本文主要是介绍C语言批量数据到动态二维数组,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇文章将文件读取放到静态创建的二维数组中,但是结合网络上感觉到今天的DT时代,这样批量大量读取一个上百行的数据,分配的内存是否可能因为大量的数据而产生溢出呢,最近一直研究里malloc函数,通过它来动态建立所需的二维数组,因此,通过文件操作和动态创建二维数组结合起来,将大量的数据动态的放入矩阵中,不知道这样的思想是否正确,下午把程序运行出来了,将程序贴上来,欢迎大家一起探讨:对于有规律的大数据txt文档如何高效而准确的读入数组或矩阵中呢???不吝赐教!!谢谢
程序:
#include<stdio.h>
#include<stdlib.h>
#define N 8 //8列
#define L 100 //100行
const char file_name[50] = "d:\\dat.txt";
int main(int argc, char* argv[])
{
int row,column;
double **data;
int index[N] = {0}; //二维数组列下标
double temp;
int i, j;
int count = 0; //计数器,记录已读出的浮点数
FILE *fp;
row=L;
column=N; //通过宏定义来确定行数、列数
if((fp=fopen(file_name, "rb")) == NULL)
{
printf("请确认文件(%s)是否存在!\n", file_name);
exit(1);
}
data=(double **)malloc(row*sizeof(double *));
for(i=0;i<row;i++)
data[i]=(double *)malloc(column*sizeof(double)); //动态二维数组的建立(行列限制内存大小)
将txt数据读入该动态二维数组///
while(1==fscanf(fp, "%lf", &temp)) {
data[(index[count%N])++][count%N] = temp;
count++;
}
显示///
for(i=0;i<row;i++)
{ printf("第%d行元素为: \n", i+1);
for(j=0;j<column;j++)
{
//data[i][j]=i*row+j*0.01;
printf("%5.3f ",data[i][j]); //动态数组的成员都可以用正常的数组下标 data[i][j]
}
printf("\n");
}
free(data); //释放内存空间,重要,但是好像写的有问题的
return 0;
}
截个效果图上来吧:
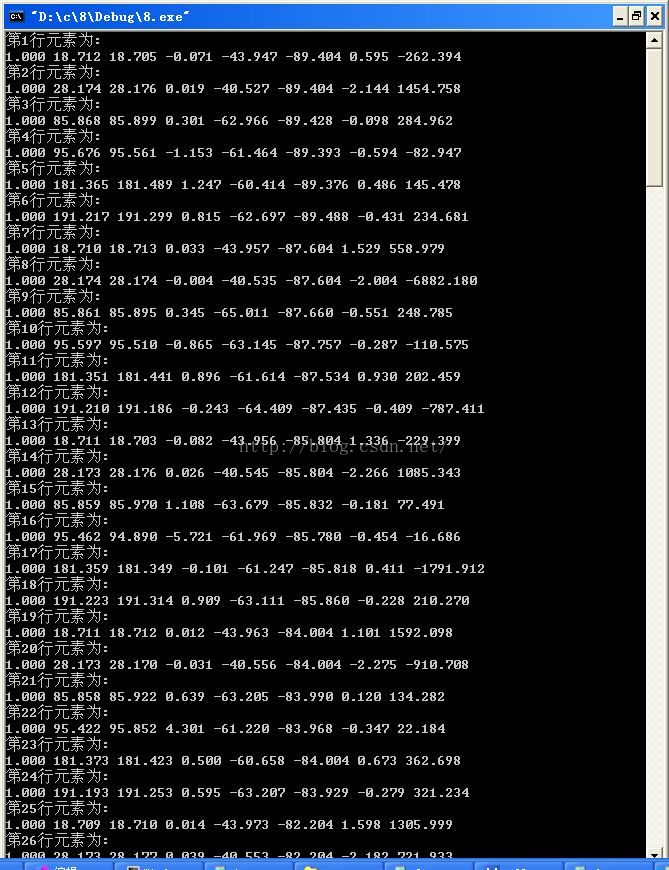
这篇关于C语言批量数据到动态二维数组的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







