音色专题

强大的EmotiVoice:易魔声 : 多音色提示控制TTS
EmotiVoice是一个强大的开源TTS引擎,完全免费,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。 EmotiVoice提供一个易于使用的web界面,还有用于批量生成结果的脚本接口。 gitee镜像:https://gitee.com/mirrors/EmotiVoice MAC下有一键安装包 可以用doc
GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)
语音克隆项目GPT-Sovits发布了V2版本,在早些时候做了V1版本的整合包,但是那个版本的整合包操作比较麻烦,上手难度高。正好趁着V2,一起更新了。 【GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)】 https://www.bilibili.com/video/BV12MW2e4Ebx/?share_source=copy_web&v

未来感十足的AI驱动网络爬虫工具;自然语音生成与音色模拟ChatTTS-OpenVoice;基于人工智能的问答引擎Sensei
✨ 1: CyberScraper 2077 CyberScraper 2077是一款未来感十足的AI驱动网络爬虫工具,能高效提取网页数据。 CyberScraper 2077 是一款先进的网页数据提取工具,融合了人工智能技术,旨在以无与伦比的精准度和风格提取网络数据。这款工具的设计灵感来源于赛博朋克世界,具有未来感,是为了满足数据分析师、网络“跑者”及需要提取信息用户的需求。它不仅是

ChatTTS增强版V3【已开源】,长文本修复,中英混读,导入音色,批量SRT、TXT
ChatTTS增强版V3来啦!本次更新增加支持导入SRT、导入音色等功能。结合上次大家反馈的问题,修复了长文本、中英混读等问题。 项目已开源(https://github.com/CCmahua/ChatTTS-Enhanced) 项目介绍 V3 ChatTTS增强版V3,长文本修复,中英混读,导入音色,批量SRT、TXT,代码开源_哔哩哔哩_bilibili V2 ChatTTS

一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音,音色、语速、停顿,口语,全搞定
前几天和大家分享了如何从0到1搭建一套语音交互系统。 其中,语音合成(TTS)是提升用户体验的关键所在。于是,上一篇接着和大家聊了聊:全网爆火的AI语音合成工具-ChatTTS,有人已经拿它赚到了第一桶金,送增强版整合包。 后台有小伙伴反应实测中发现了一些常见的问题,今天,单独开一篇关于ChatTTS的进阶教程,手把手带你实现如何固定音色、设置语速、添加停顿词、口头语、笑声等,以及超长文本生成

ChatTTS改良版 - 新增精选高品质音色,新增超长文本推理,新增api接口
这个版本是ChatTTS的一个分支,基于ChatTTS修改,由6drf21e大佬改良,大佬GitHub地址 GitHub - 6drf21e/ChatTTS_colab: 🚀 一键部署(含离线整合包)!基于 ChatTTS ,支持音色抽卡、长音频生成和分角色朗读。简单易用,无需复杂安装。 民间玩家QuantumDriver 多次把玩,从抽卡音色中精选了几种高质量的音色,类似其他TTS项目的命
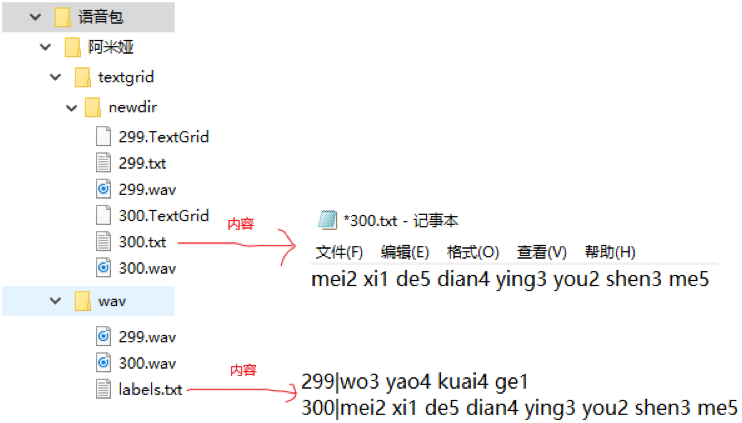
PaddleSpeech MFA:阿米娅中文音色复刻计划
PaddleSpeech:阿米娅中文音色复刻计划 本篇项目是对iterhui大佬项目[PaddleSpeech 原神] 音色克隆之胡桃的复刻,使用的PaddleSpeech的版本较新,也针对新版本的PaddleSpeech做了许多配置之上的更新并加入了自己对语音的对齐、配置、训练其它任何语音音色的模块。 本篇项目旨在利用PaddleSpeech框架实现音色克隆技术,目标是复制并生成游戏《明

康泰克采样器Kontakt 5、6 For MAC 入库管理工具和非标准音色入库文件合集
Kontakt For MAC入库管理修改工具文件大全,基本包含了Kontakt MAC版本的入库所需。 包含以下文件: 1 – Native_Access_Installer.dmg > 官方音色管理程序,Kontakt 6版本入库消失时需要安装打开这个程序入库才会正常显示 2 – 可修改的Nicnt入库文件 > 适合Add Library显示 No library的一些非标准音色库文件,直

立体环绕音色带来的震撼 这两款时尚蓝牙音箱很别致
一年一度,万众期待的双11大促季已经火热来袭,如今只要我们打开各大电商网站或者APP,就瞬间呈现各种铺天盖地的促销活动信息。这个时候,能够锁定真正超值好用而兼具个性化的爆款产品,就显得非常重要。一直专注于多媒体音箱产品打造的索爱,在双11促销季主打SA-C2、SH16两款颇具特色的音箱产品。美妙音色3D环绕,全能蓝牙颜值担当,再配上双11前所未有的新低价,SA-C2及SH16多媒体电脑音箱超值好玩

美妙音色与美好生活同时实现 这款加湿器蓝牙音箱好特别
当生活跨入了智能时代,我们周边很多装备,都进入了“跨界”多功能融合的时代,一款产品兼备多种功能,无疑能让用户收获更惬意的生活感受。来自索爱的S-66加湿器蓝牙音箱,就是一款非常实用的“跨界”音箱产品,它能让用户畅享音乐的同时,也能体验到生活备受“滋润”的乐趣。 索爱S-66,音箱与加湿器完美融合的时尚好物 索爱的S-66拥有完备的播放功能,它支持蓝牙4.2传输技术,直线连接距离达到10米,

音色出众外形别致 新年礼物该选这样的家用蓝牙音响
随着人们对生活品质的要求越来越高,居家休闲的时候总渴望有一些贴心的装备相伴,特别是新年将至,更应该给自己送上一份礼物,期望来年收获更多欢欣和惬意。添置一个音质出色、造型设计出众的家用音响,想必是不少人热衷的选择,小编今天就给大家推荐一款来自索爱的A2家用桌面音响,品质优秀而且性价比足够出色,多种个性化的配置可供消费者灵活选择,接下来我们就来详细了解一下。 当下很多普通的家用桌面音响,因为设计

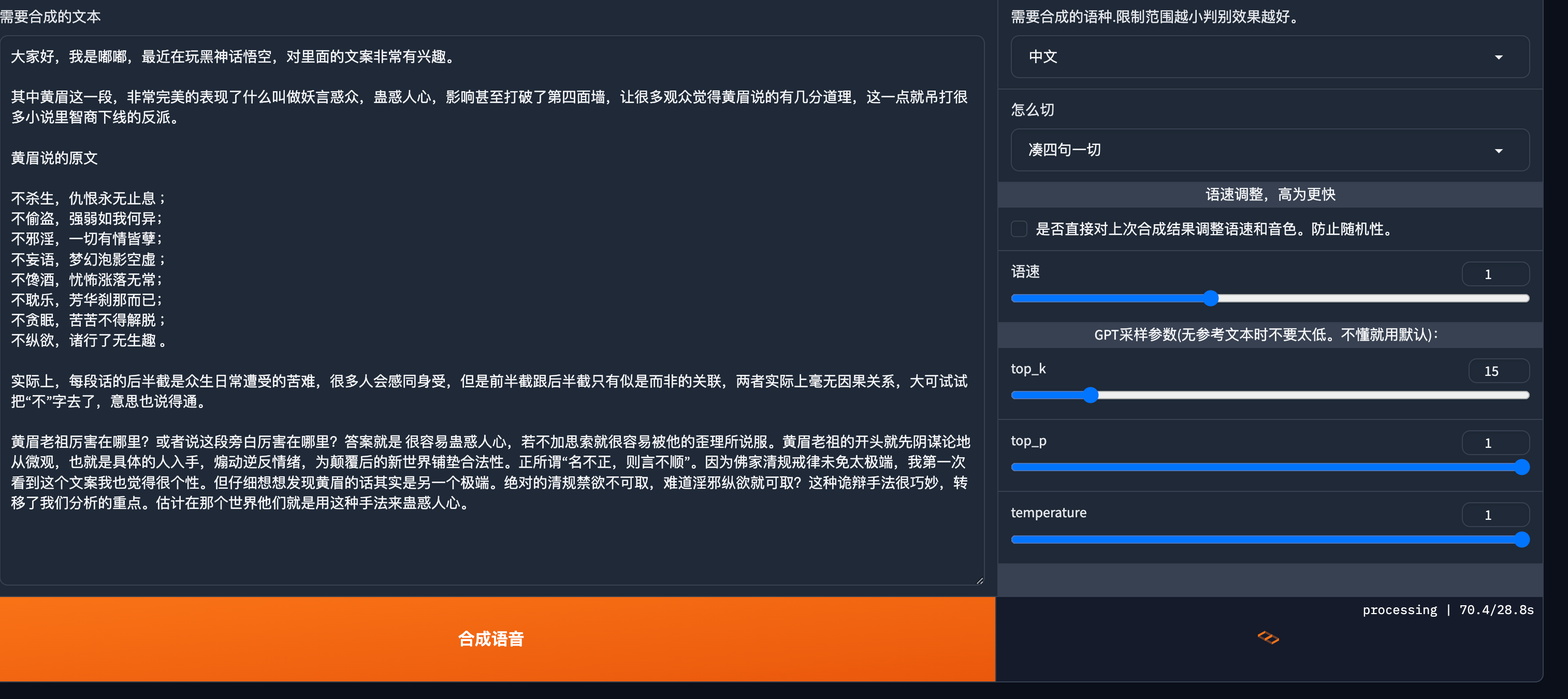
GPT-SoVITS音色克隆-模型训练步骤
GPT-SoVITS音色克隆-模型训练步骤 GPT-SoVITS模型源码一个简单的TTS后端项目 基于模型部署和训练教程,语雀 模型部署和训练教程 启动模型训练的主页面 1. 切到模型路径 /psycheEpic/GPT-SoVITS 进入Python虚拟环境,并挂起执行python脚本 conda activate GPTSoVitsnohup python ./webui.py
GPT-SoVits:刚上线就获得了5.1k star的开源声音克隆项目!效果炸裂的跨语言音色克隆模型!
上周,RVC变声器创始人 (GitHub昵称:RVC-Boss) 开源了一款跨语言音色克隆项目 GPT-SoVITS。项目一上线就引来了互联网大佬和博主的好评推荐,不到两天时间就已经在GitHub上获得了1.4k Star量,不过现在已经飙升到了5.1k。 据说,该项目是RVC-Boss 同Rcell (AI音色转换技术Sovits开发者)共同研究,历时半年,期间遇到了很多难题而开发出来的一款全
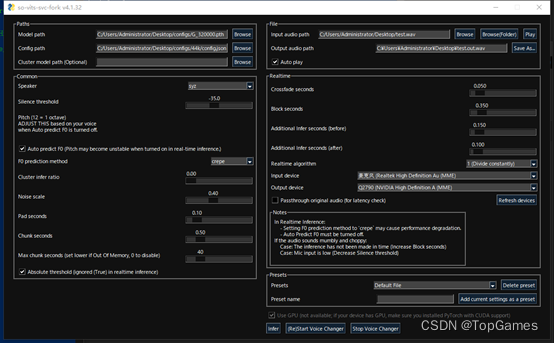
【AI】文本转语音 变声 音色克隆 数字人音视频口型同步AI应用
文本转语音 项目地址:https://github.com/coqui-ai/TTS 环境安装: 下载项目;安装Python,安装项目依赖: pip install TTS 1. 下载安装AI模型: https://github.com/facebookresearch/fairseq/tree/main/examples/mms 模型文件放到:C:\Users\Administra
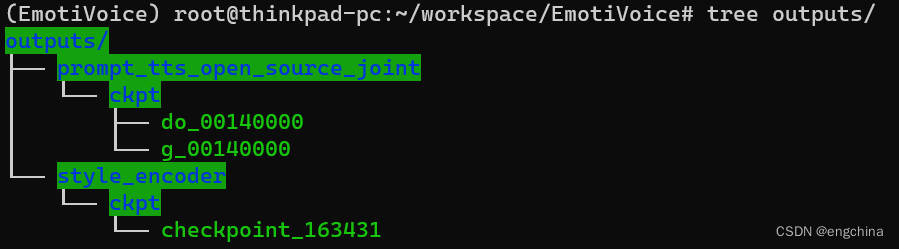
本地部署 EmotiVoice易魔声 多音色提示控制TTS
本地部署 EmotiVoice易魔声 多音色提示控制TTS EmotiVoice易魔声 介绍ChatGLM3 Github 地址部署 EmotiVoice准备模型文件准备预训练模型推理 EmotiVoice易魔声 介绍 EmotiVoice是一个强大的开源TTS引擎,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的

南卡小音舱,全新升级5.3,拥有天籁音色
对于南卡这个品牌可能大家也是比较熟悉的了,南卡也一直为广大用户提供平价且性价比的蓝牙耳机。最近,笔者也入手了一款南卡小音舱,是南卡刚上市不久的蓝牙耳机产品,搭载了全新的蓝牙5.3芯片,带来45ms更低延迟的游戏表现。那么,它的实际表现如何呢?下面,就跟随文章一起往下看吧! 短柄半入耳设计,佩戴舒适无感 南卡小音舱整体外观设计精致小巧,外观设计灵感来远远宇宙太空船睡眠舱,使用时扭开旁边即

梨花声音研修院,严肃与刚毅是音色核心
在为军旅剧提供配音服务时,配音员需捕捉并展现军事场合的严肃气氛、军人的刚毅品质以及他们对职责的忠诚。军旅剧往往围绕着军人的日常生活、战场经历、战友之情以及对祖国的热爱等主题展开,所以配音需能传递这些情感和价值。以下是进行军旅剧配音的一些具体建议: 体现军人的坚毅与决断 运用坚实、有力的声音,体现军人的勇敢和坚定不移。 彰显部队的纪律性 在配音表现中注入军队特有的纪律感,如命令的准确
本地部署 EmotiVoice易魔声 多音色提示控制TTS
本地部署 EmotiVoice易魔声 多音色提示控制TTS EmotiVoice易魔声 介绍ChatGLM3 Github 地址部署 EmotiVoice准备模型文件准备预训练模型推理 EmotiVoice易魔声 介绍 EmotiVoice是一个强大的开源TTS引擎,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的


栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全可以接受。 BERT的核心思想是通过在大规模文本语料上进行无监督预训练,学习到通用的语言表示,然后将这些表示用于下游任务的微调。相比传统的基于词嵌入的模型,BERT引
栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全可以接受。 BERT的核心思想是通过在大规模文本语料上进行无监督预训练,学习到通用的语言表示,然后将这些表示用于下游任务的微调。相比传统的基于词嵌入的模型,BERT引
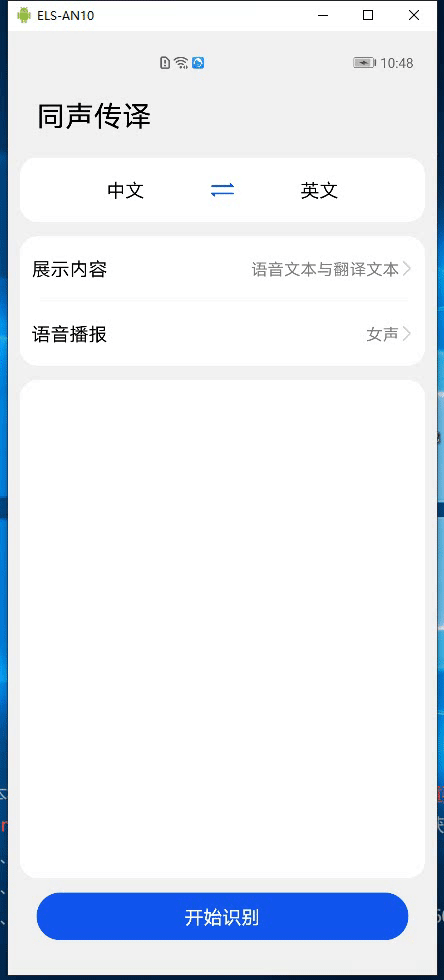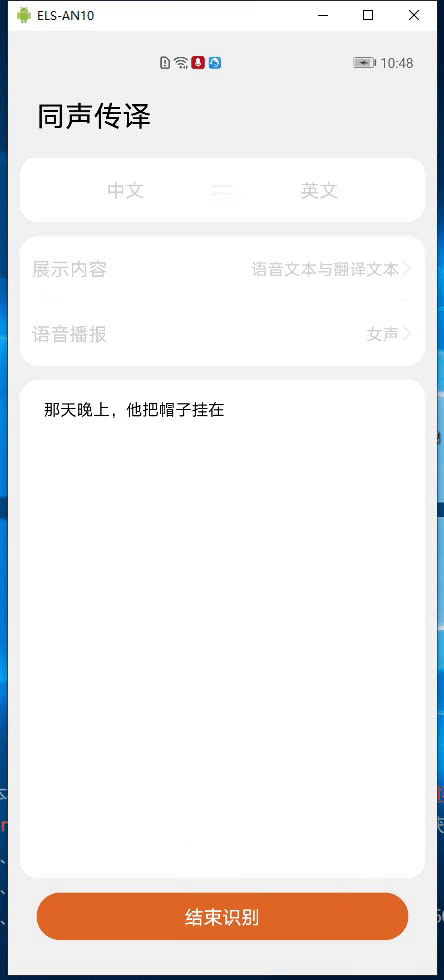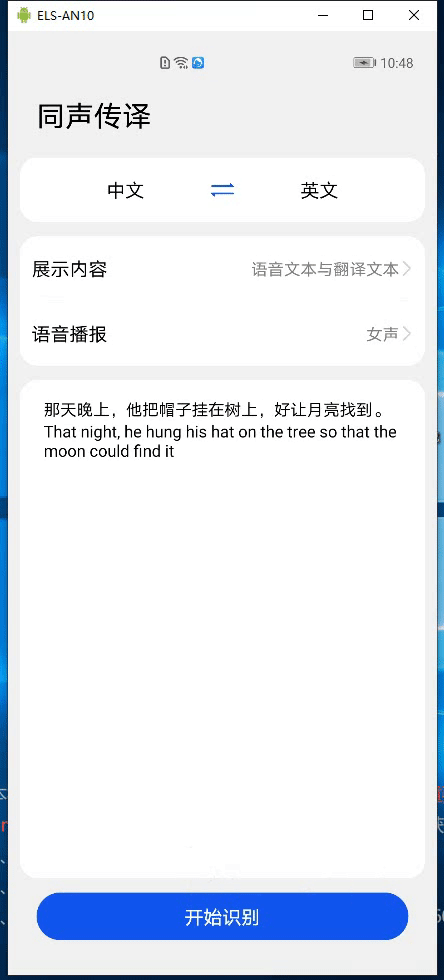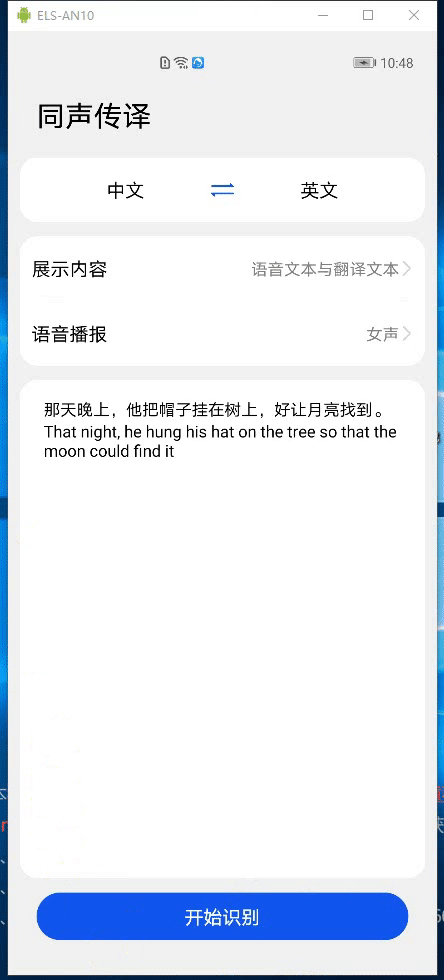
HMS Core机器学习服务实现同声传译,支持中英文互译和多种音色语音播报
当用户有跨语种交流或音频内容翻译的需求时,应用需要能自动检测语音内容再输出为用户需要的语言文字。 HMS Core机器学习服务提供同声传译能力,同声传译实现将实时输入的长语音实时翻译为不同语种的文本以及语音,并实时输出原语音文本、翻译后的文本以及翻译文本的语音播报。 在直播类,会议类的应用中,同声传译显得尤为重要。比如,在会议类应用中,可以将正在进行的会议发言人的发言内容实时输出为目标语言文字
科研上新 | 第2期:可驱动3D肖像生成;阅读文本密集图像的大模型;文本控制音色;基于大模型的推荐智能体
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。 本期内容速览 01. AniPortraitGAN:可驱动的真实感3D肖像生成 02. KOSMOS-2.5:阅读文本密集图像的多模态大型语言模型 03. PromptTTS 2:利用文本描述创造语音