虽然在训练的时候研究员们使用参考语音补充了文本描述中不存在的细节信息,解决了一对多问题,但是在测试时,参考语音是不存在的。因此研究员们训练了一个变异网络来根据文本描述特征预测细节的变化性特征,如图3(c)所示。通过利用扩散模型,变异网络可以采样出多个不同的细节特征,从而产生出更有变化性的声音供用户使用。
除了语音合成系统,PromptTTS 2 还包括一个自动化的文本描述生成工具,整个工具由语音理解模型(SLU)部分和大型语言模型(LLM)部分组成:SLU 部分通过识别语音中的属性(例如性别、情感等)来给语音打标签;而 LLM 部分则根据这些标签引导 LLM 编写高质量的文本描述。
验证实验表明,相比于基线系统,PromptTTS 2 可以在所有属性上以更高的准确度合成语音;自动化的文本描述生成工具可以生成质量略高于人工撰写的文本表述。在未来,PromptTTS 2 将会被扩展到更多的维度和模态,从而合成更加有创造力的声音和实现多模态(语音、文本描述、面部图像等)对声音的控制。
InteRecAgent:基于大型语言模型的交互式推荐智能体

论文链接:https://arxiv.org/pdf/2308.16505.pdf
项目链接:https://aka.ms/recagent
大型语言模型已经表现出了强大的语言表达能力,人类指令遵循能力,以及推理和解释的能力。相关的技术很可能使得推荐系统从传统的用户被动接收推荐信息,转变到可对话、可控制的智能交互方式。但是已有研究表明直接应用大型语言模型做交互式推荐存在许多弊端,例如缺乏新加入的知识;无法知晓领域内的物品条目;存在一定的幻觉,即推荐给用户不存在的物品等。
为了解决这些问题,研究员们提出了一种基于“大型语言模型+工具”方案的交互式推荐智能体:InteRecAgent。其由两部分构成,即作为大脑的大型语言模型和作为工具的推荐模型。大型语言模型负责解析用户意图并产生工具调用方案,以及根据工具执行结果生成回答。推荐工具则由查询、召回、排序三大类工具构成,负责执行用户的各类查询和产生需要的推荐。
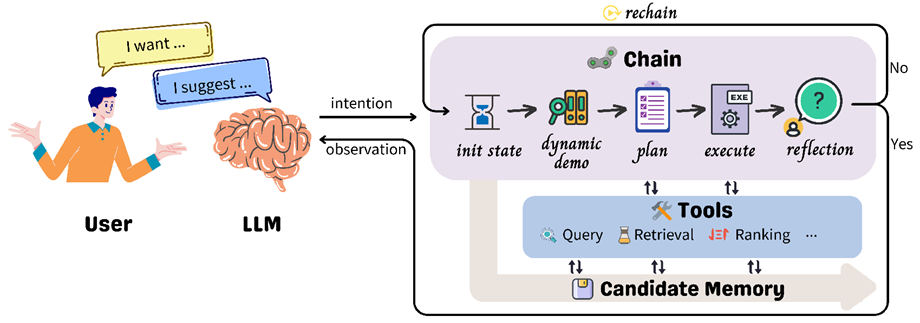
图4:InteRecAgent 整体框架示意图
InteRecAgent 从离线样本库中动态选择样本作为示例,构成提示词中语境学习的部分。大模型会根据当前用户的意图,拟出完整的推荐工具调用方案,然后各个工具依次执行对应的任务。在执行完成后,为了保障推荐的质量,InteRecAgent 使用了反思机制,一旦检测到执行过程中出现问题,就将重新制定计划并执行。最终推荐工具得到的物品将被大型语言模型生成回复推荐给用户。
实验结果表明,在多个数据集上 InteRecAgent 的推荐准确度相比于现有的大型语言模型都有所提升;并且由于推荐结果均来自于领域内的条目,所以不会推荐出不存在的物品,改善了大型语言模型在推荐任务上的幻觉现象。InteRecAgent 只是微软亚洲研究院社会计算组关于如何将大型语言模型引入推荐系统研究工作中的一部分,未来研究员们还将继续在这方面进行深入的探索。
随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”六个负责任的人工智能原则(Responsible AI Principles),随后又发布了负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。微软也持续与全球的研究人员和学术机构合作,不断推进负责任的人工智能的实践和技术。
这篇关于科研上新 | 第2期:可驱动3D肖像生成;阅读文本密集图像的大模型;文本控制音色;基于大模型的推荐智能体的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








