本文主要是介绍ChatTTS增强版V3【已开源】,长文本修复,中英混读,导入音色,批量SRT、TXT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatTTS增强版V3来啦!本次更新增加支持导入SRT、导入音色等功能。结合上次大家反馈的问题,修复了长文本、中英混读等问题。
项目已开源(https://github.com/CCmahua/ChatTTS-Enhanced)
项目介绍
V3
ChatTTS增强版V3,长文本修复,中英混读,导入音色,批量SRT、TXT,代码开源_哔哩哔哩_bilibili
V2
ChatTTS增强版V2,批量导出srt,语速控制,情感控制,支持朗读数字,问题修复_哔哩哔哩_bilibili
V1
ChatTTS增强版整合包,增强音质、批量处理、固定音色、支持长文本(WIN、MAC)_哔哩哔哩_bilibili
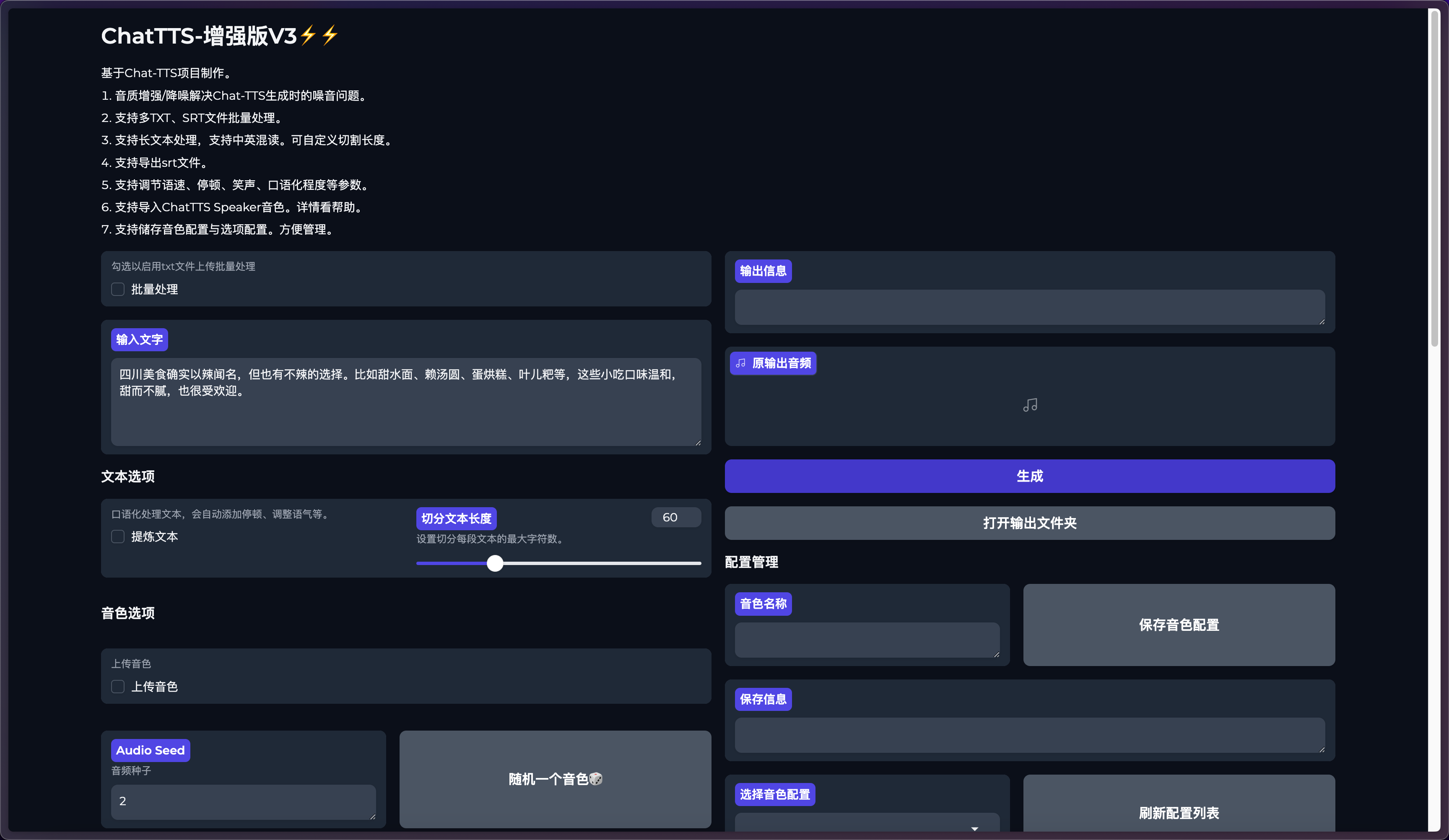
更新内容
批量SRT、TXT
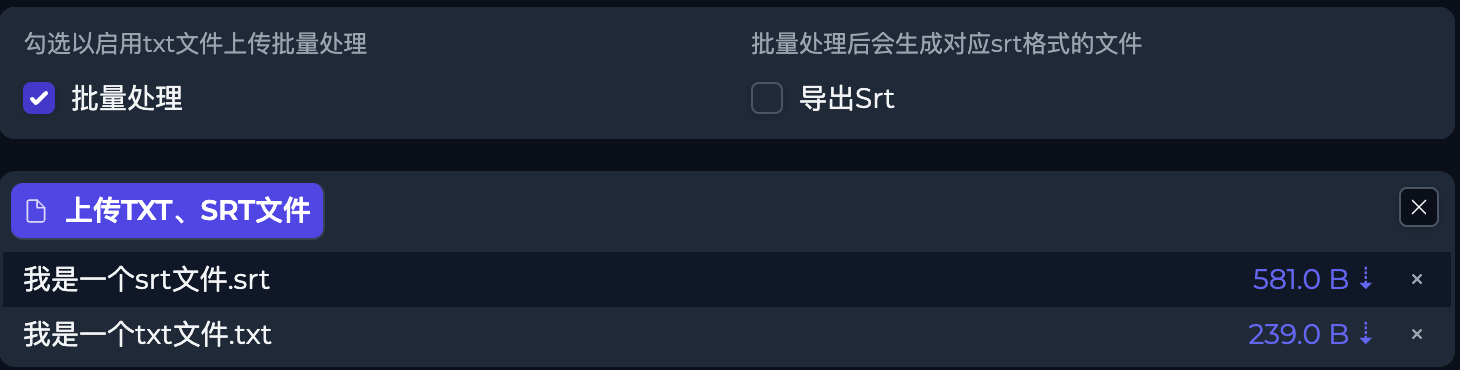
批量功能新增支持多个TXT文本或SRT批量导入,会针对每文件进行处理。并支持导出对应SRT。
TXT文本内容格式不用严格按照换行的来。
你可以按照之前换行的格式来。
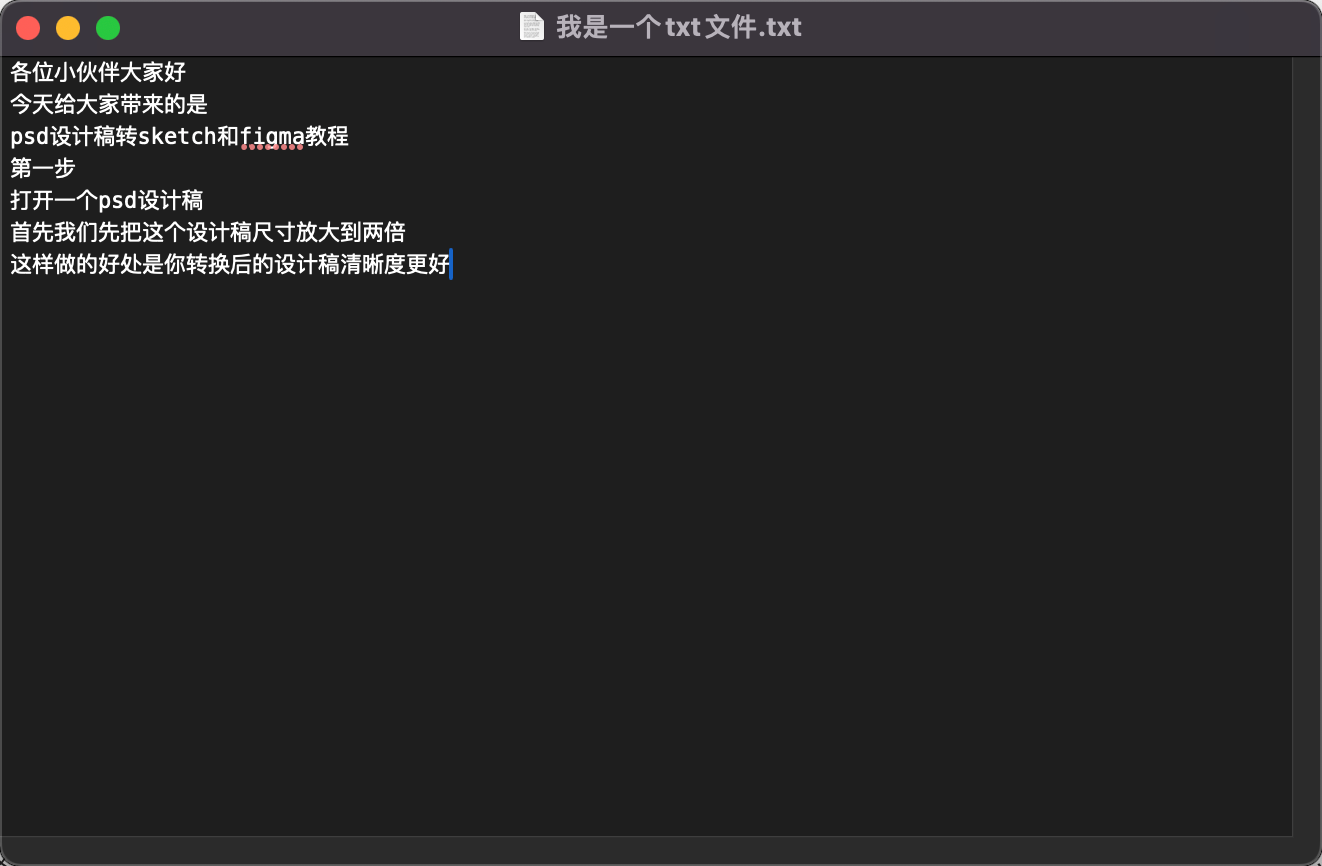
也可以直接所有内容文本粘进去,会自动根据标点符号进行切分。

长文本

不少朋友反馈上个版本长文本的问题很多,这个版本进行调整。文本内容会自动按照标点符号进行断句。
(音频效果)

英文效果
(音频效果)
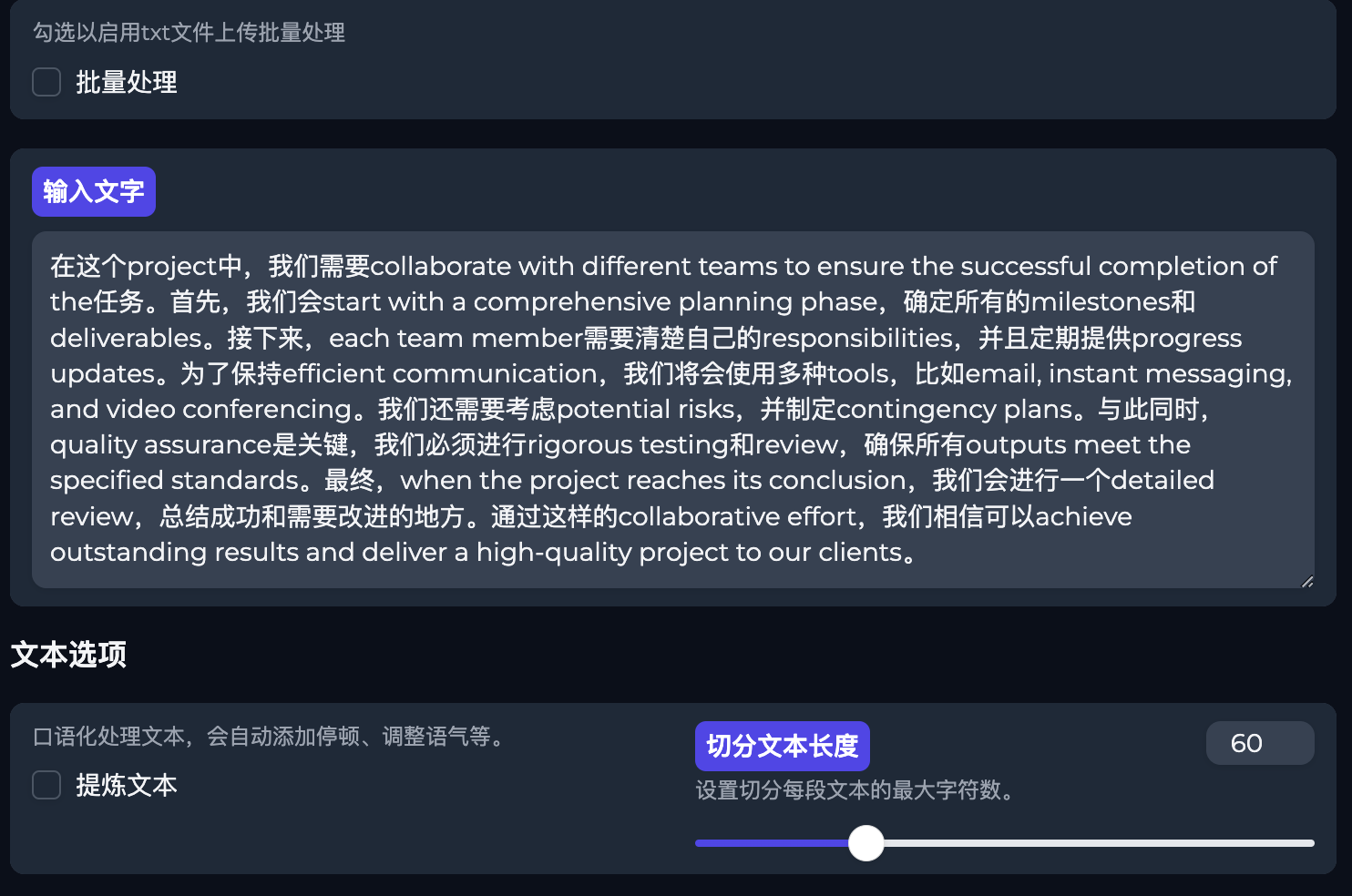
中英混读
(效果)
文本选项
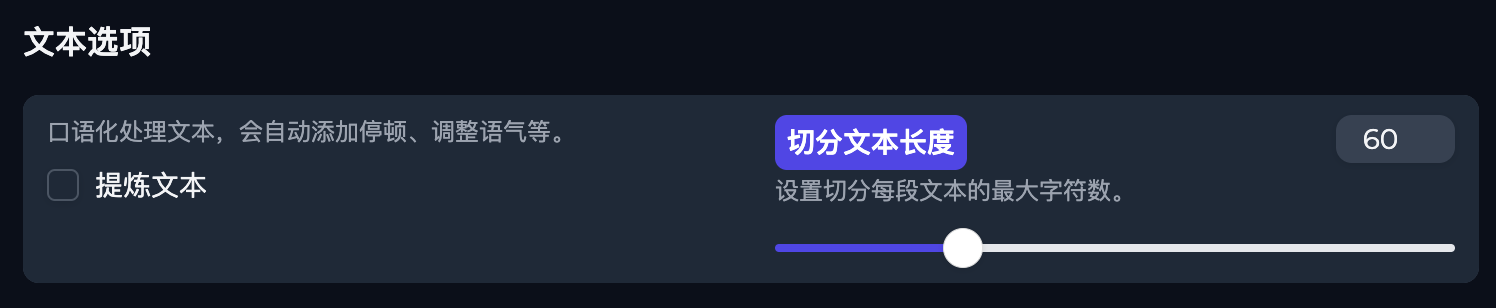
删除了之前数字转换选项、合成整个音频的选项。
数字转换已经内置进去,无需手动勾选。合成整个音频默认自动合成。
导出的完整的音频路径为:output_audio/你的txt名/合并/
导出的音频切片路径为:output_audio/你的txt名/切片/
导出的增强音频切片路径为:output_audio/你的txt名/增强切片/
音色选项
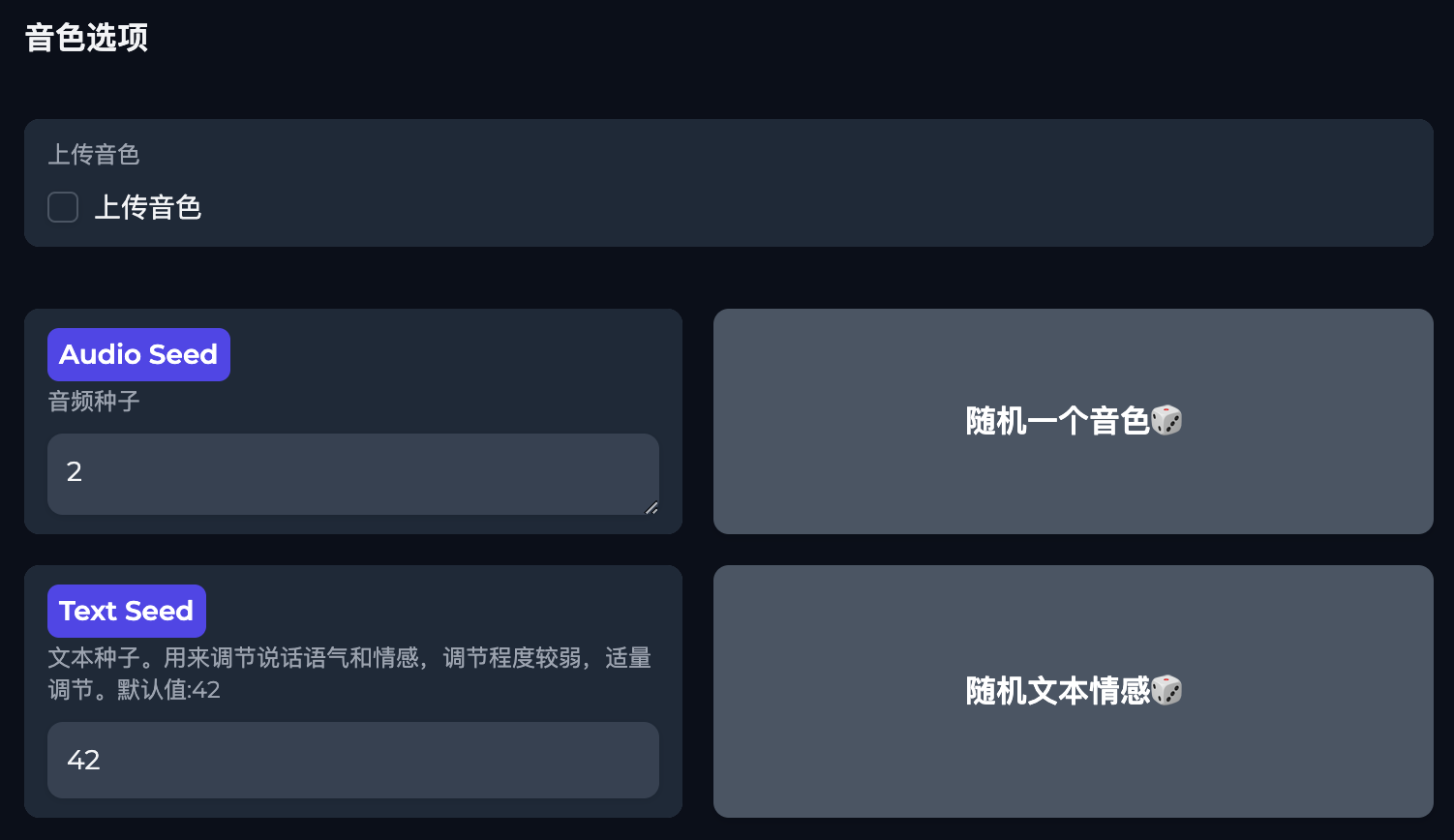
新增上传音色功能。
支持导入ChatTTS_Speaker项目的.pt音色文件。
项目地址:
https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker
在该项目上试听音色,下载.pt文件

音色这里把.pt文件上传。

点击生成即可。

配置管理
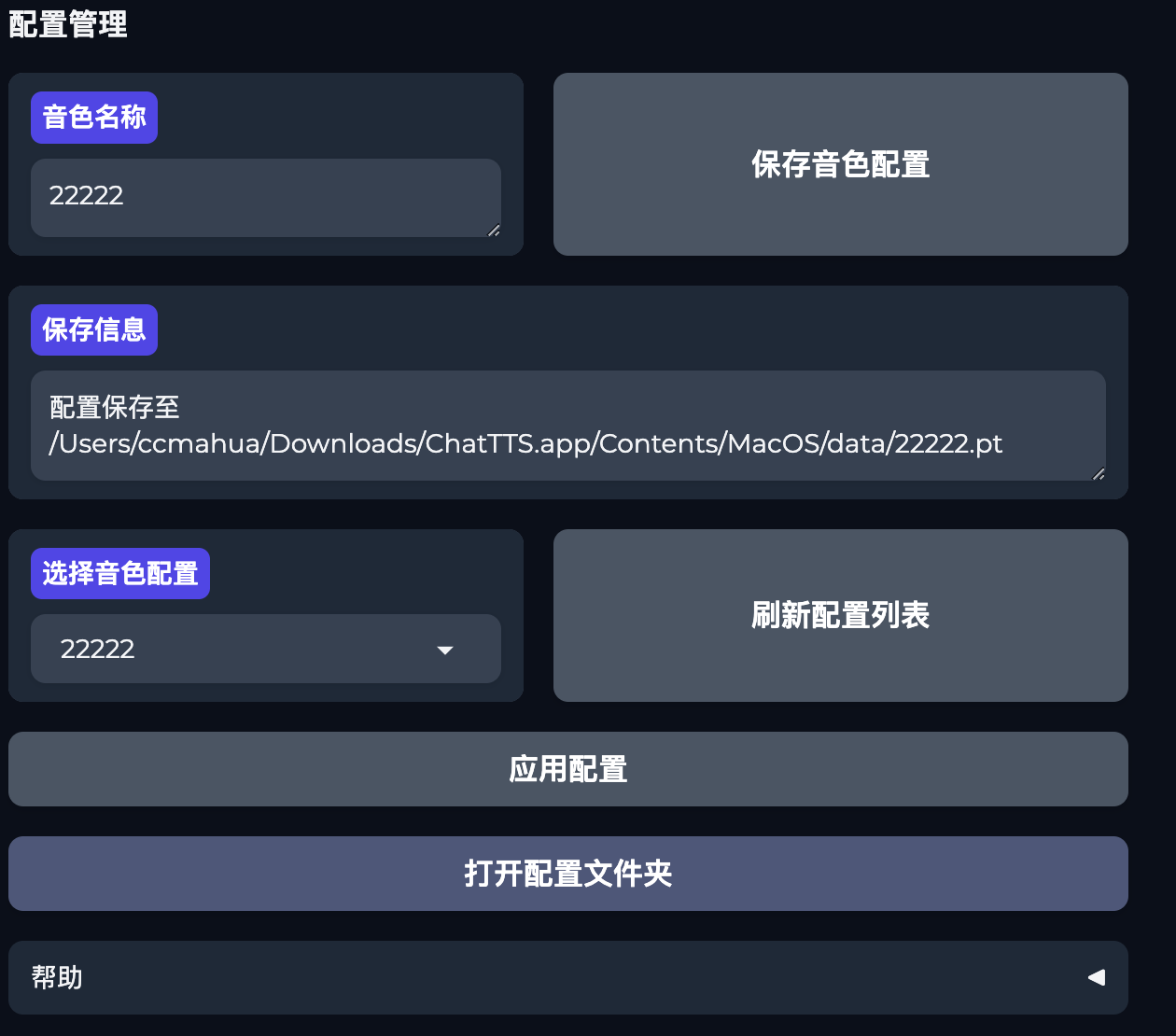
之前的配置文件格式是.json。这个版本统一保存为.pt格式。
📢注意
当你使用ChatTTS_Speaker的音色pt文件时,也可以保存配置文件。
下次使用时,只需要选择配置文件即可,无需再上传音色。配置文件包含音色文件信息。
配置要求
以下是整合包运行所需配置
WIN
- Windwos10/11操作系统
- 支持CPU/GPU
MAC
- Apple Silicon M系列芯片、Intel 芯片
- MacOS 10.13以上版本
云端版本
适用于机器配置低的朋友,云端镜像一键部署。
https://www.xiangongyun.com/image/detail/f086c8d6-a802-4a94-b3b5-f4e2f0e2d631?r=2UKFZQ
云端部署教程
关于显存,最低4G显存(不开启音频增强的情况下)
关于MAC显卡:官方更新了MPS相关代码,但我测下来还有些问题,后面再增加支持,所以现在还是先用CPU。
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【ChatTTSV3】关键字获取整合包。

如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
写在最后
最近有点忙,拖了2周左右。看到后台有很多朋友的想法和建议,很不错,但是精力有限,实在不能保证把大家的想法都更上去,后面抽时间慢慢更。
把项目代码开源了,希望对大家有帮助,有能力的也可以自行修改。
本项目开源地址:https://github.com/CCmahua/ChatTTS-Enhanced
最后感谢以下项目:
ChatTTS:https://github.com/2noise/ChatTTS
Resemble Enhance:https://github.com/resemble-ai/resemble-enhance
ChatTTS_colab:https://github.com/6drf21e/ChatTTS_colab
PaddleSpeech:https://github.com/PaddlePaddle/PaddleSpeech
ChatTTS_Speaker:https://github.com/6drf21e/ChatTTS_Speaker
WeTextProcessing:https://github.com/wenet-e2e/WeTextProcessing
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!
这篇关于ChatTTS增强版V3【已开源】,长文本修复,中英混读,导入音色,批量SRT、TXT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







