批量专题

利用Python脚本实现批量将图片转换为WebP格式
《利用Python脚本实现批量将图片转换为WebP格式》Python语言的简洁语法和库支持使其成为图像处理的理想选择,本文将介绍如何利用Python实现批量将图片转换为WebP格式的脚本,WebP作为... 目录简介1. python在图像处理中的应用2. WebP格式的原理和优势2.1 WebP格式与传统

Java如何从Redis中批量读取数据
《Java如何从Redis中批量读取数据》:本文主要介绍Java如何从Redis中批量读取数据的情况,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录一.背景概述二.分析与实现三.发现问题与屡次改进3.1.QPS过高而且波动很大3.2.程序中断,抛异常3.3.内存消

MySQL数据库实现批量表分区完整示例
《MySQL数据库实现批量表分区完整示例》通俗地讲表分区是将一大表,根据条件分割成若干个小表,:本文主要介绍MySQL数据库实现批量表分区的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考... 目录一、表分区条件二、常规表和分区表的区别三、表分区的创建四、将既有表转换分区表脚本五、批量转换表为分区
Oracle 通过 ROWID 批量更新表的方法
《Oracle通过ROWID批量更新表的方法》在Oracle数据库中,使用ROWID进行批量更新是一种高效的更新方法,因为它直接定位到物理行位置,避免了通过索引查找的开销,下面给大家介绍Orac... 目录oracle 通过 ROWID 批量更新表ROWID 基本概念性能优化建议性能UoTrFPH优化建议注

SpringBoot整合mybatisPlus实现批量插入并获取ID详解
《SpringBoot整合mybatisPlus实现批量插入并获取ID详解》这篇文章主要为大家详细介绍了SpringBoot如何整合mybatisPlus实现批量插入并获取ID,文中的示例代码讲解详细... 目录【1】saveBATch(一万条数据总耗时:2478ms)【2】集合方式foreach(一万条数

Python实现AVIF图片与其他图片格式间的批量转换
《Python实现AVIF图片与其他图片格式间的批量转换》这篇文章主要为大家详细介绍了如何使用Pillow库实现AVIF与其他格式的相互转换,即将AVIF转换为常见的格式,比如JPG或PNG,需要的小... 目录环境配置1.将单个 AVIF 图片转换为 JPG 和 PNG2.批量转换目录下所有 AVIF 图

详解如何通过Python批量转换图片为PDF
《详解如何通过Python批量转换图片为PDF》:本文主要介绍如何基于Python+Tkinter开发的图片批量转PDF工具,可以支持批量添加图片,拖拽等操作,感兴趣的小伙伴可以参考一下... 目录1. 概述2. 功能亮点2.1 主要功能2.2 界面设计3. 使用指南3.1 运行环境3.2 使用步骤4. 核
基于Python开发批量提取Excel图片的小工具
《基于Python开发批量提取Excel图片的小工具》这篇文章主要为大家详细介绍了如何使用Python中的openpyxl库开发一个小工具,可以实现批量提取Excel图片,有需要的小伙伴可以参考一下... 目前有一个需求,就是批量读取当前目录下所有文件夹里的Excel文件,去获取出Excel文件中的图片,并

Jmeter如何向数据库批量插入数据
《Jmeter如何向数据库批量插入数据》:本文主要介绍Jmeter如何向数据库批量插入数据方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录Jmeter向数据库批量插入数据Jmeter向mysql数据库中插入数据的入门操作接下来做一下各个元件的配置总结Jmete

Python批量调整Word文档中的字体、段落间距及格式
《Python批量调整Word文档中的字体、段落间距及格式》这篇文章主要为大家详细介绍了如何使用Python的docx库来批量处理Word文档,包括设置首行缩进、字体、字号、行间距、段落对齐方式等,需... 目录关键代码一级标题设置 正文设置完整代码运行结果最近关于批处理格式的问题我查了很多资料,但是都没

通过Python脚本批量复制并规范命名视频文件
《通过Python脚本批量复制并规范命名视频文件》本文介绍了如何通过Python脚本批量复制并规范命名视频文件,实现自动补齐数字编号、保留原始文件、智能识别有效文件等功能,听过代码示例介绍的非常详细,... 目录一、问题场景:杂乱的视频文件名二、完整解决方案三、关键技术解析1. 智能路径处理2. 精准文件名
Vue ElementUI中Upload组件批量上传的实现代码
《VueElementUI中Upload组件批量上传的实现代码》ElementUI中Upload组件批量上传通过获取upload组件的DOM、文件、上传地址和数据,封装uploadFiles方法,使... ElementUI中Upload组件如何批量上传首先就是upload组件 <el-upl
使用Python实现批量分割PDF文件
《使用Python实现批量分割PDF文件》这篇文章主要为大家详细介绍了如何使用Python进行批量分割PDF文件功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下... 目录一、架构设计二、代码实现三、批量分割PDF文件四、总结本文将介绍如何使用python进js行批量分割PDF文件的方法

Python在固定文件夹批量创建固定后缀的文件(方法详解)
《Python在固定文件夹批量创建固定后缀的文件(方法详解)》文章讲述了如何使用Python批量创建后缀为.md的文件夹,生成100个,代码中需要修改的路径、前缀和后缀名,并提供了注意事项和代码示例,... 目录1. python需求的任务2. Python代码的实现3. 代码修改的位置4. 运行结果5.
使用Python实现批量访问URL并解析XML响应功能
《使用Python实现批量访问URL并解析XML响应功能》在现代Web开发和数据抓取中,批量访问URL并解析响应内容是一个常见的需求,本文将详细介绍如何使用Python实现批量访问URL并解析XML响... 目录引言1. 背景与需求2. 工具方法实现2.1 单URL访问与解析代码实现代码说明2.2 示例调用

使用Python制作一个PDF批量加密工具
《使用Python制作一个PDF批量加密工具》PDF批量加密是一种保护PDF文件安全性的方法,通过为多个PDF文件设置相同的密码,防止未经授权的用户访问这些文件,下面我们来看看如何使用Python制... 目录1.简介2.运行效果3.相关源码1.简介一个python写的PDF批量加密工具。PDF批量加密

Python按条件批量删除TXT文件行工具
《Python按条件批量删除TXT文件行工具》这篇文章主要为大家详细介绍了Python如何实现按条件批量删除TXT文件中行的工具,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下... 目录1.简介2.运行效果3.相关源码1.简介一个由python编写android的可根据TXT文件按条件批

Java实现批量化操作Excel文件的示例代码
《Java实现批量化操作Excel文件的示例代码》在操作Excel的场景中,通常会有一些针对Excel的批量操作,这篇文章主要为大家详细介绍了如何使用GcExcel实现批量化操作Excel,感兴趣的可... 目录前言 | 问题背景什么是GcExcel场景1 批量导入Excel文件,并读取特定区域的数据场景2
Python脚本:对文件进行批量重命名
字符替换:批量对文件名中指定字符进行替换添加前缀:批量向原文件名添加前缀添加后缀:批量向原文件名添加后缀 import osdef Rename_CharReplace():#对文件名中某字符进行替换(已完结)re_dir = os.getcwd()re_list = os.listdir(re_dir)original_char = input('请输入你要替换的字符:')replace_ch
Python脚本:批量解压RAR文件
所需模块: os.getcwd() #获取脚本文件路径os.system() #执行系统命令 import os#source_dir = input("Please input in source_dir:")#unzip_dir = input("Please input in unzip_dir:") source_dir = os.
vcpkg子包路径批量获取
获取vcpkg 子包的路径,并拼接为set(CMAKE_PREFIX_PATH “拼接路径” ) import osdef find_directories_with_subdirs(root_dir):# 构建根目录下的 "packages" 文件夹路径root_packages_dir = os.path.join(root_dir, "packages")# 如果 "packages"
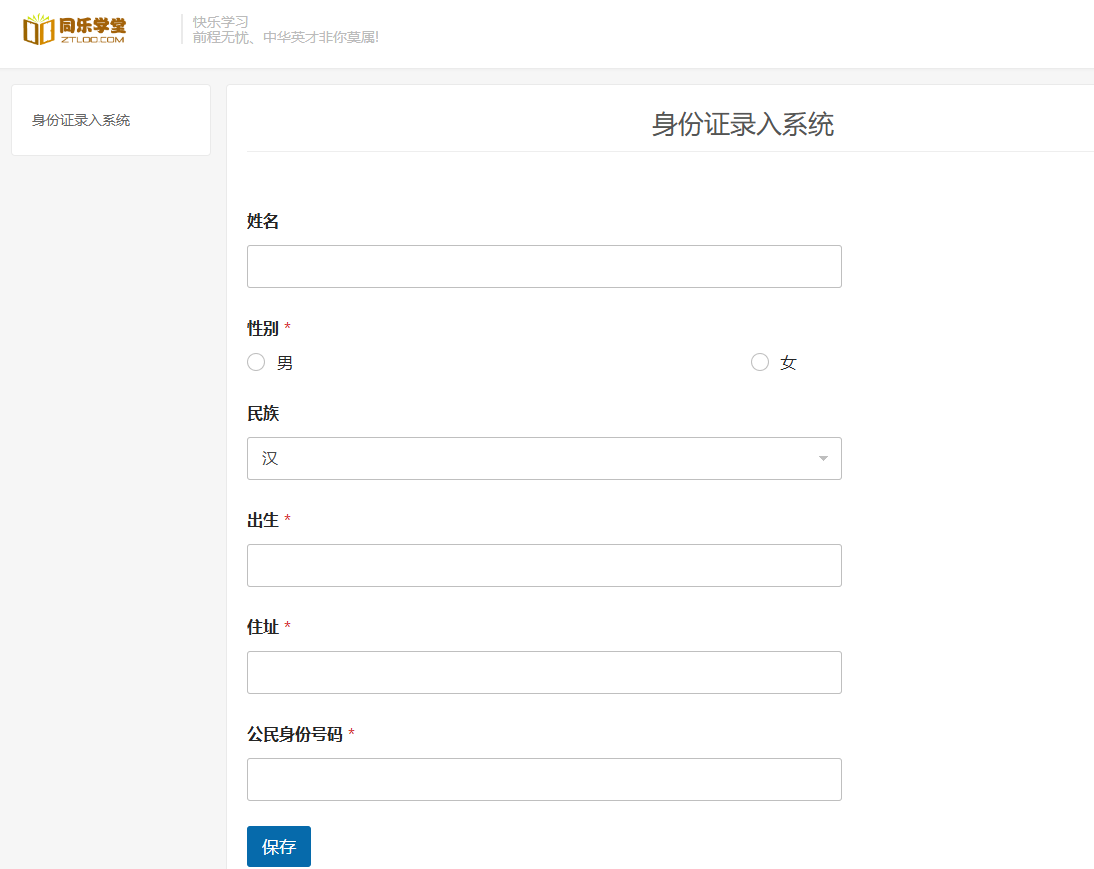
Python批量读取身份证信息录入系统和重命名
前言 大家好, 如果你对自动化处理身份证图片感兴趣,可以尝试以下操作:从身份证图片中快速提取信息,填入表格并提交到网页系统。如果你无法完成这个任务,我们将在“Python自动化办公2.0”课程中详细讲解实现整个过程。 实现过程概述: 模块与功能: re 模块:用于从 OCR 识别出的文本中提取所需的信息。 日期模块:计算年龄。 pandas:处理和操作表格数据。 PaddleOCR:百度的

分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节
1:MSSQL SQL语法篇: BULK INSERT [ database_name . [ schema_name ] . | schema_name . ] [ table_name | view_name ] FROM 'data_file' [ WITH ( [ [ , ] BATCHSIZE = batch_siz
C语言批量数据到动态二维数组
上一篇文章将文件读取放到静态创建的二维数组中,但是结合网络上感觉到今天的DT时代,这样批量大量读取一个上百行的数据,分配的内存是否可能因为大量的数据而产生溢出呢,最近一直研究里malloc函数,通过它来动态建立所需的二维数组,因此,通过文件操作和动态创建二维数组结合起来,将大量的数据动态的放入矩阵中,不知道这样的思想是否正确,下午把程序运行出来了,将程序贴上来,欢迎大家一起探讨:对于有规律的大数据
Mybatis Plus快速重构真批量sql入库操作
Mybatis快速重构真批量sql入库操作 基本思路 重构mybatis默认方法saveBatch和saveOrUpdateBatch的实现 基本步骤 真批量保存实现类InsertBatchMethod真批量更新实现类MysqlInsertOrUpdateBath注册InsertBatchMethod和MysqlInsertOrUpdateBath到EasySqlInjector注册Eas
批量生成编号(A~Z+3位流水编号)
/*** 批量生成编号* @param num* @param warehouseId* @return*/public synchronized List<String> generatCodeList(int num,long warehouseId){MesRack rack = this.getCurrentRack(warehouseId);String oldRackCode;Lis